codeforces
LAMBDA
DOM型XSS
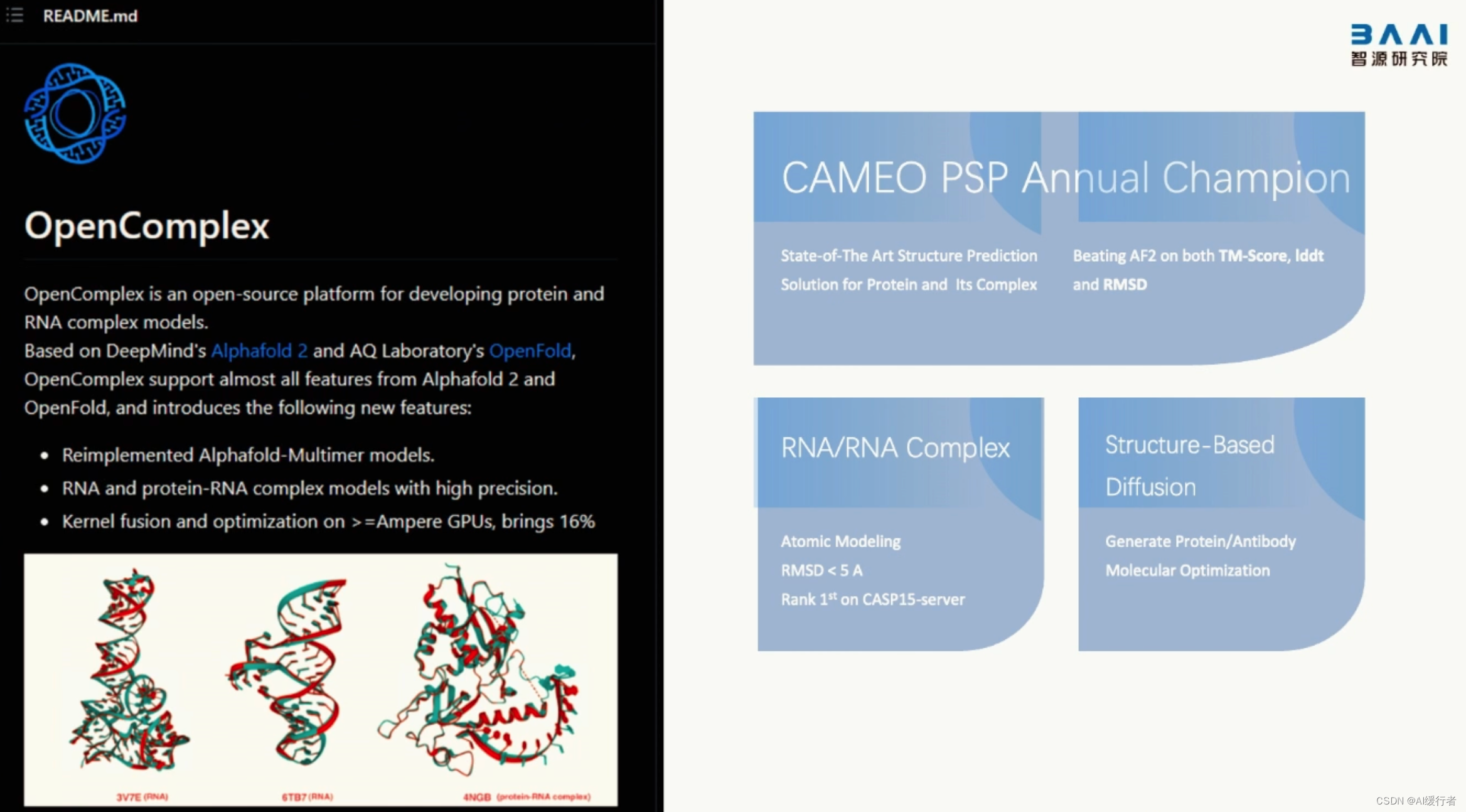
AppCube
插件的定义和使用
系统错误
Fiori
度中心性
特征向量中心性
NISCTF
文档协作
ACK
事件相关定位
java-ee
基础语法
heartbeating
天鹰算法优化随机森林多分类
对比学习
junit
proteus
大模型
2024/4/11 17:17:55
Prompt Engineering | 对话聊天prompt
😄 使用LLM来搭建一个定制的聊天机器人,只需要很少的工作量。 ⭐ 本文将讲解如何利用聊天格式与个性化或专门针对特兹那个任务或行为的聊天机器人进行多伦对话。 文章目录 1、提供对话的早期部分,引导模型继续聊天2、示例:构建一个…
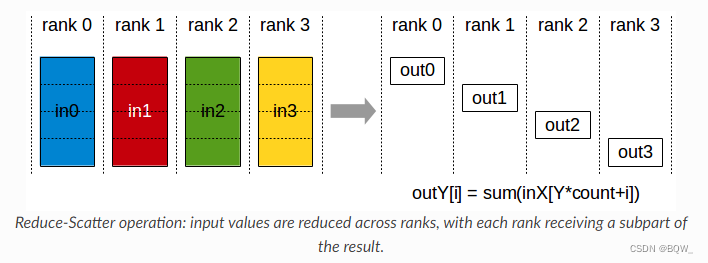
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
相关博客 【深度学习】【分布式训练】Collective通信操作及Pytorch示例 【自然语言处理】【大模型】大语言模型BLOOM推理工具测试 【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型 【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介…

【2023 CSIG垂直领域大模型】大模型时代,如何完成IDP智能文档处理领域的OCR大一统?
目录 一、像素级OCR统一模型:UPOCR1.1、为什么提出UPOCR?1.2、UPOCR是什么?1.2.1、Unified Paradigm 统一范式1.2.2、Unified Architecture统一架构1.2.3、Unified Training Strategy 统一训练策略 1.3、UPOCR效果如何? 二、OCR大一统模型前…

部署大模型API的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

2023年8月第3周大模型荟萃
2023年8月第3周大模型荟萃
2023.8.22版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
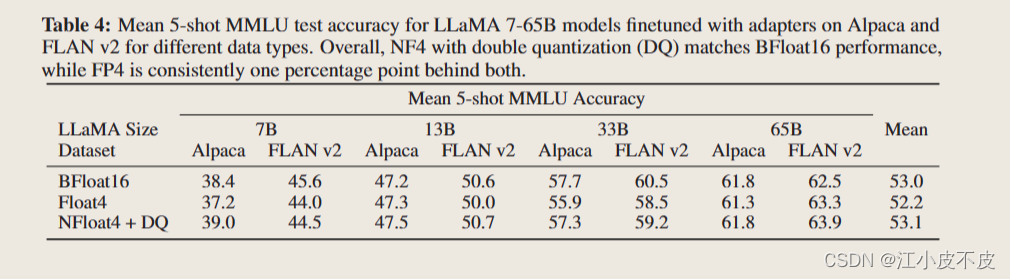
1、LLM-Adapters:可将多种适配器集成到大语言模型
来自新加坡科技设计大学和新加坡管理大学的研究人员发布了一篇题为《LLM-Adapters: An …

LAMA AutoPrompt
LAMA LAMA: Language Models as Knowledge Bases? 2019.9 Github: GitHub - facebookresearch/LAMA: LAnguage Model Analysis 任务:NLU(实事抽取) prompt: cloze Hand Craft Prompt 核心:不经过微调的Bert在知识抽取和开放…
通过制作llama_cpp的docker镜像在内网离线部署运行大模型
对于机器在内网,无法连接互联网的服务器来说,想要部署体验开源的大模型,需要拷贝各种依赖文件进行环境搭建难度较大,本文介绍如何通过制作docker镜像的方式,通过llama.cpp实现量化大模型的快速内网部署体验。 一、llam…
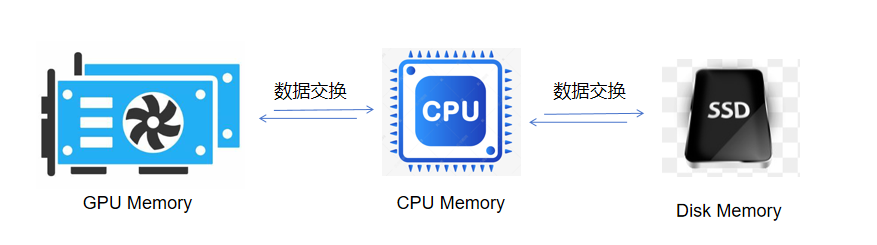
极智AI | Colossal-AI高效异构内存管理系统
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来介绍一下 Colossal-AI高效异构内存管理系统。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 首先需要了解一下异构内存中的…

GPT火了一年了,你还不懂大语言模型吗?
本文主要介绍大语言的基本原理、以及应用场景和对未来的展望,侧重应用而非技术原理。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:漫谈LLMs带来的AIGC浪潮 🎀CSDN主页 发狂的小花 &#…

小白也能看懂的国内外 AI 芯片概述
随着越来越多的企业将人工智能应用于其产品,AI芯片需求快速增长,市场规模增长显著。因此,本文主要针对目前市场上的AI芯片厂商及其产品进行简要概述。
简介
AI芯片也被称为AI加速器或计算卡,从广义上讲只要能够运行人工智能算法…

【AI视野·今日NLP 自然语言处理论文速览 第六十九期】Wed, 3 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 3 Jan 2024 Totally 24 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction Authors Zaratiana Ur…
StreamingLLM - 处理无限长度的输入
文章目录 关于 StreamingLLM使用关于 StreamingLLM
Efficient Streaming Language Models with Attention Sinks GitHub : https://github.com/mit-han-lab/streaming-llm论文:https://arxiv.org/abs/2309.17453在流媒体应用程序(如多轮对话)中 部署大型语言模型(LLM)是迫…
大模型的实践应用12-GPT4框架介绍与详细训练过程,以及并行性的策略,专家权衡机制,推理权衡等内容
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用12-GPT4框架介绍与详细训练过程,以及并行性的策略,专家权衡机制,推理权衡等内容。2023年3月14日,OpenAI发布GPT-4,然而GPT-4的框架没有公开,OpenAI之所以不公开GPT-4的架构,并不是因为存在对人类的潜在威胁,而是…

文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback 1. 文章简介2. 方法介绍 1. 整体方法说明 3. 实验结果 1. RLHF vs RLAIF2. Prompt的影响3. Self-Consistency4. Labeler Size的影响5. 标注数据的影响 4. 总结 & 思考 文…
Prompt Engineering | 推断prompt(一句prompt解锁多个nlp任务!)
😄 大模型大一统的时代来临了,各nlp任务不需要单独准备一份带标签的数据进行有监督训练,而是只需要一句prompt便可以解决各类nlp任务,如情感分类、情感类型识别、实体抽取等,极大地减轻了工作量!
⭐ 比如&…
斯坦福发布 最新 GPT 模型排行榜 AlpacaEval
文章目录 📌提炼❓什么是 AlpacaEval🔎AlpacaEval 排行榜 包含的 测试 模型 和数据💯在不同的测试集上各个大模型的能力评分🚀AlpacaEval Leaderboard 大模型的能力综合评分💼 普遍国内白领 如何快速应用 大模型&#…

用通俗易懂的方式讲解大模型:使用 LangChain 封装自定义的 LLM,太棒了
Langchain 默认使用 OpenAI 的 LLM(大语言模型)来进行文本推理工作,但主要的问题就是数据的安全性,跟 OpenAI LLM 交互的数据都会上传到 OpenAI 的服务器。
企业内部如果想要使用 LangChain 来构建应用,那最好是让 La…
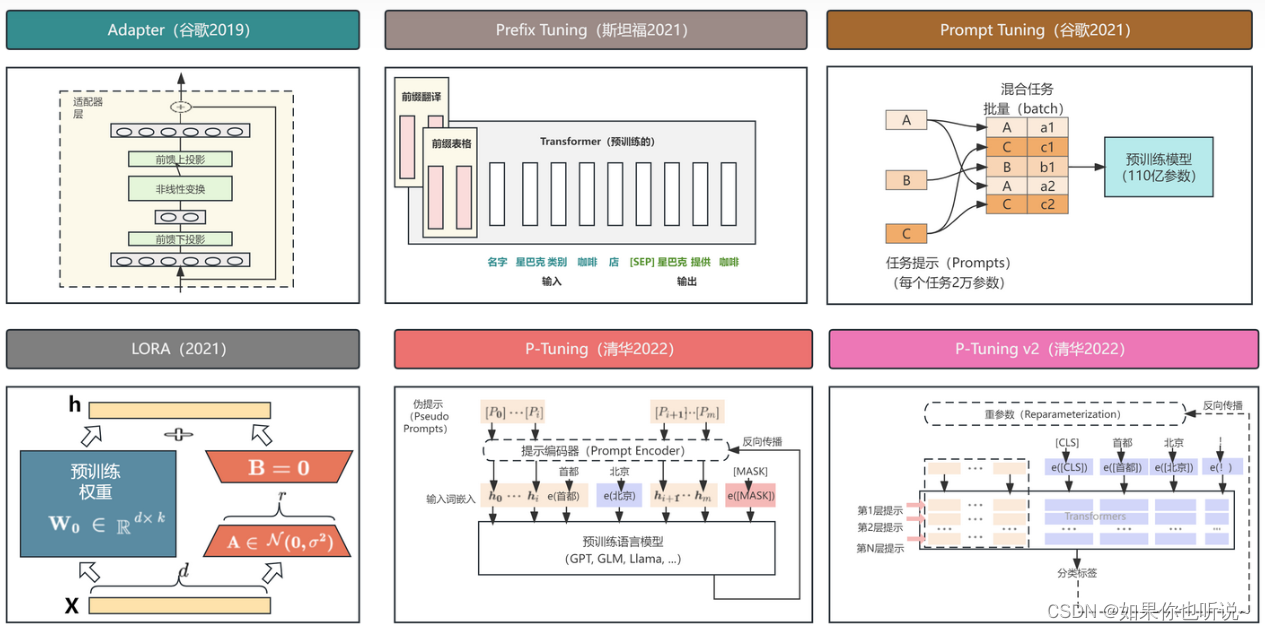
大模型微调总结1-总览
背景
2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来…
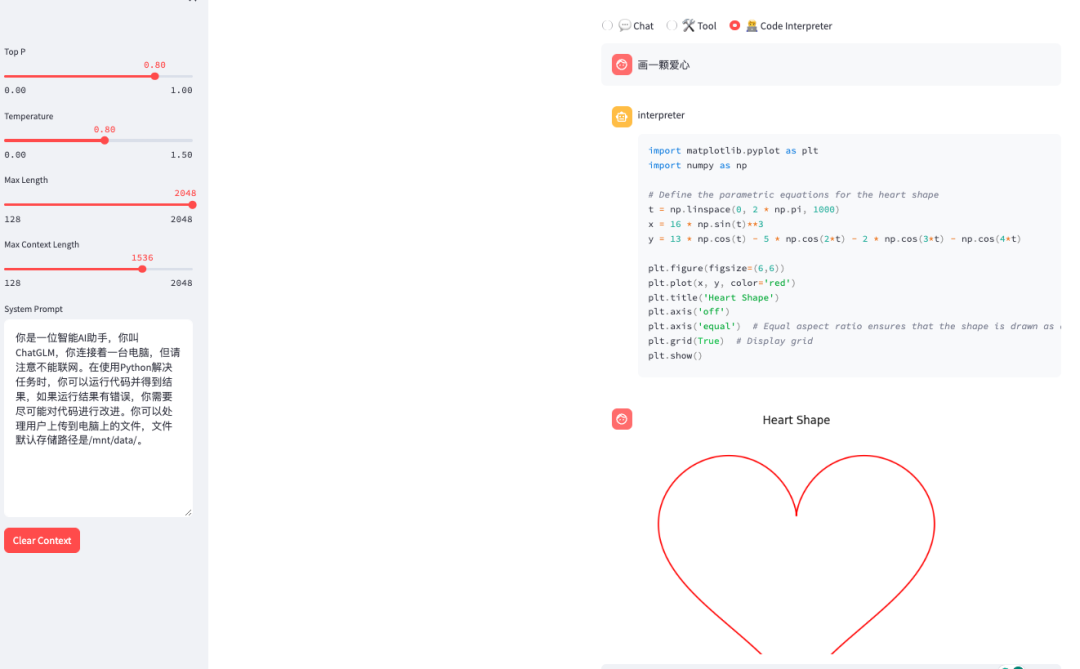
用通俗易懂的方式讲解大模型:在 CPU 服务器上部署 ChatGLM3-6B 模型
大语言模型(LLM)的量化技术可以大大降低 LLM 部署所需的计算资源,模型量化后可以将 LLM 的显存使用量降低数倍,甚至可以将 LLM 转换为完全无需显存的模型,这对于 LLM 的推广使用来说是非常有吸引力的。
本文将介绍如何…

百度每天20%新增代码由AI生成,Comate SaaS服务8000家客户 采纳率超40%
12月28日,由深度学习技术及应用国家工程研究中心主办的WAVE SUMMIT深度学习开发者大会2023在北京召开。百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰现场公布了飞桨文心五载十届最新生态成果,文心一言最新用户规模破1亿,截…
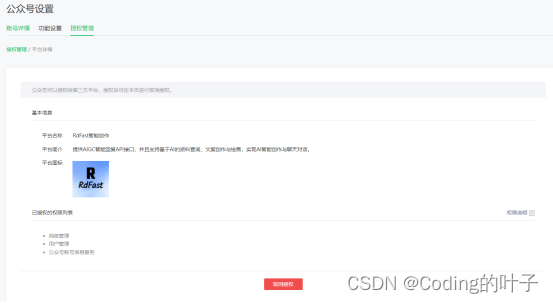
微信公众号快速接入大模型
今天找到一个可以快速将大模型接入公众号的方法,现在跟大家分享一下。 如何让微信公众号接入大模型文案创作能力,实现类似ChatGPT文案创作功能。方法其实很简单,只需打开地址“http://www.botaigc.cn:8900/mpauth”,用微信扫码即可…

自监督DINO论文笔记
论文名称:Emerging Properties in Self-Supervised Vision Transformers 发表时间:CVPR2021 作者及组织: Facebook AI Research GitHub:https://github.com/facebookresearch/dino/tree/main
问题与贡献
作者认为self-supervise…
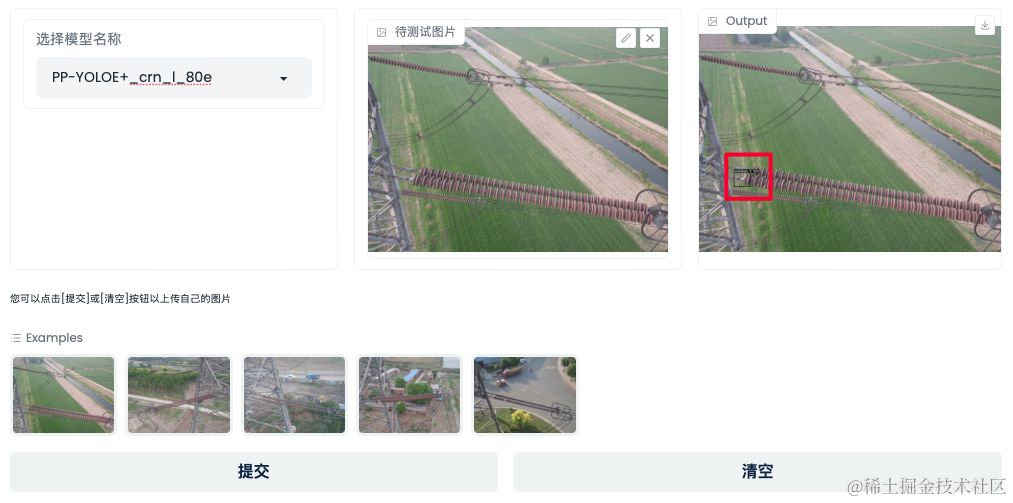
PaddleX解决分类、检测两大场景问题?实战精讲教程来了!
AI技术加速数字化进程,从制造、交通、能源等基础行业,到医疗、城市、零售、家居等与人们日常生活息息相关的行业,AI技术推动了数字化变革,也不断赋能于千行百业,但产业落地实践中依然面临着数据、算法等诸多困难。为了…
大模型从入门到应用——LangChain:代理(Agents)-[工具(Tools):人工确认工具验证和Tools作为OpenAI函数]
分类目录:《大模型从入门到应用》总目录
LangChain系列文章:
基础知识快速入门 安装与环境配置链(Chains)、代理(Agent:)和记忆(Memory)快速开发聊天模型 模型(Models&…
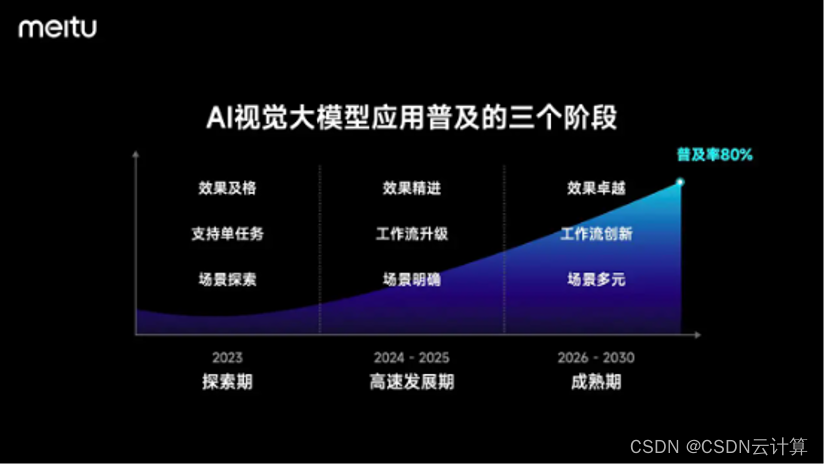
成立 15 年的美图分享,AI 视觉大模型的核心能力是什么?
出品 | CSDN 云计算 国民级美颜修图软件美图秀秀,从移动互联网时代火到现在,而它背后的美图公司也走过了十五年的发展,旗下拥有众多的专业影像与设计产品。最近,美图公司举办 15 周年生日会,生日会上美图还发布了自研 …
通往AGI的大模型MultiAgent的RL是对的但HF有上限
OpenAI高管Mira Murati周三告诉员工,一封关于AI取得突破的信件促使董事会采取了解雇行动。一位消息人士透露,OpenAI在Q*项目上取得了进展,内部人士认为这可能是OpenAI在超级智能领域的突破。这名消息人士称,虽然Q*的数学成绩只是小…
大模型的实践应用2-基于BERT模型训练医疗智能诊断问答的运用研究,协助医生进行疾病诊断
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用2-基于BERT模型训练医疗智能诊断问答的运用研究,协助医生进行疾病诊断。医疗大模型通过收集和分析大量的医学数据和临床信息,能够协助医生进行疾病诊断、制定治疗方案和评估预后等任务。利用医疗大模型,可以帮助医生…

论文速览 Arxiv 2023 | DMV3D: 单阶段3D生成方法
注1:本文系“最新论文速览”系列之一,致力于简洁清晰地介绍、解读最新的顶会/顶刊论文 论文速览 Arxiv 2023 | DMV3D: DENOISING MULTI-VIEW DIFFUSION USING 3D LARGE RECONSTRUCTION MODEL 使用3D大重建模型来去噪多视图扩散 论文原文:https://arxiv.org/pdf/2311.09217.pdf…

多款大模型向公众开放,百模大战再升级?
作为一种使用大量文本数据训练的深度学习模型,大模型可以生成自然语言文本或理解语言文本的含义,是通向人工智能的一条重要途径。大模型可以应用于各种机器学习任务,包括自然语言处理、计算机视觉、语音识别、机器翻译、推荐系统、强化学习等…
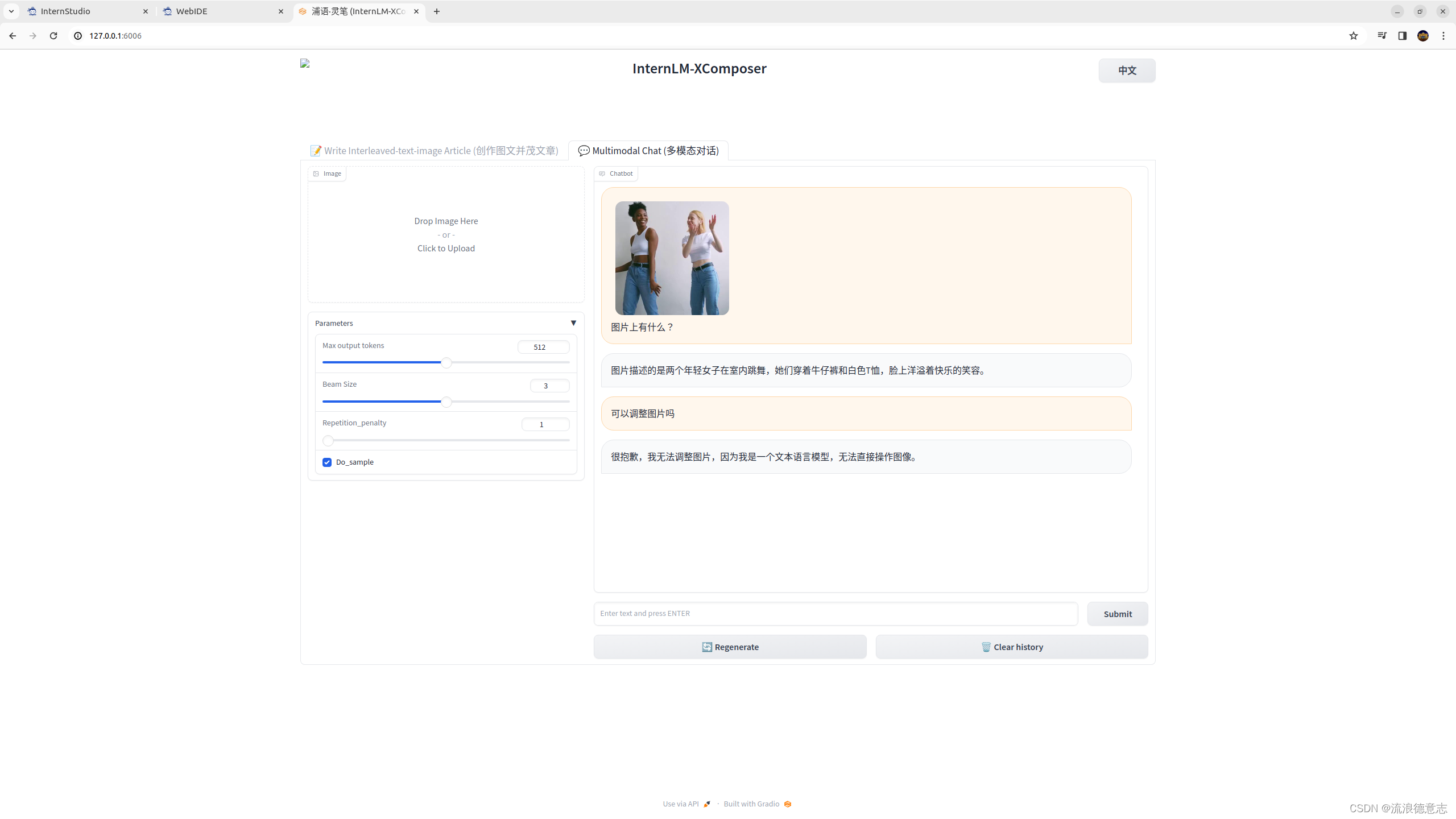
大模型实战营Day2 作业
基础作业
1 使用 InternLM-Chat-7B 模型生成 300 字的小故事 2 熟悉 hugging face 下载功能,使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地 进阶作业
1 完成浦语灵笔的图文理解及创作部署 2 完成 Lagent 工具调用 Demo…
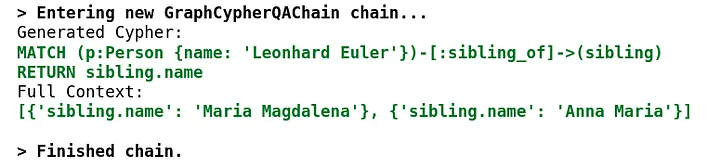
使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
目前基于大模型的信息检索有两种方法,一种是基于微调的方法,一种是基于 RAG 的方法。
信息检索和知识提取是一个不断发展的领域,随着大型语言模型(LLM)和知识图的出现,这一领域发生了显着的变化࿰…
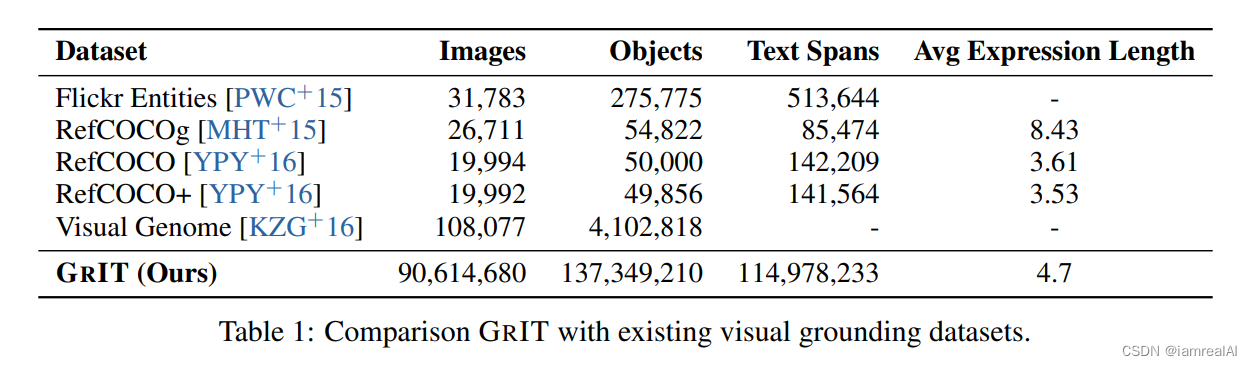
多模态大模型训练数据集汇总介绍
RefCOCO、RefCOCO、RefCOCOg 这三个是从MS-COCO中选取图像得到的数据集,数据集中对所有的 phrase 都有 bbox 的标注。
RefCOCO 共有19,994幅图像,包含142,209个引用表达式,包含50,000个对象实例。RefCOCO 共有19,992幅图像,包含1…
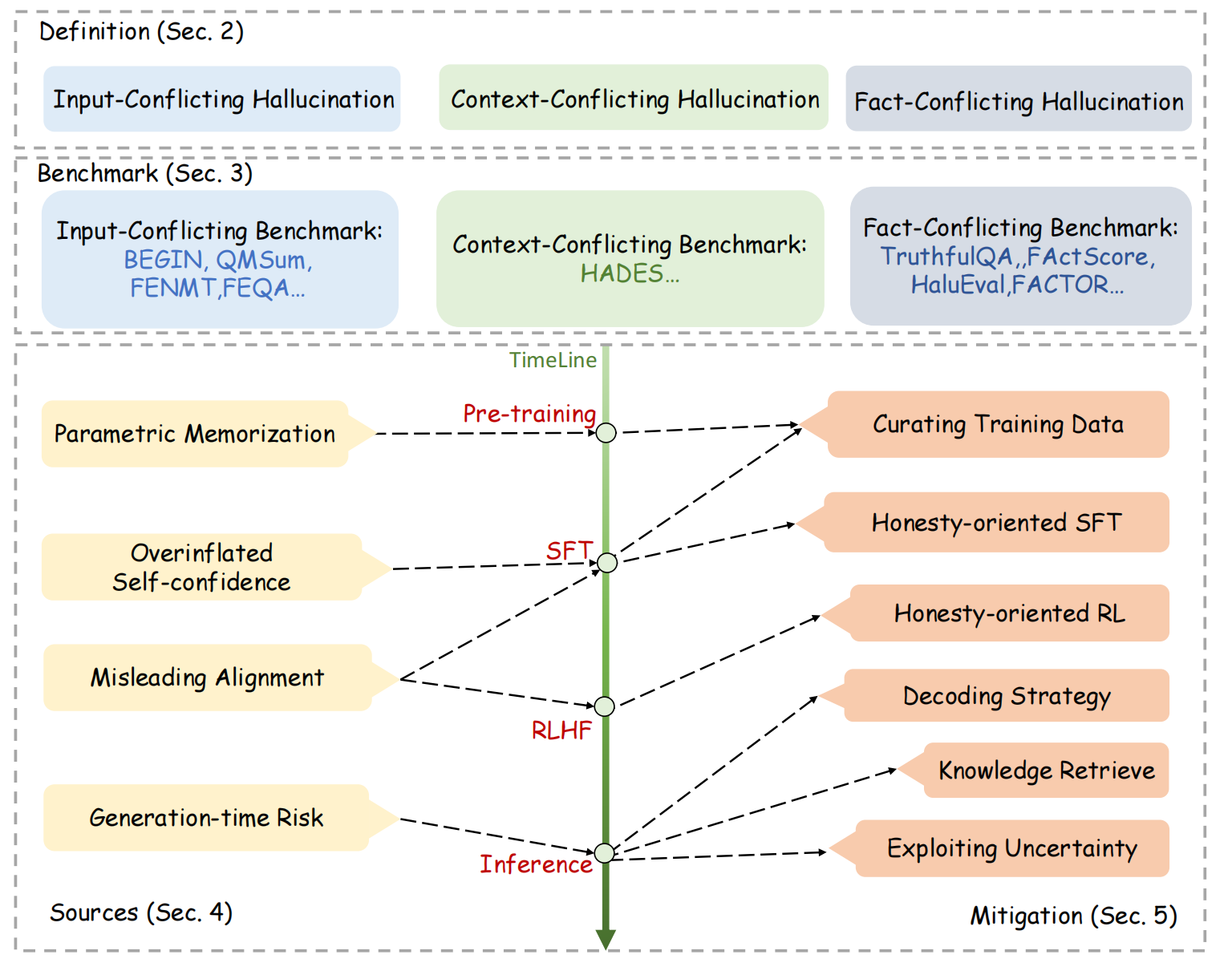
【LLM】大模型幻觉问题的原因和缓解方法
文章目录 一、幻觉定义二、幻觉的可控因素二、幻觉的原因1. 数据层面2. 模型层面 三、解决方法1. 数据层面2. 模型层面(1)模型结构(2)训练方式 3. pretrain、sft、rlhf、inference(1)pretrain(2…
2023年6月第2周大模型荟萃
2023年6月第2周大模型荟萃
2023.6.12版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、百度推出代码助手 Comate
6 月 6 日,在文心大模型成都技术交流会上,百度智能云推出 Comate 代码助手,并正式开放…

【AI视野·今日Robot 机器人论文速览 第七十五期】Thu, 11 Jan 2024
AI视野今日CS.Robotics 机器人学论文速览 Thu, 11 Jan 2024 Totally 16 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers
Analytical Model and Experimental Testing of the SoftFoot: an Adaptive Robot Foot for Walking over Obstacles and Irre…
『2023北京智源大会』开幕式以及基础模型前沿技术论坛
『2023北京智源大会』开幕式以及基础模型前沿技术论坛 文章目录 一. 黄铁军丨智源研究院院长1. 大语言模型2. 大语言模型评测体系FlagEval3. 大语言模型生态(软硬件)4. 三大路线通向 AGI(另外2条路径) 二. Towards Machines that can Learn, Reason, and Plan(杨立昆丨图灵奖得…

大模型元年压轴盛会定档12月28日,第十届WAVE SUMMIT即将启航
文章目录 1. 前言2. WAVE SUMMIT五载十届,AI开发者热血正当时3. 酷炫前沿、星河共聚!大模型技术生态发展正当时 1. 前言 回望2023年,大语言模型或许将是科技史上最浓墨重彩的一笔。从技术、产业到生态,大语言模型在突飞猛进中加速…
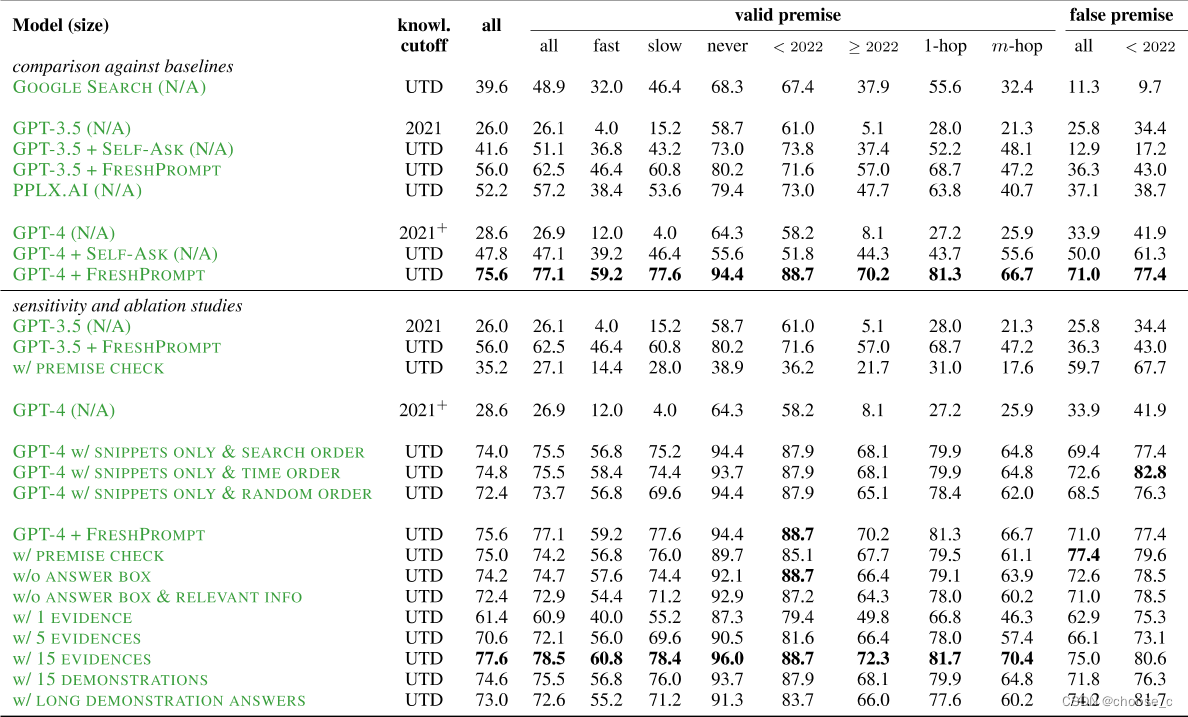
增强LLM:使用搜索引擎缓解大模型幻觉问题
论文题目:FRESHLLMS:REFRESHING LARGE LANGUAGE MODELS WITH SEARCH ENGINE AUGMENTATION
论文地址:https://arxiv.org/pdf/2310.03214.pdf
论文由Google、University of Massachusetts Amherst、OpenAI联合发布。 大部分大语言模型只会训练一次&#…

简单两步实现离线部署ChatGPT,ChatGPT平替版,无需GPU离线搭建ChatGPT
文末附主程序安装包和大模型参数文件~ 演示效果如下图所示: 一、使用方法
软件主要分为两个部分:GPT4ALL软件主体(主程序)模型参数(离线模型),如果使用API Key的话则不需要下载模型参数。
可以…

ChatGPT 的 Text Completion
该章节我们来学习一下 “Text Completion” ,也就是 “文本完成” 。“Text Completion” 并不是一种模型,而是指模型能够根据上下文自动完成缺失的文本部分,生成完整的文本。 ⭐ Text Completion 的介绍
Text Completion 也称为文本自动补全…
No module named ‘pytorch_lightning.utilities.distributed‘
在按照stable- diffusion中,需要安装很多依赖。如果版本不对,则不能成功运行,标题的问题就是如此。
相关参考:stable- diffusion V1效果咋样呢?V2呢?安装成功记录。
解决方案: pip install py…
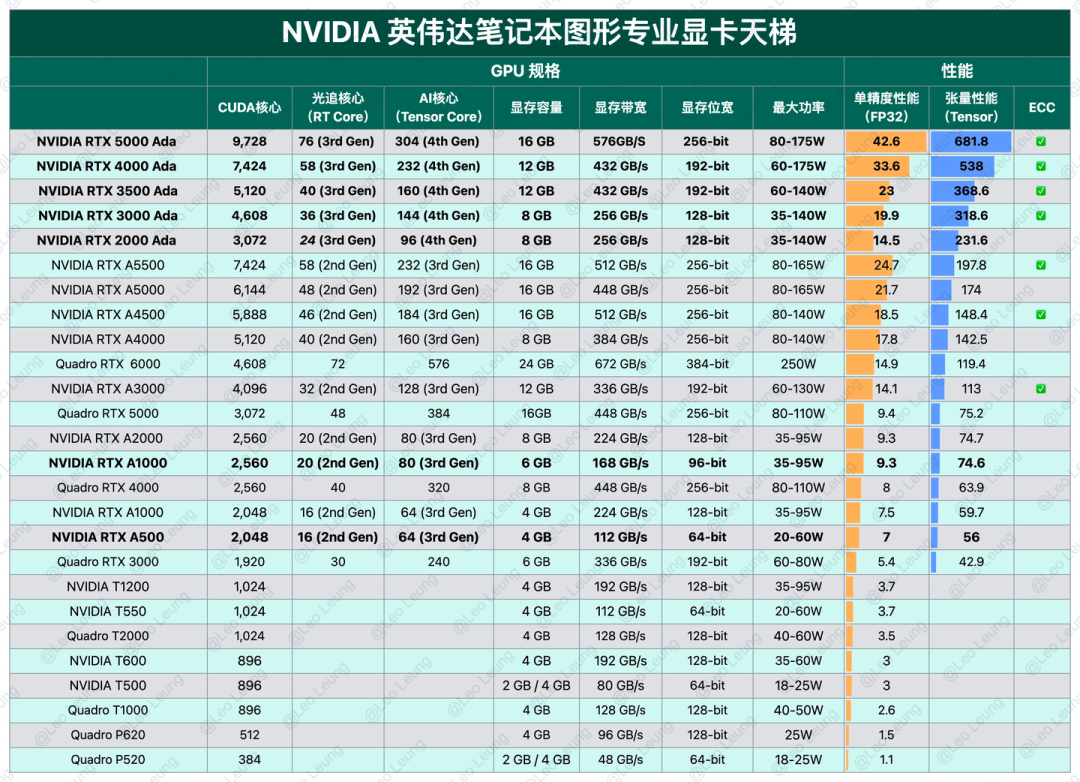
大模型必备算力:CPUGPU天梯图(2023年最新版)
在当今计算机世界,CPU、GPU和显卡的性能成为了衡量计算机性能的重要指标。今天深入了解CPU、GPU和显卡天梯图。
首先,CPU作为计算机的大脑,负责处理各种任务。它的性能主要由核心数、主频和缓存大小决定。其中,核心数和主频决定了…
用通俗易懂的方式讲解:使用 Mistral-7B 和 Langchain 搭建基于PDF文件的聊天机器人
在本文中,使用LangChain、HuggingFaceEmbeddings和HuggingFace的Mistral-7B LLM创建一个简单的Python程序,可以从任何pdf文件中回答问题。
一、LangChain简介
LangChain是一个在语言模型之上开发上下文感知应用程序的框架。LangChain使用带prompt和few…
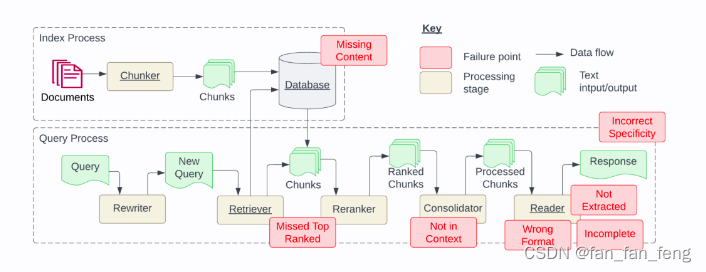
RAG应用-七个最常见的故障点
近日,国外研究者发布了一篇论文《Seven Failure Points When Engineering a Retrieval Augmented Generation System》,探讨了在实际工程落地RAG应用过程中容易出的七类问题。
论文地址:https://arxiv.org/pdf/2401.05856.pdf 一、丢失内容&…
大模型学习之书生·浦语大模型笔记汇总
笔记汇总地址:
大模型学习之书生浦语大模型1——全链路开源体系大模型学习之书生浦语大模型2——趣味Demo大模型学习之书生浦语大模型3——基于InternLM和LangChain搭建知识库大模型学习之书生浦语大模型4——基于Xtuner大模型微调实战大模型学习之书生浦语大模型5…

用通俗易懂的方式讲解:使用 MongoDB 和 Langchain 构建生成型AI聊天机器人
想象一下:你收到了你梦寐以求的礼物:一台非凡的时光机,可以将你带到任何地方、任何时候。
你只有10分钟让它运行,否则它将消失。你拥有一份2000页的PDF,详细介绍了关于这台时光机的一切:它的历史、创造者、…
使用tesla gpu 加速大模型,ffmpeg,unity 和 UE等二三维应用
我们知道tesla gpu 没有显示器接口,那么在windows中怎么使用加速unity ue这种三维编辑器呢,答案就是改变注册表来加速相应的三维渲染程序.
1 tesla gpu p40 p100 加速
在windows中使用regedit 来改变 核显配置, 让p100 p40 等等显卡通过核显…

stable-diffusion真的好用吗?
hi,各位大佬,今天尝试下diffusion大模型,也是CV领域的GPT,但需要prompt,我给了prompt结果并不咋滴,如下示例,并附代码及参考link
1、img2img
代码实现:
import torch
from PIL im…
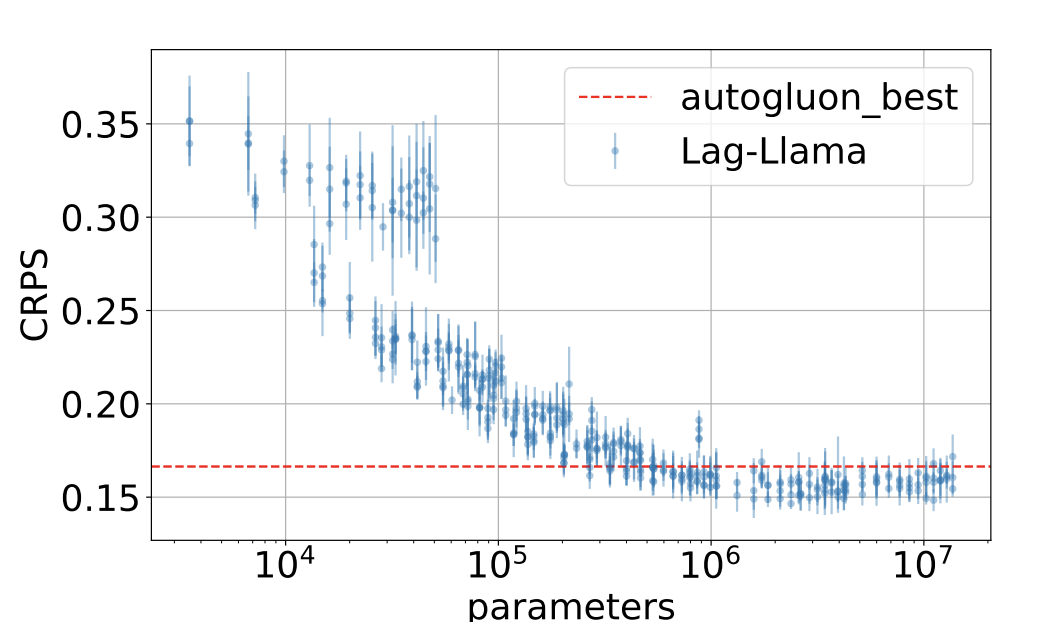
Lag-Llama:基于 LlaMa 的单变量时序预测基础模型
文章构建了一个通用单变量概率时间预测模型 Lag-Llama,在来自Monash Time Series库中的大量时序数据上进行了训练,并表现出良好的零样本预测能力。在介绍Lag-Llama之前,这里简单说明什么是概率时间预测模型。概率预测问题是指基于历史窗口内的…

DeepMind发布新模型Mirasol3B:更高效处理音频、视频数据
Google DeepMind日前悄然宣布了其人工智能研究的重大进展,推出了一款名为“Mirasol3B”的新型自回归模型,旨在提升对长视频输入的理解能力。该新模型展示了一种颠覆性的多模态学习方法,以更综合和高效的方式处理音频、视频和文本数据。 Googl…
LINGO-1 - 自动驾驶的 视觉语言动作模型
文章目录 LINGO-1: Exploring Natural Language for Autonomous Driving https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/ 【LINGO-1:将自然语言应用于无人驾驶增强学习和可解释性】
探索将视觉、语言和行动相结合的视觉语言行动模型(VLAM)…
大模型-你知道大模型是什么吗
背景
在云栖大会门口看到大妈招女婿都需要大模型的背景了,不论真假,大模型时代是到来了。以前对人工智能不太了解,现在各行各业都在争先接入大模型,使用AI迭代自己的产品。再不学习学习大模型,真的是要OUT了。所以决心…

诚邀莅临,共商发展丨“交汇未来”行业大模型高峰论坛
今年以来,以ChatGPT为典型代表的大模型在全球数字科技界引起极大关注,其强大的数据处理能力和泛化性能使得其在各个领域都有广泛的应用前景,驱动千行百业的数字化转型升级,成为新型工业化和实体经济的重要推动力,进而带…

工业异常检测AnomalyGPT-训练试跑及问题解决
写在前面,AnomalyGPT训练试跑遇到的坑大部分好解决,只有在保存模型失败的地方卡了一天才解决,本来是个小问题,昨天没解决的时候尝试放弃在单卡的4090上训练,但换一台机器又遇到了新的问题,最后决定还是回来…
教你用通义千问只要五步让千年的兵马俑跳上现代的科目三?
教你用五步让千年的兵马俑跳上现代的舞蹈科目三? 上面这个“科目三”的视频,只用了一张我上月去西安拍的兵马俑照片生成的。 使用通义千问,只要5步就能它舞动起来,跳上现在流行的“科目三”舞蹈。
全民舞王
第1步
打开通义千问…

FinGPT:金融垂类大模型架构
Overview 动机 架构 底座模型: Llama2Chatglm2 Lora训练
技术路径 自动收集数据并整理 指令微调 舆情分析 搜新闻然后相似搜索
检索增强架构 智能投顾 Hugging face 地址 学术成果及未来方向 参考资料

【网安专题10.11】代码大模型的应用及其安全性研究
代码大模型的应用及其安全性研究 写在最前面一些想法大型模型输出格式不受控制的解决方法 大模型介绍(很有意思)GPT 模型家族的发展Chatgpt优点缺点GPT4 其他模型补充:self-instruct合成数据 Code Llama 代码大模型的应用(第一次理…
![[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--强化学习、模仿学习、机器人](https://img-blog.csdnimg.cn/direct/94a059d47b7345caab5f15c18a675253.jpeg#pic_center)
[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--强化学习、模仿学习、机器人
专属领域论文订阅 关注{晓理紫},每日更新论文,如感兴趣,请转发给有需要的同学,谢谢支持 如果你感觉对你有所帮助,请关注我,每日准时为你推送最新论文。 为了答谢各位网友的支持,从今日起免费为3…
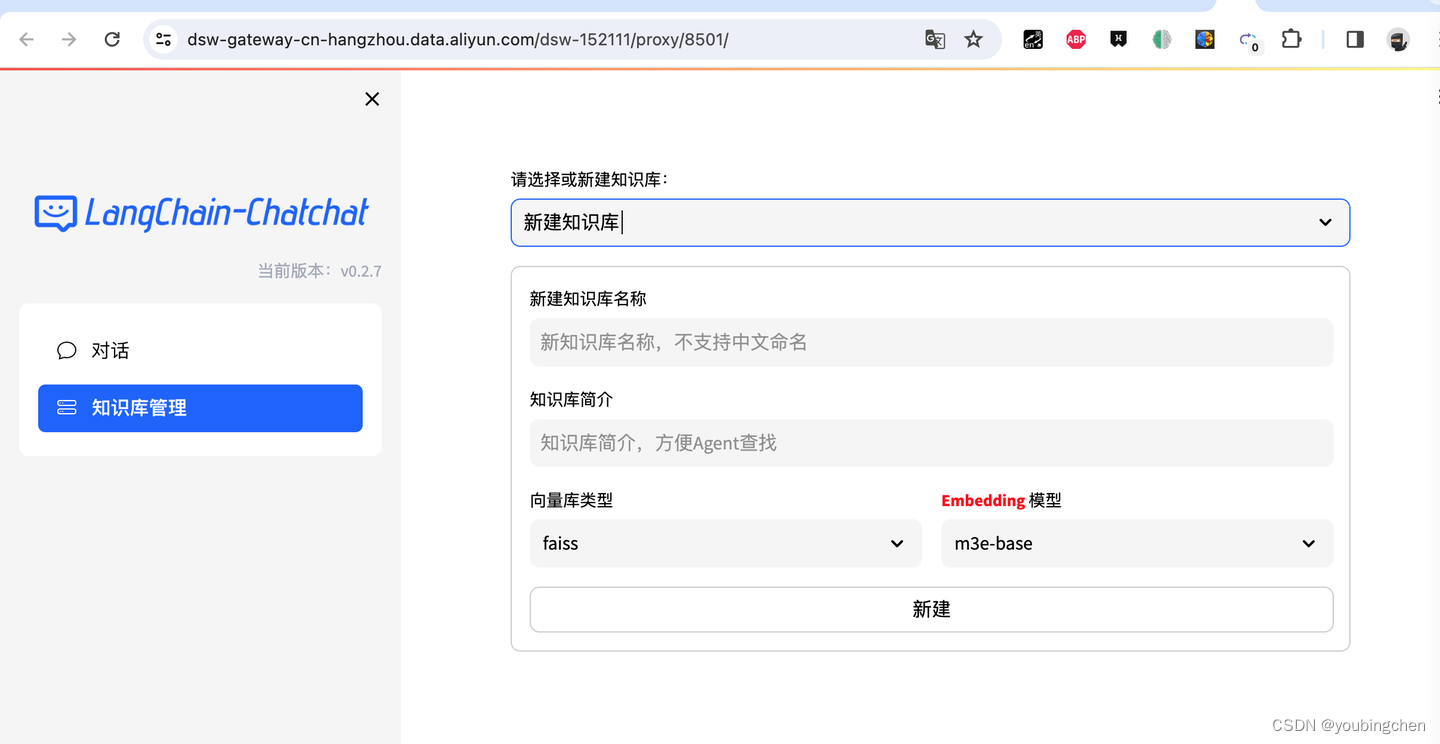
平民如何体验一把大模型知识库
背景
随着openai发布的chatgpt,各界掀起大模型热. 微软、谷歌、百度、阿里等大厂纷纷拥抱人工智能, 表示人工智能将是下一个风口.确实, chatgpt的表现确实出乎大部分的意料之外,网上也不断流传出来,chatgpt未来会替换很多白领.作为一名普通的程序员,觉得非常有必要随波逐流一下…
2.3 调用智谱 API
调用智谱 API 1 申请调用权限2 调用智谱 AI API3 使用 LangChain 调用智谱 AI参考: 智谱 AI 是由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。公司合作研发了双语千亿级超大规模预训练模型 GLM-130B,并构建了…
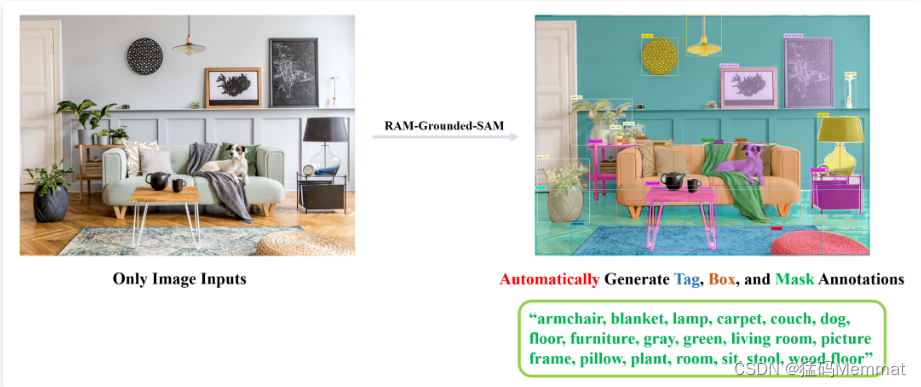
14k字综述视觉大模型
目录 0.导读1.背景介绍1.1基础架构1.2目标函数1.2.1对比式学习1.2.2生成式学习1.3预训练1.3.1预训练数据集1.3.2微调1.3.3提示工程2.基于文本提示的基础模型2.1基于对比学习的方法2.1.1基于通用模型的对比方法2.1.2基于视觉定位基础模型的方法2.2基于生成式的方法2.3基于对比学…
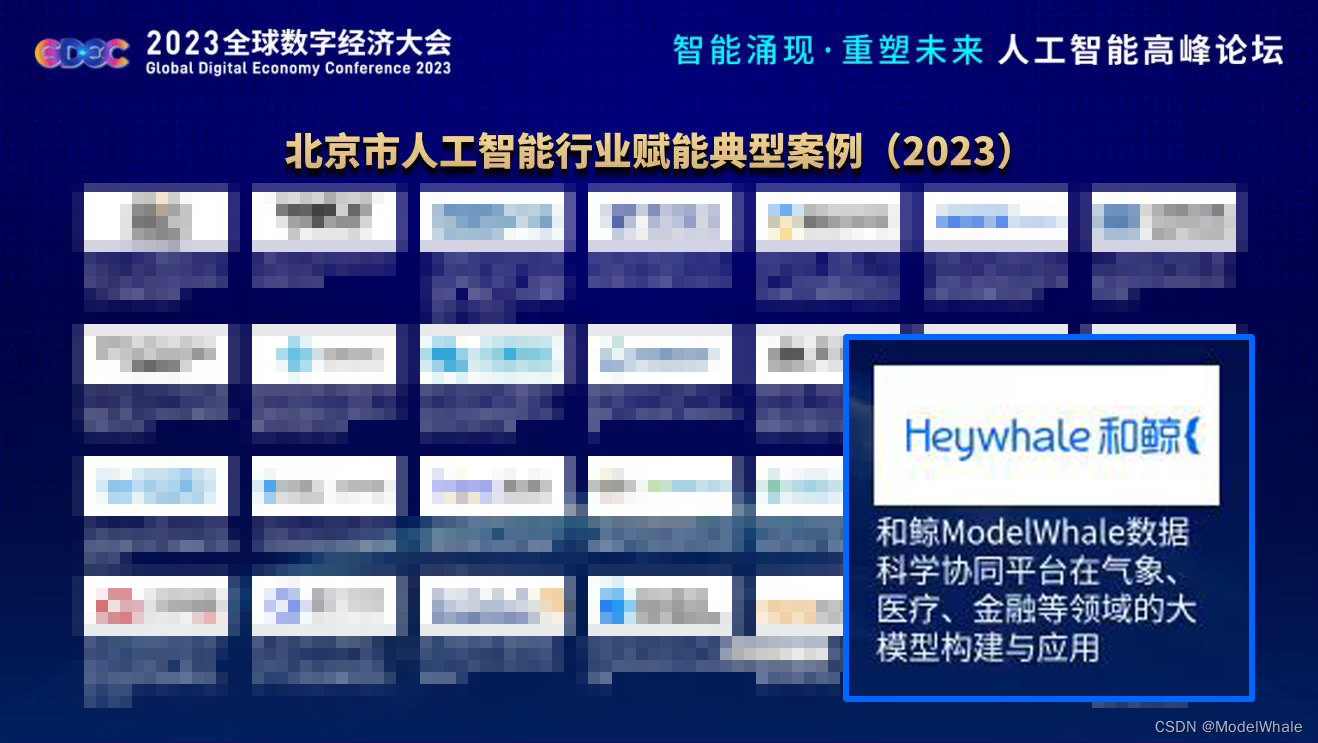
2023 全球数字经济大会人工智能高峰论坛,和鲸科技入选北京市人工智能行业赋能典型案例
7月,由国家发展改革委、工业和信息化部、科技部、国家网信办、商务部、中国科协联合北京市人民政府共同主办“2023全球数字经济大会”在京召开,本届活动主题为“数据驱动发展,智能引领未来”。其中“人工智能高峰论坛”重点围绕通用人工智能大…

【AI视野·今日NLP 自然语言处理论文速览 第五十四期】Fri, 13 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 13 Oct 2023 Totally 75 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models Authors Mengkang Hu, Yao M…

从 MLOps 到 LMOps 的关键技术嬗变
本文整理自 2023 年 9 月 3 日 QCon 全球软件开发大会 2023 北京站 —— 从 MLOps 到 LMOps 分论坛的同名主题演讲。 本次分享的内容结构如下: 从 MLOps 到 LMOps; MLOps 概述、挑战与解决方案; LMOps 实施挑战与关键技术(大模…
2023吉利汽车大模型算法工程师面试经验
来源:投稿 作者:LSC 编辑:学姐 问了很多问题,包括实习的项目经验、各种计算机、人工智能的基础,时长1h30min 1.coding
给你一个整数数组 prices 和一个整数 k ,其中 prices[i] 是某支给定的股票在第 i 天的…

(详细版)Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Haoran Wei1∗, Lingyu Kong2∗, Jinyue Chen2, Liang Zhao1, Zheng Ge1†, Jinrong Yang3, Jianjian Sun1, Chunrui Han1, Xiangyu Zhang1 1MEGVII Technology 2University of Chinese Academy of Sciences 3Huazhong University of Science and Technology arXiv 2023.12.11 …
【人工智能】百度智能云千帆AppBuilder,快速构建您的专属AI原生应用
大家好,我是全栈小5,欢迎来到《小5讲堂》,此序列是《人工智能》专栏文章。 这是2024年第5篇文章,此篇文章是进行人工智能相关的实践序列文章,博主能力有限,理解水平有限,若有不对之处望指正&…
垂直领域大模型落地思考
相比能做很多事,但每件事都马马虎虎的通用大模型;只能做一两件事,但这一两件事都能做好,可被信赖的垂直大模型会更有价值。这样的垂直大模型能帮助我们真正解决问题,提高生产效率。
本文将系统介绍如何做一个垂直领域…

Llama-2大模型本地部署研究与应用测试
最近在研究自然语言处理过程中,正好接触到大模型,特别是在年初chatgpt引来的一大波AIGC热潮以来,一直都想着如何利用大模型帮助企业的各项业务工作,比如智能检索、方案设计、智能推荐、智能客服、代码设计等等,总得感觉…
自然语言处理24-T5模型的介绍与训练过程,利用简单构造数据训练微调该模型,体验整个过程
大家好,我是微学AI,今天给大家介绍一下自然语言处理24-T5模型的介绍与训练过程,利用简单构造数据训练微调该模型,体验整个过程。在大模型ChatGPT发布之前,NLP领域是BERT,T5模型为主导,T5(Text-to-Text Transfer Transformer)是一种由Google Brain团队在2019年提出的自然…
大模型提效105篇必读论文和代码汇总,涵盖预训练、注意力、微调等7个方向
大型语言模型(LLMs)在NLP领域中具有显著的优势,它们在语言理解和生成方面表现出了强大的能力,甚至可以进行复杂的推理任务。这些能力能让大模型在许多领域都有广泛的应用前景,比如文本生成、对话系统、机器翻译、情感分…
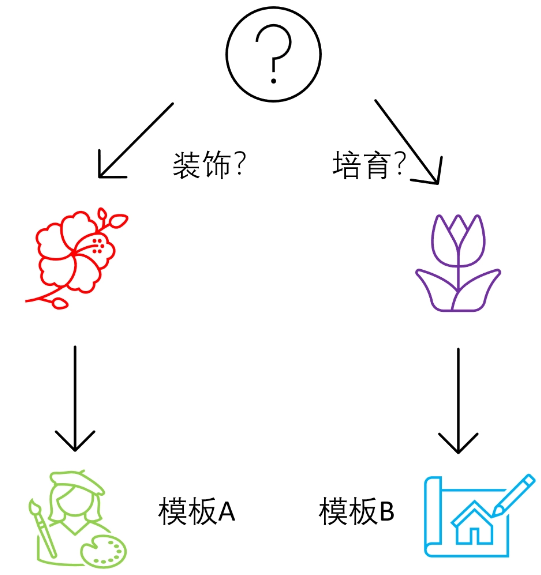
【LangChain学习之旅】—(10) 用RouterChain确定客户意图
【【LangChain学习之旅】—(10) 用RouterChain确定客户意图 任务设定整体框架具体步骤如下: 具体实现构建提示信息的模板构建目标链 Reference:LangChain 实战课
任务设定
首先,还是先看一下今天要完成一个什么样的任…

【LangChain学习之旅】—(9) 用SequencialChain链接不同的组件
【LangChain学习之旅】—(9)用SequencialChain链接不同的组件 什么是 ChainLLMChain:最简单的链链的调用方式直接调用通过 run 方法通过 predict 方法通过 apply 方法通过 generate 方法 Sequential Chain:顺序链首先,…

03.生成式学习的策略与工具
目录 生成式学习的两种策略生成的物件介绍文句影像语音 策略一:各个击破(Autoregressive (AR) model策略二:一次到位(Non-autoregressive (NAR) model)二者的比较其他策略二合一多次到位 AIGC工具New BingWebGPTWebGPT…
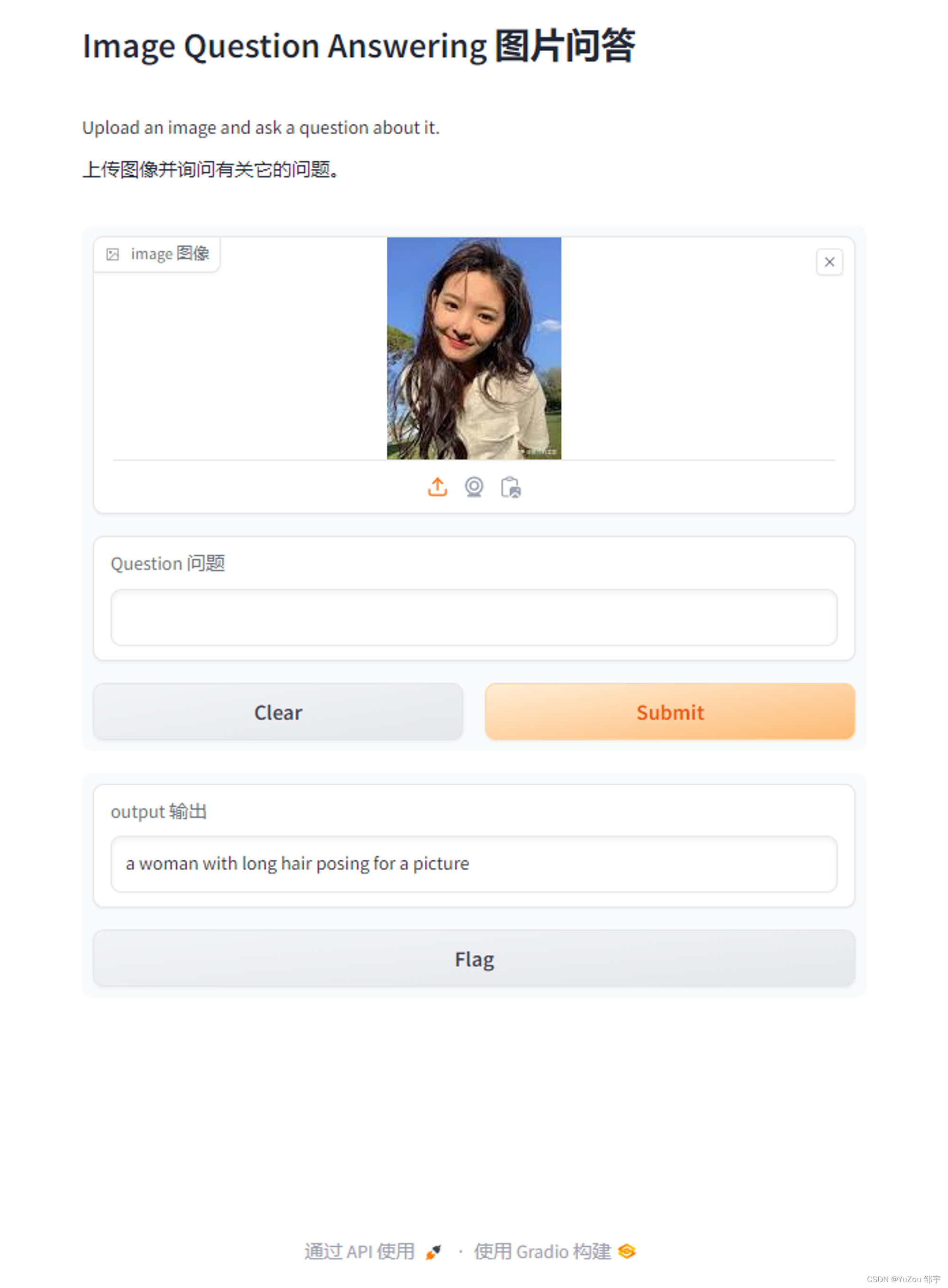
Hugging Face 介绍 快速搭建模型服务
Hugging Face 介绍 & 快速搭建模型服务 模型分类网站如何下载模型****[huggingface-cli](https://padeoe.com/huggingface-large-models-downloader/?loginfrom_csdn#4.1-huggingface-cli)****使用国内镜像 如何应用模型****部署和使用 Transformer 模型服务:使…
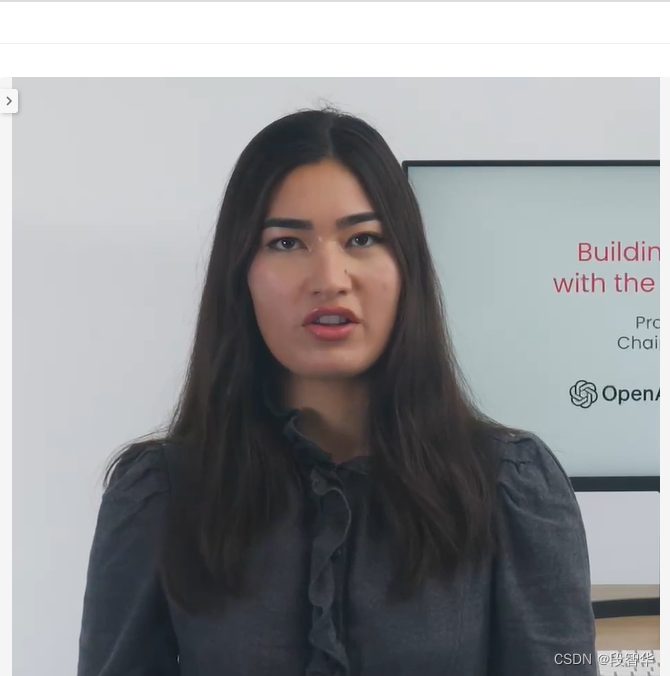
ChatGPT 使用 拓展资料:吴恩达大咖 Building Systems with the ChatGPT API 思维链
ChatGPT 使用 拓展资料:吴恩达大咖 Building Systems with the ChatGPT API 思维链 在本节中,我们将重点讨论要处理输出的任务,这些任务通常通过一系列步骤来获取输入并生成有用的输出。有时,在回答特定问题之前,模型详细推理问题是很重要的。如果你参加了我们之前为开发人…

用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
一图胜千言,LangChain已经成为当前 LLM 应用框架的事实标准,本篇文章就来对 LangChain 基本概念以及其具体使用场景做一个整理。 文章目录 用通俗易懂的方式讲解系列技术交流LangChain 是什么LangChain 的主要组件Model I/OLanguage ModelPromptsOutput…
用通俗易懂的方式讲解大模型:使用 Docker 部署大模型的训练环境
之前给大家介绍了主机安装方式——如何在 Ubuntu 操作系统下安装部署 AI 环境,但随着容器化技术的普及,越来越多的程序以容器的形式进行部署,通过容器的方式不仅可以简化部署流程,还可以随时切换不同的环境。
实际上很多云服务厂…

【LLM】Prompt微调
Prompt
在机器学习中,Prompt通常指的是一种生成模型的输入方式。生成模型可以接收一个Prompt作为输入,并生成与该输入相对应的输出。Prompt可以是一段文本、一个问题或者一个片段,用于指导生成模型生成相应的响应、续写文本等。
Prompt优化…

假期get新技能?低代码模型应用工具HuggingFists
HuggingFists是什么? HuggingFists是一款研究和使用HuggingFace模型和数据集的AI应用工具。 众所周知,Hugging Face是一家人工智能(AI)技术公司,致力于开发和推广自然语言处理(NLP)技术…
首发!动手学大模型应用开发教程来了
大模型正逐步成为信息世界的新革命力量,其通过强大的自然语言理解、自然语言生成能力,为开发者提供了新的、更强大的应用开发选择。随着国内外井喷式的大模型 API 服务开放,如何基于大模型 API 快速、便捷地开发具备更强能力、集成大模型的应…
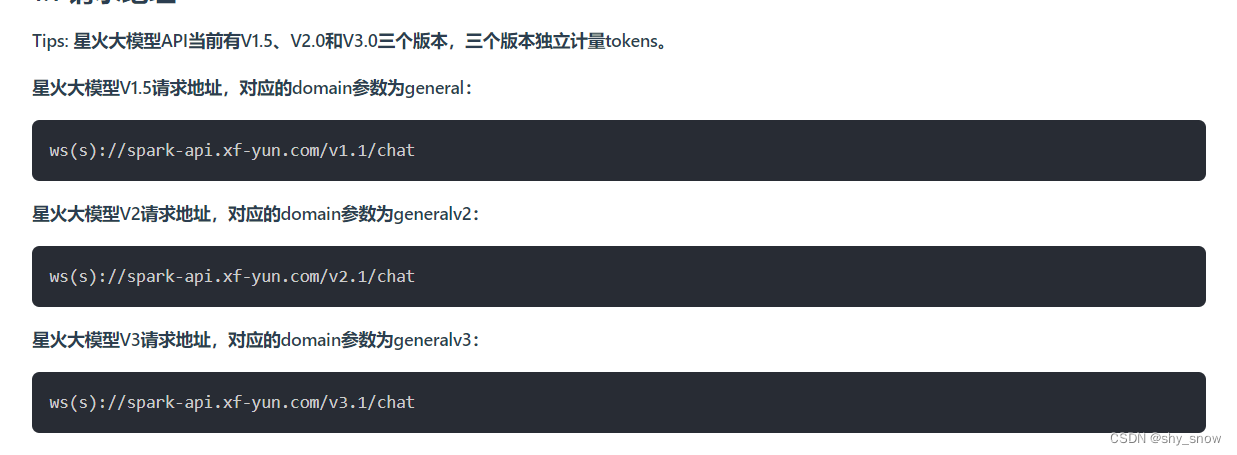
domain参数错误导致讯飞星火大模型:发生错误,错误码为:10404
问题
开通讯飞星火大模型api调用后,使用官方demo调用报错10404,最终发现是domain参数需要跟调用的版本保持一致,1.5,2,3版本分别传general,generalv2,generalv3,传错了还报错10404,感觉真没这必…
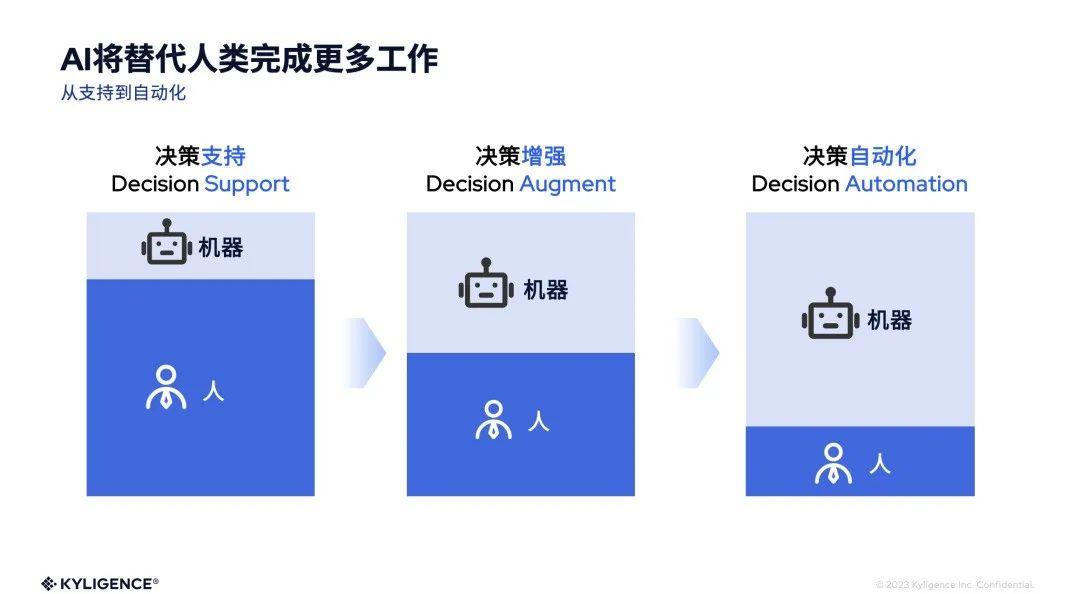
2024年,AI 掀起数据与分析市场的新风暴
2024 年伊始,Kyligence 联合创始人兼 CEO 韩卿在其公司内部的飞书订阅号发表了多篇 Rethink Data & Analytics 的内部信,分享了对数据与分析行业的一些战略思考,尤其是 AI 带来的各种变化和革命,是如何深刻地影响这个行业乃至…
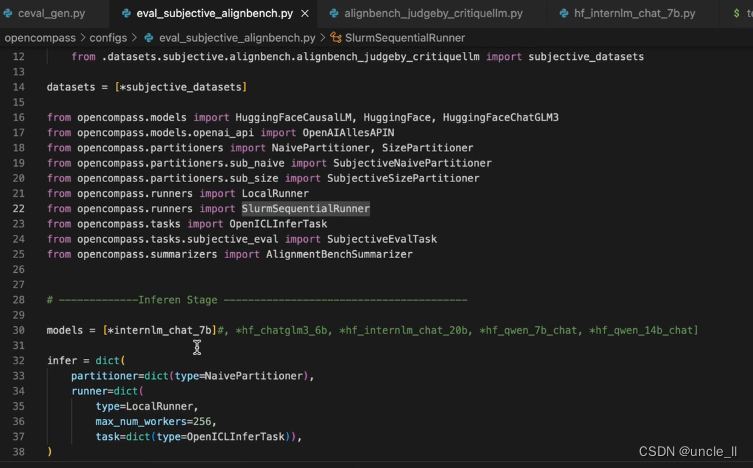
大模型学习之书生·浦语大模型6——基于OpenCompass大模型评测
基于OpenCompass大模型评测
关于评测的三个问题Why/What/How Why What 有许多任务评测,包括垂直领域
How 包含客观评测和主观评测,其中主观评测分人工和模型来评估。
提示词工程 主流评测框架 OpenCompass 能力框架 模型层能力层方法层工具层 支持丰富…
大模型学习之书生·浦语大模型2——趣味Demo
文章目录 Demo效果目录大模型及InternLM模型介绍InterLM-Chat-7B智能对话DemoLagent智能体工具调用Demo浦语灵笔图文创作理解Demo通用环境配置实践智能对话Demo1 创建开发机2 进入开发机并创建环境及安装依赖3 模型下载4 代码准备5 终端运行6 web demo运行 Lagent智能体工具调用…

百度智能云正式上线Python SDK版本并全面开源!
文章目录 1. SDK的优势2. 千帆SDK:快速落地LLM应用3. 如何快速上手千帆SDK3.1 SDK快速启动3.2 SDK进阶指引3.3 通过Langchain接入千帆SDK 4. 开源社区 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线Python SDK&#…

Transformer实战-系列教程1:Transformer算法解读
现在最火的AI内容,chatGPT、视觉大模型、研究课题、项目应用现在都是Transformer大趋势了
1、传统的RNN Transformer是基于RNN改进提出的,RNN不同于CNN、MLP是一个需要逐个计算的结构来进行分类回归的任务,它的每一个循环单元不仅仅要接受当…
FastGPT + Xinference + OneAPI:一站式本地 LLM 私有化部署和应用开发
Excerpt 随着 GPTs 的发布,构建私有知识库变得无比简易,这为个人创建数字化身份、第二大脑,或是企业建立知识库,都提供了全新的途径。然而,基于众所周知的原因,GPTs 在中国的使用依然存在诸多困扰和障碍。因此,在当… 随着 GPTs 的发布,构建私有知识库变得无比简易,这…

用通俗易懂的方式讲解:万字长文带你入门大模型
告别2023,迎接2024。大模型技术已成为业界关注焦点,你是否也渴望掌握这一领域却又不知从何学起?
本篇文章将特别针对入门新手,以浅显易懂的方式梳理大模型的发展历程、核心网络结构以及数据微调等关键技术。
如果你在阅读中收获…

一张图系列 - “kv cache“
我觉得回答这个问题需要知道3个知识点:
1、multi-head-attention是如何计算的?attention的数学公式? kv cache是如何存储和传递的?
2、kv cache 的原理步骤是什么?为什么降低了消耗?
3、kv cache 代码模…
大模型日报-20240112
重磅!OpenAI正式发布,自定义ChatGPT商店! https://mp.weixin.qq.com/s/Ic9XVFbwcR35Tcr25w28oA
OpenAI发布自定义GPT商店,开启商业模式,推出32K上下文的ChatGPT Team版本,助力学术研究、编程分析等&#x…
【CS324】Large Language Models(持续更新)
note 文章目录 note一、引言二、大模型的能力三、大模型的有害性(上)四、大模型的有害性(下)五、大模型的数据Reference 一、引言
语言模型最初是在信息理论的背景下研究的,可以用来估计英语的熵。 熵用于度量概率分布…
代码阅读:LanGCN
toc
1训练
1.1 进度条
import tqdm as tqdm
for i, data in tqdm(enumerate(train_loader),disablehvd.rank()):1.2 多进程通信
多线程通信依靠共享内存实现,但是多进程通信就麻烦很多,因此可以采用mpi库,如果是在python中使用࿰…
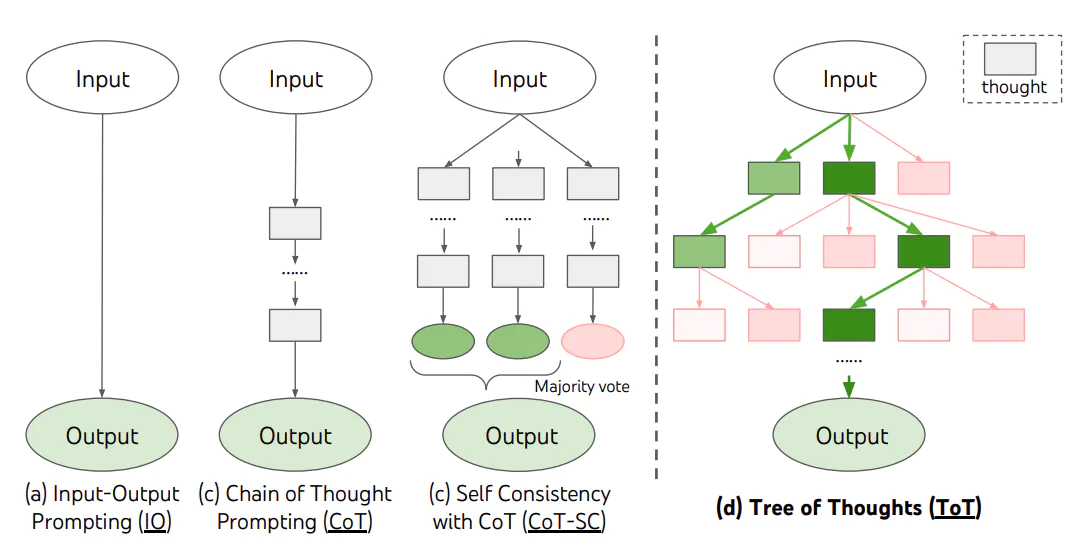
【LangChain学习之旅】—(6) 提示工程(下):用思维链和思维树提升模型思考质量
【LangChain学习之旅】—(6) 提示工程(下):用思维链和思维树提升模型思考质量 什么是 Chain of ThoughtFew-Shot CoTZero-Shot CoTChain of Thought 实战CoT 的模板设计程序的完整框架Tree of Thought总结 Reference&a…

NeurIPS 2023 | MQ-Det: 首个支持多模态查询的开放世界目标检测大模型
目前的开放世界目标检测模型大多遵循文本查询的模式,即利用类别文本描述在目标图像中查询潜在目标。然而,这种方式往往会面临“广而不精”的问题。一图胜千言,为此,作者提出了基于多模态查询的目标检测(MQ-Det…
大模型的实践应用10-大模型领域知识与参数高效微调(PEFT)技术的详解,并利用PEFT训练自己的大模型
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用10-大模型领域知识与参数高效微调(PEFT)技术的详解,并利用PEFT训练自己的大模型。大模型领域的参数高效微调技术(PEFT)是指通过对大规模神经网络模型进行高效率的参数微调,以提高模型性能和效率的一种方法。PEFT技术通…
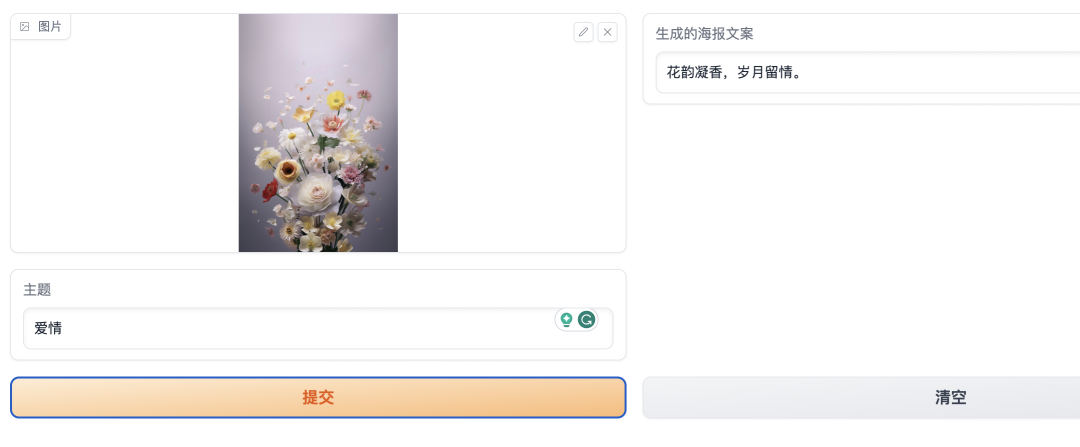
用通俗易懂的方式讲解大模型:使用 LangChain 和大模型生成海报文案
最近看到某平台在推 LangChain 的课程,其中有个示例是让 LangChain 来生成图片的营销文案,我觉得这个示例挺有意思的,于是就想自己实现一下,顺便加深一下 LangChain 的学习。 今天就介绍一下如何使用 LangChain 来实现这个功能&am…
文心一言大模型应用开发入门
本文重点介绍百度智能云平台、文心一言、千帆大模型平台的基本使用与接入流程及其详细步骤。
注册文心一言
请登录文心一言官方网站 https://yiyan.baidu.com/welcome 点击登录;图示如下: 请注册文心一言账号并点击登录,图示如下࿱…

大模型时代,开发者成长指南 | 新程序员
【编者按】GPT 系列的面世影响了全世界、各个行业,对于开发者们的感受则最为深切。以 ChatGPT、Github Copilot 为首,各类 AI 编程助手层出不穷。编程范式正在发生前所未有的变化,从汇编到 Java 等高级语言,再到今天以自然语言为特…
2024年1月15日Arxiv最热论文推荐:斯坦福LLM精准微调新框架、GPT不愿承认回答错误、速度快15倍的3D全景分割新突破
本文整理了今日发表在ArXiv上的AI论文中最热门的TOP5。
论文解读、论文热度排序、论文标签、中文标题、推荐理由和论文摘要均由赛博马良平台上的智能体 「AI论文解读达人」提供。
如需查看其他热门论文,欢迎移步赛博马良 ^_^
TOP1
APAR: LLMs Can Do Auto-Paral…
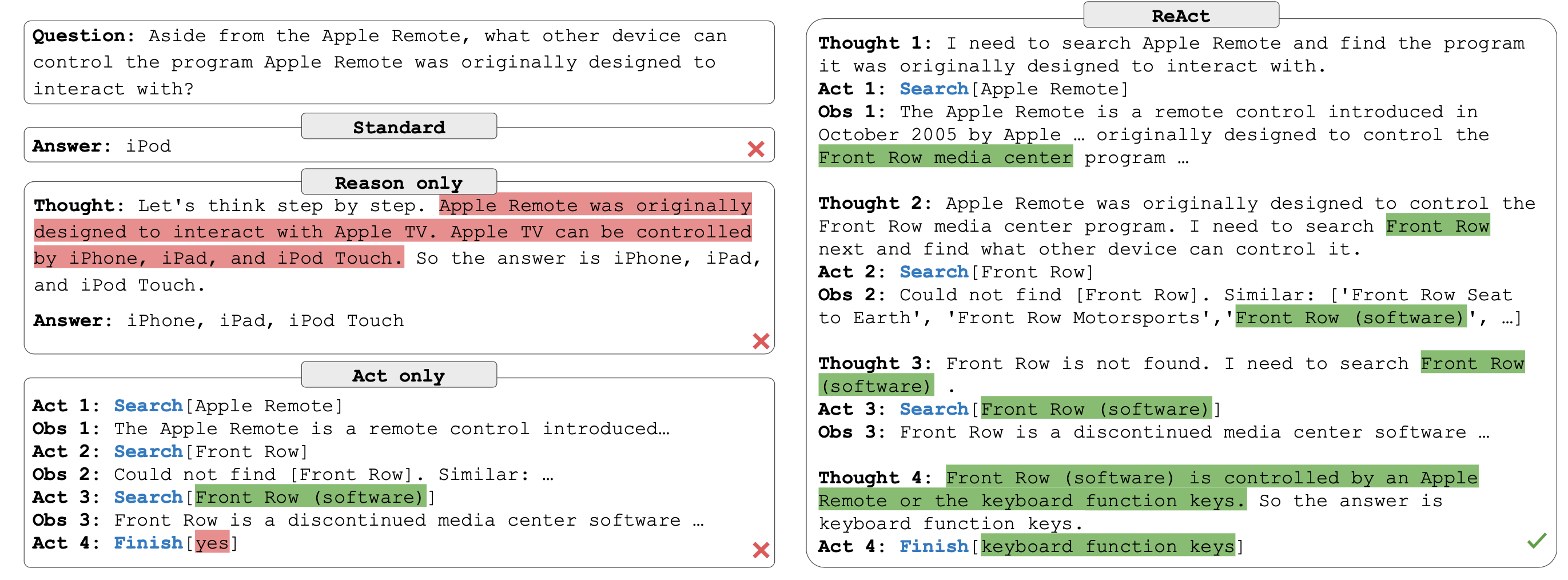
LLM ReAct: 将推理和行为相结合的通用范式 学习记录
LLM ReAct
什么是ReAct?
LLM ReAct 是一种将推理和行为相结合的通用范式,可以让大型语言模型(LLM)根据逻辑推理(Reason),构建完整系列行动(Act),从而达成期望目标。LLM ReAct 可以应用于多种语言和决策任务,例如问答、事实验证、交互式决策等,提高了 LLM 的效率、…

chatGLM中GLM设计思路
GLM是结合了MLM和CLM的一种预训练方式,其中G为general;在GLM中,它不在以某个token为粒度,而是一个span(多个token),这些span之间使用自编码方式,而在span内部的token使用自回归的方式…

碎片笔记 | 大模型攻防简报
前言:与传统的AI攻防(后门攻击、对抗样本、投毒攻击等)不同,如今的大模型攻防涉及以下多个方面的内容: 目录 一、大模型的可信问题1.1 虚假内容生成1.2 隐私泄露 二、大模型的模型安全问题(传统AI攻防&…

一种全新且灵活的 Prompt 对齐优化技术
并非所有人都熟知如何与 LLM 进行高效交流。
一种方案是,人向模型对齐。 于是有了 「Prompt工程师」这一岗位,专门撰写适配 LLM 的 Prompt,从而让模型能够更好地生成内容。
而另一种更为有效的方案则是,让模型向人对齐。 这也是…

科技云报道:大模型时代,SaaS元年才真的到来了?
科技云报道原创。
ChatGPT席卷全球后,如果有人问AI大模型影响最大的会是哪个行业?SaaS领域肯定是不二之选。
目前全球各大科技公司已宣称要用大模型触及、整合所有产品。
其中,微软率先为其办公家族装配上了各类copilot,开发者…
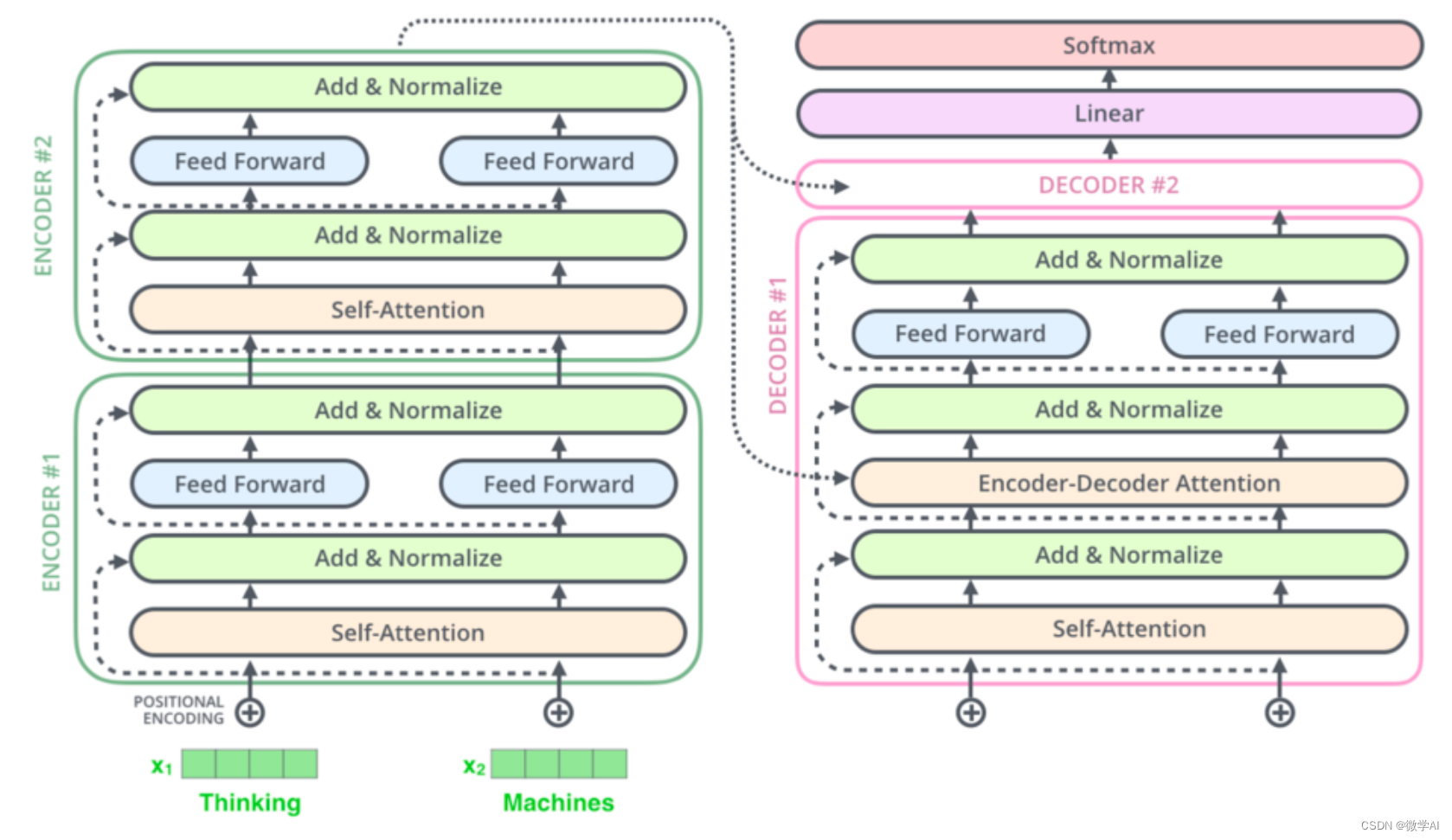
大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架。Transformer是一种基于自注意力机制的深度学习模型,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它最初被设计用…
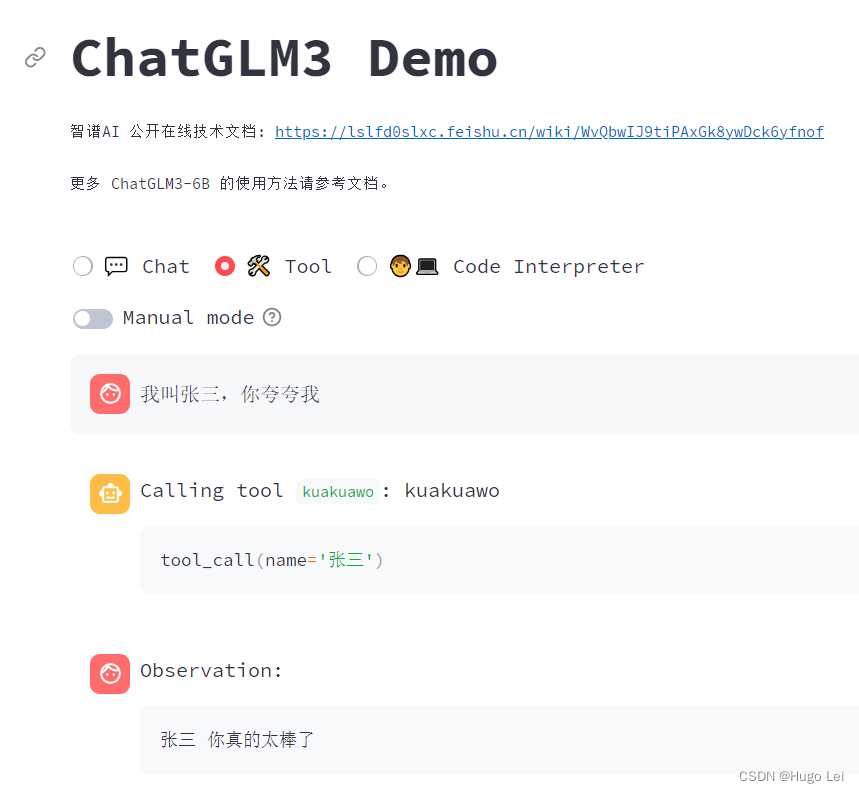
LLM大语言模型(三):使用ChatGLM3-6B的函数调用功能前先学会Python的装饰器
目录 ChatGLM3-6B的函数调用模式示例
本地启动ChatGLM3-6B工具模式
如何在ChatGLM3-6B里新增一个自定义函数呢?
get_weather基于Python的装饰器实现
函数注解register_tool
现在我们来自定义一个kuakuawo()函数 ChatGLM3-6B的函数调用模式示例
ChatGLM3-6B目前…
用通俗易懂的方式讲解大模型:HugggingFace 推理 API、推理端点和推理空间使用详解
接触 AI 的同学肯定对HuggingFace[1]有所耳闻,它凭借一个开源的 Transformers 库迅速在机器学习社区大火,为研究者和开发者提供了大量的预训练模型,成为机器学习界的 GitHub。
在 HuggingFace 上我们不仅可以托管模型,还可以方便…
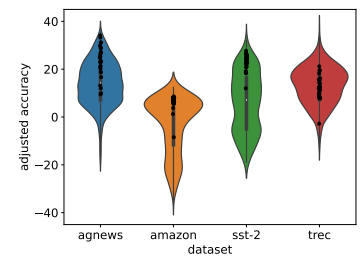
大模型上下文学习(ICL)训练和推理两个阶段31篇论文
大模型都火了这么久了,想必大家对LLM的上下文学习(In-Context Learning)能力都不陌生吧?
以防有的同学不太了解,今天我就来简单讲讲。
上下文学习(ICL)是一种依赖于大型语言模型的学习任务方式…

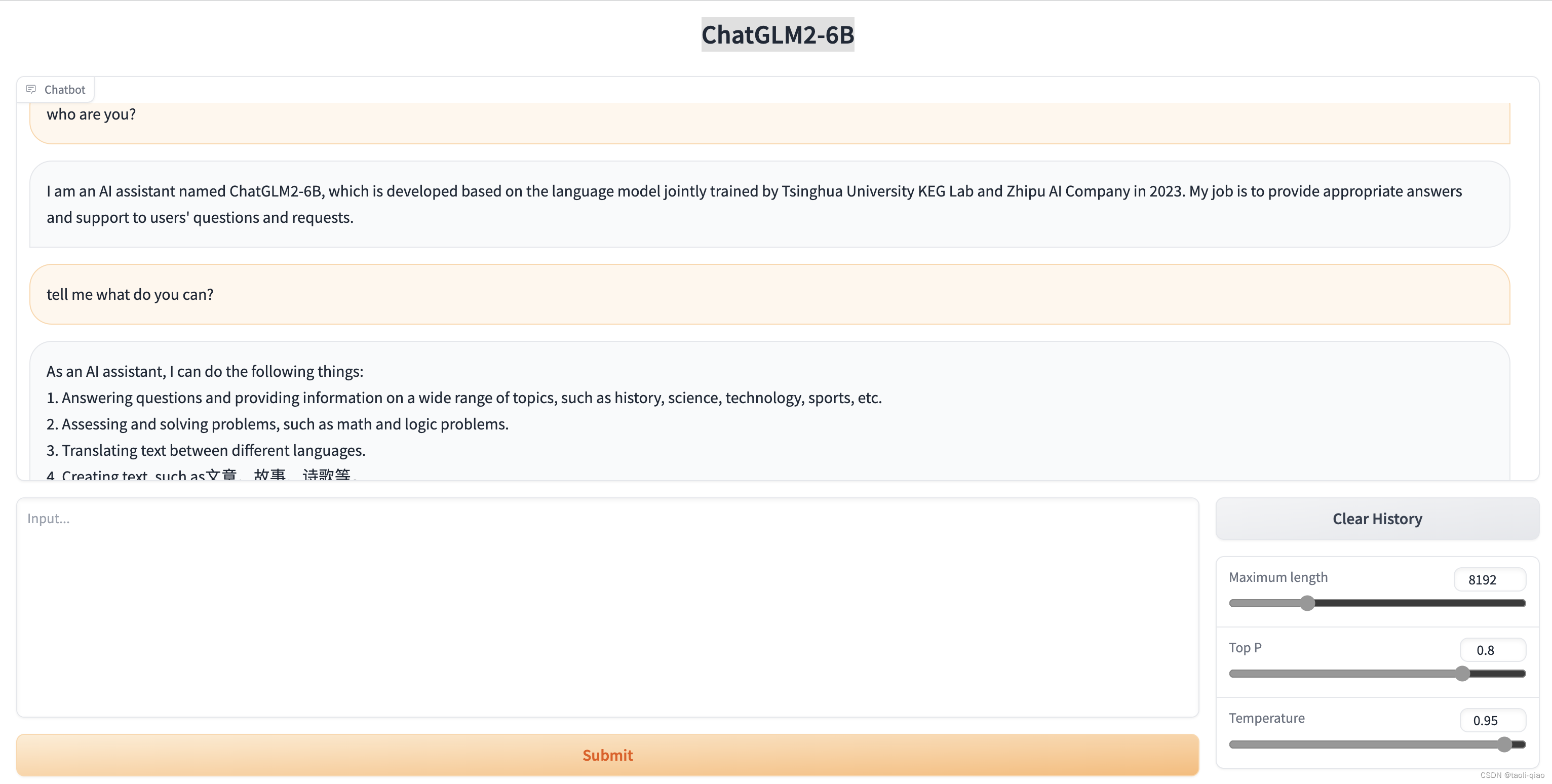
冲鸭~~!10分钟部署清华ChatGLM2-6B,效果测试:不愧是中文榜单第一
来源: AINLPer公众号(每日干货分享!!) 编辑: ShuYini 校稿: ShuYini 时间: 2023-9-25 引言 今年6月份清华大学发布了ChatGLM2,相比前一版本推理速度提升42%。最近,终于有时间部署测试看看了,部署…
预训练模型下载和使用
1 huggingface
Huggingface是一家公司,在Google发布BERT模型不久之后,这家公司推出了BERT的pytorch实现,形成一个开源库pytorch-pretrained-bert。后续又实现了其他的预训练模型,如GPT、GPT2、ToBERTa、T5等,便把开源…

人工智能时代大模型算法之文心大模型4.0
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…
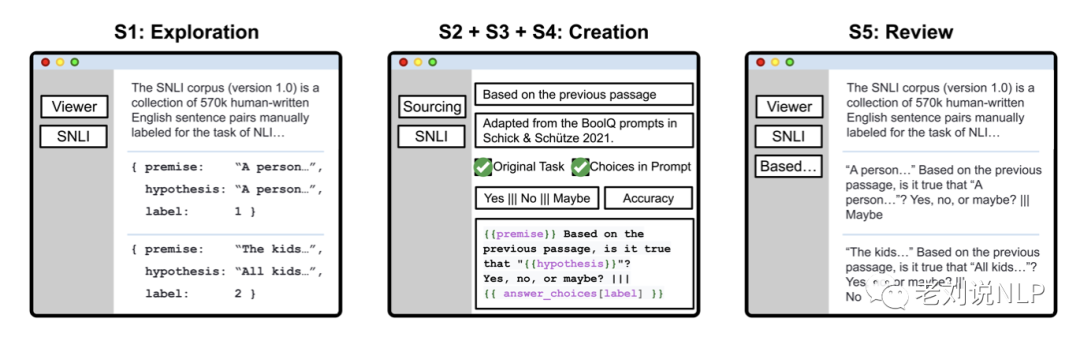
面向 NLP 任务的大模型 Prompt 设计
很久之前,我们介绍到,prompt是影响下游任务的关键所在,当我们在应用chatgpt进行nlp任务落地时,如何选择合适的prompt,对于SFT以及推理环节尤为重要。
不过,硬想不是办法,我们可以充分参考开源的…

调用openai实现聊天功能
📑前言
本文主要是【聊天机器人】——调用openai实现聊天功能的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是听风与他🥇 ☁️博客首页:CSDN主页听风与他 dz…
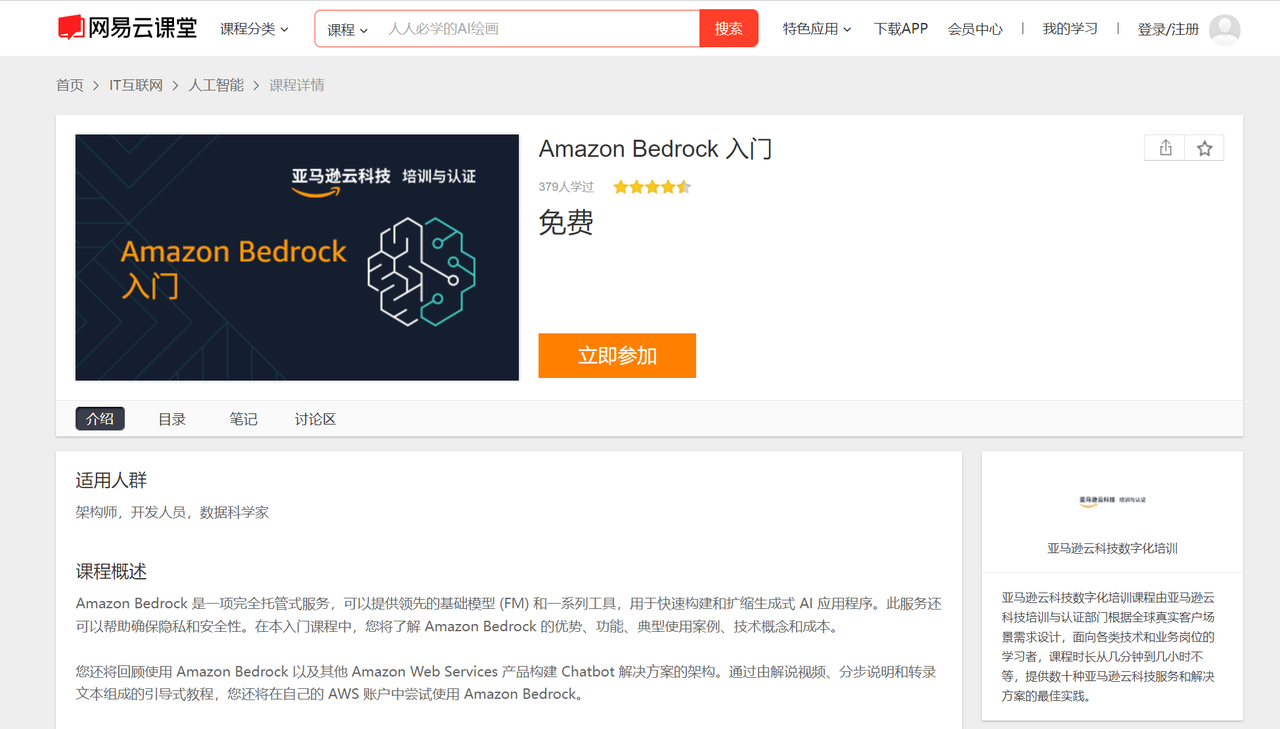
Amazon Bedrock ——使用Prompt构建AI软文撰写师的生成式人工智能应用程序
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应…
使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s
1,演示视频
https://www.bilibili.com/video/BV1gu4y1c7KL/ 使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s 2,关于A40显卡…
AIGC:阿里开源大模型通义千问部署与实战
1 引言
通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍…
GPT4的平替llama2本地部署教程,打造自己的专属大模型
llama2 是Meta公司发布的大预言模型,而且是一款开源免费的AI模型。光开源这个格局就吊打了GPT。从性能上来说更是号称是GPT4的平替。
今天这篇文章会从以下几个方面介绍下llama2:
1 基本介绍
2 本地mac环境部署llama2
llama2官方网址
https://llama…
成功解决Distributed package doesn‘t have NCCL “ “built in
成功解决Distributed package doesnt have NCCL " "built in 目录
解决问题
解决思路
解决方法
1、安装CUDA和cuDNN
DL之IDE:深度学习环境安装之Tensorflow/tensorflow_gpu+Cuda+Cudnn(最清楚/最快捷)之详细攻略(图文教程)
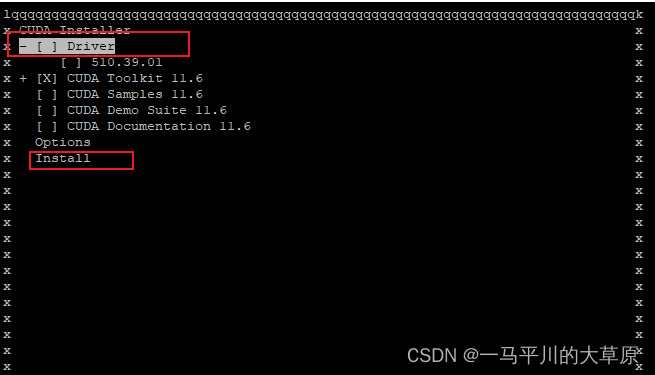
CUDA Toolkit多版本安装与配置
CUDA Toolkit多版本安装目的是为了将CUDA Toolkit支持多个版本,并将当前版本更新到后续支持常见pytorch的版本(即cuda11.6),目前该系统默认安装的是cuda10.2,cuda11.0和cuda11.2。CUDA一般有两种API,一个是…

C-Pack: Packaged Resources To Advance General Chinese Embedding
简介 论文提出了一个C-pack资源集合,其中包括三个主要的部分:
C-MTEB一个中文综合基准集合,包括6个任务和35个数据集合。C-MTP一个中文embedding数据集合,包括unlabeled和labeled两种数据。C-TEM一个embedding模型家族࿰…
人工智能三要素之算法Transformer
1. 人工智能三要数之算法Transformer
人工智能的三个要素是算法、数据和计算资源。Transformer 模型作为一种机器学习算法,可以应用于人工智能系统中的数据处理和建模任务。 算法: Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列数据的…

KernelGPT: LLM for Kernel Fuzzing
KernelGPT: Enhanced Kernel Fuzzing via Large Language Models 1.Introduction2.Background2.1.Kernel and Device Drivers2.2.Kernel Fuzzing2.2.1.Syzkaller规约2.2.2.规约生成 3.Approach3.1.Driver Detection3.2.Specification Generation3.2.1.Command Value3.2.2.Argum…

GPT5会是什么样的?奥特曼在YC W24会上演讲要点
“YC启动活动上,Sam Altman表示:以GPT-5和AGI将在’相对不久的将来’实现的心态来构建。” 在Y Combinator的一个启动活动中,Sam Altman表示,人工通用智能(AGI)的发展即将到来,并建议在构建产品…
和鲸科技与智谱AI达成合作,共建大模型生态基座
近日,上海和今信息科技有限公司(简称“和鲸科技”)与北京智谱华章科技有限公司(简称“智谱AI”)签订合作协议,双方将携手推动国产通用大模型的广泛应用与行业渗透,并积极赋能行业伙伴探索领域大…

【自然语言处理】大模型高效微调:PEFT 使用案例
文章目录 一、PEFT介绍二、PEFT 使用2.1 PeftConfig2.2 PeftModel2.3 保存和加载模型 三、PEFT支持任务3.1 Models support matrix3.1.1 Causal Language Modeling3.1.2 Conditional Generation3.1.3 Sequence Classification3.1.4 Token Classification3.1.5 Text-to-Image Ge…

玄学调参实践篇 | 深度学习模型 + 预训练模型 + 大模型LLM
😍 这篇主要简单记录一些调参实践,无聊时会不定期更新~ 文章目录 0、学习率与batch_size判断1、Epoch数判断2、判断模型架构是否有问题3、大模型 - 计算量、模型、和数据大小的关系4、大模型调参相关论文经验总结5、训练时模型的保存 0、学习率与batch_s…
LLM、ChatGPT与多模态必读论文150篇
为了写本 ChatGPT 笔记,我和10来位博士、业界大佬,在过去半年翻了大量中英文资料/paper,读完 ChatGPT 相关技术的150篇论文,当然还在不断深入。
由此而感慨:
读的论文越多,你会发现大部分人对ChatGPT的技…

认识 AIGC ,浅淡 AIGC 的那些事—— AIGC:用 AI 创造万物
文章目录 🎨关于封面🔥关于活动📋前言🎯什么是 AIGC ?🧩AIGC:用 AI 创造万物🧩AIGC 的意义与发展 🎯AIGC 的发展历程🧩人工智能生成内容的发展历程与概念&…

突破大模型 | Alluxio助力AI大模型训练-成功案例(一)
更多详细内容可见《Alluxio助力AI大模型训练制胜宝典》
【案例一:知乎】多云缓存在知乎的探索:从UnionStore到Alluxio 作者:胡梦宇-知乎大数据基础架构开发工程师(内容转载自InfoQ) 一、背景
随着云原生技术的飞速发展ÿ…

2023年8月第1~2周大模型荟萃
2023年8月第1~2周大模型荟萃
2023.8.14版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、黑客制造了一款基于 AI 的恶意工具 FraudGPT
早先,有黑客制作了一个“没有道德限制”的 WormGPT 聊天机器人,可以自动生成…

LaWGPT零基础部署win10+anaconda
准备代码,创建环境 # 下载代码 git clone gitgithub.com:pengxiao-song/LaWGPT.git cd LaWGPT
# 创建环境 conda create -n lawgpt python3.10 -y conda activate lawgpt pip install -r requirements.txt
# 启动可视化脚本(自动下载预训练模型约15GB&…
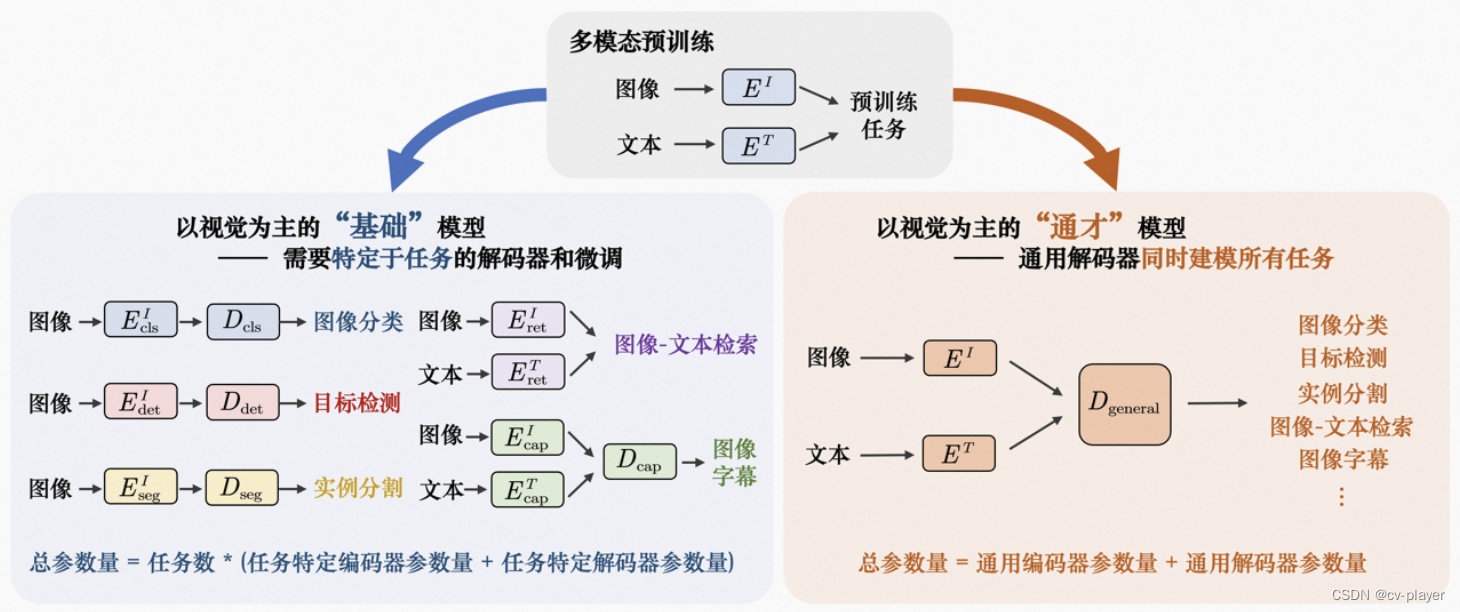
超大规模视觉通用感知模型
超大规模视觉通用感知模型 通用感知模型简介与发展超大规模图像、文本主干网络多任务兼容解码网络 参考文献 通用感知模型简介与发展
通用感知模型是指一个模型解决不同的感知任务,应用于各种模态数据。
通用感知模型的发展脉络图如下,它由NLP发源&…

【优质书籍推荐】LoRA微调的技巧和方法
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…
CODE LLM 对比
CODE LLM
ModelPass1License机构RespositoryCodeGen-16B-multi19.2开源SalesforceSalesforce/codegen-16B-multi at mainhttps://github.com/salesforce/CodeGenCodeGeeX-13B22.9开源清华大学https://github.com/THUDM/CodeGeeXCodex-12B28.8不开源OpenAICodeT5Plus-16B-mono3…
【LLM评估篇】Ceval | rouge | MMLU等指标
note
一些大模型的评估模型:多轮:MTBench关注评估:agent bench长文本评估:longbench,longeval工具调用评估:toolbench安全评估:cvalue,safetyprompt等 文章目录 note常见评测benchm…
政安晨的AI笔记——Bard大模型最新提示词创作绘画分析
AI大模型进入商业应用元年后的第一年,顶级模型大混战终于开始了。
Bard在追赶OpenAI的过程中,还是补上了画图的短板。
(相比于视频的5阶张量处理而言,图画做为4阶张量处理虽然不新鲜,但却是跨不过去的基础条件&#…

【LLM数据篇】预训练数据集+指令生成sft数据集
note
在《Aligning Large Language Models with Human: A Survey》综述中对LLM数据分类为典型的人工标注数据、self-instruct数据集等优秀的开源sft数据集:alpaca_data、belle、千言数据集、firefly、moss-003-sft-data多轮对话数据集等 文章目录 note构造指令实例…

【AI视野·今日NLP 自然语言处理论文速览 第三十六期】Wed, 20 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 20 Sep 2023 Totally 64 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
SlimPajama-DC: Understanding Data Combinations for LLM Training Authors Zhiqiang Shen, Tianhua Tao, Li…

Streamlit项目:基于讯飞星火认知大模型开发Web智能对话应用
文章目录 1 前言2 API获取3 官方文档的调用代码4 Streamlit 网页的搭建4.1 代码及效果展示4.2 Streamlit相关知识点 5 结语 1 前言
科大讯飞公司于2023年8月15日发布了讯飞认知大模型V2.0,这是一款集跨领域知识和语言理解能力于一体的新一代认知智能大模型。前日&a…
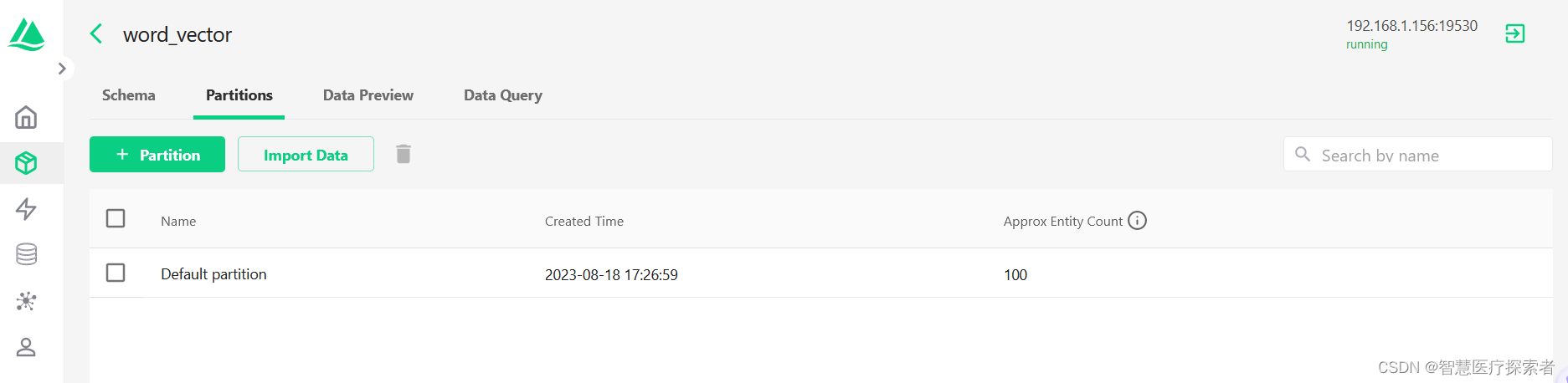
为AI而生的数据库:Milvus详解及实战
1 向量数据库
1.1 向量数据库的由来
在当今数字化时代,人工智能AI正迅速改变着我们的生活和工作方式。从智能助手到自动驾驶汽车,AI正在成为各行各业的创新引擎。然而,这种AI的崛起也带来了一个关键的挑战:如何有效地处理和分析…
用通俗易懂的方式讲解:大模型向量数据库那么多,我该如何选择?
在一个语义搜索和检索增强生成(RAG)正在重新定义的时代,支持这些进步的支柱往往被忽视:向量数据库。如果您涉足大型语言模型、RAG或任何利用语义搜索的平台,那么你来对地方了。
对于那些在这一领域探索的人࿰…

Qwen-7B微调实例
Qwen-SFT
阿里通义千问(Qwen-7B-Chat/Qwen-7B), 微调/LORA/推理
Github
https://github.com/yongzhuo/Qwen-SFT
踩坑
1. tokenizer.encode输出(不会新增特殊字符), 为 [真实文本tokens]:
2. chat-PROMPT: <|im_start|>system\nYou are a helpful assistant.<|im…
大模型从入门到应用——LangChain:链(Chains)-[链与索引:图问答(Graph QA)和带来源的问答(QA with Sources)]
分类目录:《大模型从入门到应用》总目录 图问答(Graph QA)
创建图
在本节中,我们构建一个示例图。目前,这对于较小的文本片段效果最好,下面的示例中我们只使用一个小片段,因为提取知识三元组对…

极智开发 | macwindows本地部署安装AIGC绘图工具Stable Diffusion WebUI
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 mac&windows本地部署安装AIGC绘图工具Stable Diffusion WebUI。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0ai…

广受好评的开源基础大模型最全梳理,你最钟意哪一个?
2023 年即将过去。一年以来,各式各样的大模型争相发布。当 OpenAI 和谷歌等科技巨头正在角逐时,另一方「势力」悄然崛起 —— 开源。
开源模型受到的质疑一向不少。它们是否能像专有模型一样优秀?是否能够媲美专有模型的性能?
迄…

熬了一个通宵,把国内外的大模型都梳理完了!
大家好,大模型越来越多了,真的有点让人眼花缭乱。
为了让大家清晰地了解大模型,我熬了一个通宵把国内和国外的大模型进行了全面梳理,国内有189个,国外有20,同时包括大模型的来源机构、来源信息和分类等。 …
大模型从入门到应用——LangChain:链(Chains)-[链与索引:检索式问答]
分类目录:《大模型从入门到应用》总目录 下面这个示例展示了如何在索引上进行问答:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitte…

对战ChatGPT,创邻科技的Graph+AI会更胜一筹吗?
大模型(大规模语言模型,即Large Language Model)的应用已经成为千行百业发展的必然。特定领域或行业中经过训练和优化的企业级垂直大模型则成为大模型走下神坛、真正深入场景的关键之路。
但是,企业级垂直大模型在正式落地应用前…
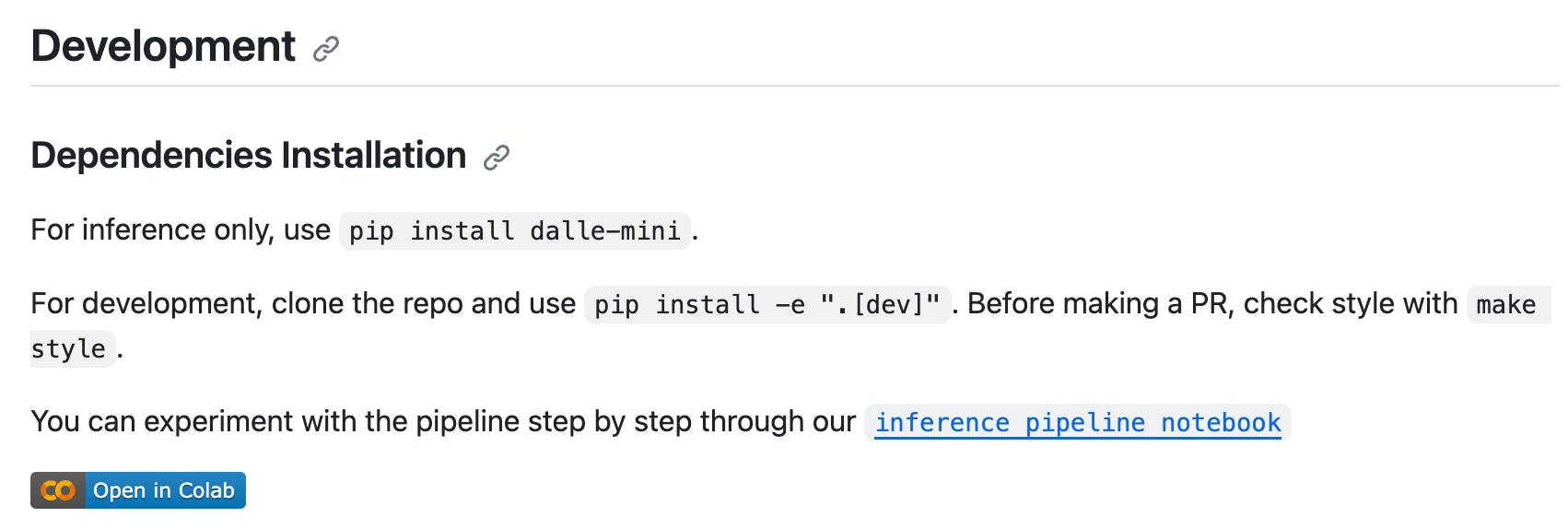
超详细!DALL · E 文生图模型实践指南
最近需要用到 DALLE的推断功能,在现有开源代码基础上发现还有几个问题需要注意,谨以此篇博客记录之。 我用的源码主要是 https://github.com/borisdayma/dalle-mini 仓库中的Inference pipeline.ipynb 文件。 运行环境:Ubuntu服务器
⚠️注意…
2023年8月第4周大模型荟萃
2023年8月第4周大模型荟萃
2023.8.31版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、美国法官最新裁定:纯AI生成的艺术作品不受版权保护
美国华盛顿一家法院近日裁定,根据美国政府的法律,在没有任何…
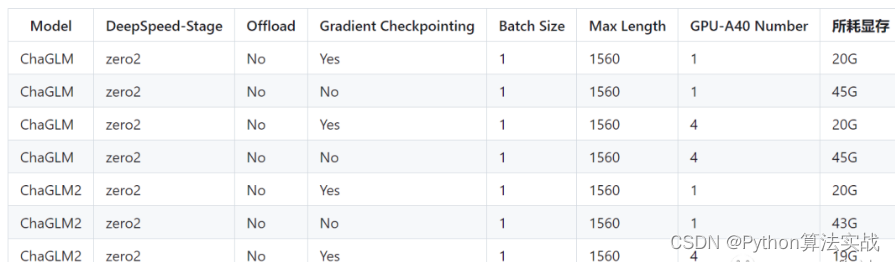
不用再找,这是大模型 LLM 微调经验最全总结
大家好,今天对大模型微调项目代码进行了重构,支持ChatGLM和ChatGLM2模型微调的切换,增加了代码的可读性,并且支持Freeze方法、Lora方法、P-Tuning方法、「全量参数方法」 微调。
PS:在对Chat类模型进行SFT时ÿ…
GPT-4创造者:第二次改变AI浪潮的方向
OneFlow编译 翻译|贾川、杨婷、徐佳渝 编辑|王金许 一朝成名天下知。ChatGPT/GPT-4相关的新闻接二连三刷屏朋友圈,如今,这些模型背后的公司OpenAI的知名度不亚于任何科技巨头。 不过,就在ChatGPT问世前,Ope…
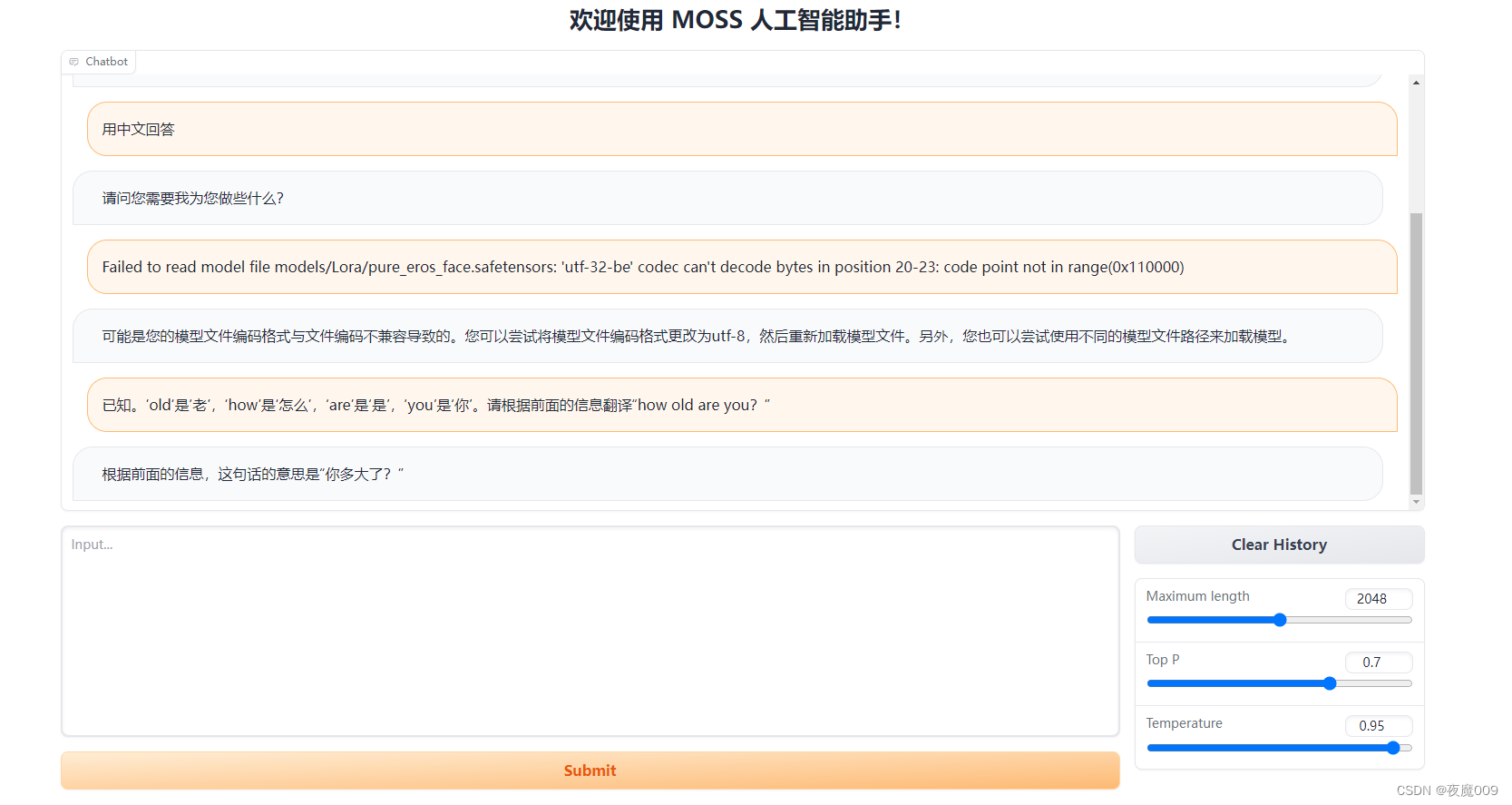
基于趋动云部署复旦大学MOSS大模型
首先新建项目:
MOSS部署项目,然后选择镜像,直接用官方的镜像就可以。
之后选择数据集:
公开数据集中,MOSS_复旦大学_superx 这个数据集就是了,大小31G多 完成选择后: 点击创建,…
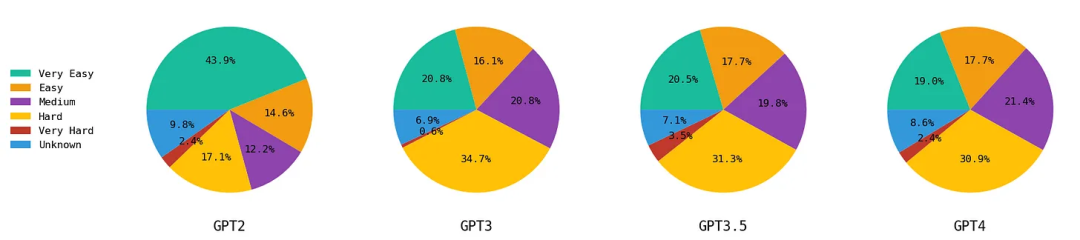
大语言模型的创意能力到底几何?探索从GPT-2到GPT-4的演进
编者按:大语言模型可以提供许多创意性内容,如写诗、写小说等。那么到底应该如何评估大语言模型生成的创意性内容的水平呢? 本文探讨了GPT-2到GPT-4的创造性,并分析了这些模型在不同创造性测试中的表现。作者使用了三种测试来衡量模…
AI大模型知识点大梳理
文章目录 AI大模型是什么AI大模型发展历程AI大模型的底层原理AI大模型解决的问题大模型的优点和不足影响个人观点 AI大模型是什么
AI大模型是指具有巨大参数量的深度学习模型,通常包含数十亿甚至数万亿个参数。这些模型可以通过学习大量的数据来提高预测能力&#…

『2023北京智源大会』6月9日上午|开幕式及全体大会
『2023北京智源大会』6月9日上午|开幕式及全体大会 文章目录 一. 黄铁军丨智源研究院院长1. 大语言模型2. 大语言模型评测体系FlagEval3. 大语言模型生态(软硬件)4. 三大路线通向 AGI(另外2条路径) 二. Towards Machines that can Learn, Reason, and Plan(杨立昆丨图灵奖得主…
基于清华chatglm-6b模型的向量化检索问答
之前清华模型已经证实在中文领域具有相当不错的表现,这是其他老外模型所不具备的(除了openai),目前在免费领域来说chatglm-6b已经是领头羊的地位。抛开此模型的弊端(微调大部分都会失败,可能失去通用领域的能力,可能失去语言能力)来说,将其应用于本地知识库的问答检索…
基于Streamlit的应用如何通过streamlit-authenticator组件实现用户验证与隔离
Streamlit框架中默认是没有提供用户验证组件的,大家在基于streamlit快速实现web应用服务过程中,不可避免的需要配置该应用的访问范围和权限,即用户群体,一般的做法有两种,一种是通过用户密码验证机制,要求只…
使用Fastchat部署vicuna大模型
FastChat是一个用于训练、提供服务和评估基于大型语言模型的聊天机器人的开放平台。其核心特点包括:
最先进模型(例如 Vicuna)的权重、训练代码和评估代码。一个分布式的多模型提供服务系统,配备 Web 用户界面和与 OpenAI 兼容的…

“百模大战”大模型哪家强?开源的全面评测来了!
最近,一则推送在网上火了:《世界人工智能大会上的大模型都在这了,让你一次看个够》 小编兴奋地点开文章,好家伙,整篇文章没有字,只有满眼的 “大模型”。 小编顶着昏花的老眼,手动数了一下&…
学术论文GPT源码解读:从chatpaper、chatwithpaper到gpt_academic
前言
之前7月中旬,我曾在微博上说准备做“20个LLM大型项目的源码解读” 针对这个事,目前的最新情况是
已经做了的:LLaMA、Alpaca、ChatGLM-6B、deepspeedchat、transformer、langchain、langchain-chatglm知识库准备做的:chatpa…

langchain主要模块(三):Chain
langchain2之Chain langchain1.概念2.主要模块模型输入/输出 (Model I/O)数据连接 (Data connection)链式组装 (Chains)代理 (Agents)内存 (Memory)回调 (Callbacks) 3.链• LLMChain:• SimpleSequentialChain• Sequential Chains:• RouterChain: lan…
冉冉升起的星火,再度升级迎来2.0时代!
文章目录 前言权威性评测结果 星火大模型多模态功能插件功能简历生成文档问答PPT生成 代码能力 福利 前言
前几天从技术群里看到大家都在谈论《人工智能大模型体验报告2.0》里边的内容,抱着好奇和学习的态度把报告看了一遍。看完之后瞬间被里边提到的科大讯飞的星火…
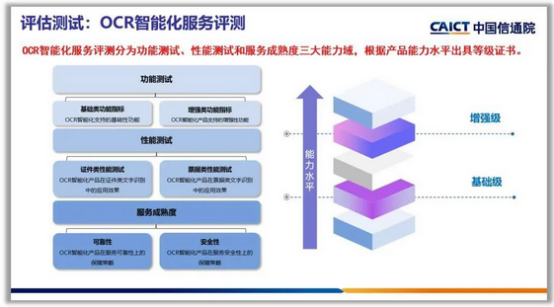
用AI攻克“智能文字识别创新赛题”,这场大学生竞赛掀起了什么风潮?
文章目录 一、前言1.1 大赛介绍1.2 项目背景 二、基于智能文字场景个人财务管理创新应用2.1 作品方向2.2 票据识别模型2.2.1 文本卷积神经网络TextCNN2.2.2 Bert 预训练微调2.2.3 模型对比2.2.4 效果展示 2.3 票据文字识别接口 三、未来展望 一、前言
1.1 大赛介绍
中国大学生…

langchain主要模块(二):数据连接
langchain2之数据连接 langchain1.概念2.主要模块模型输入/输出 (Model I/O)数据连接 (Data connection)链式组装 (Chains)代理 (Agents)内存 (Memory)回调 (Callbacks) 3.数据连接1.数据加载:2.文档分割:3.文档向量化:4.存储和检索向量数据:…

Safetynet论文精读
基本信息
团队:Level 5, Toyota收购的Lyft自动驾驶团队(对,这个团队名字就叫Level 5) 年份:2021 官网:https://www.self-driving-cars.org/papers/2022-safetynet(对,他…
大模型从入门到应用——LangChain:代理(Agents)-[代理执行器(Agent Executor):结合使用Agent和VectorStore]
分类目录:《大模型从入门到应用》总目录 代理执行器接受一个代理和工具,并使用代理来决定调用哪些工具以及以何种顺序调用。本文将参数如何结合使用Agent和VectorStore。这种用法是将数据加载到VectorStore中,并希望以Agent的方式与之进行交互…

【送书活动】大模型赛道如何实现华丽的弯道超车
文章目录 导读模型训练01 具备对海量小文件的频繁数据访问的 I/O 效率02 提高 GPU 利用率,降低成本并提高投资回报率03 支持各种存储系统的原生接口04 支持单云、混合云和多云部署 Alluxio01 通过数据抽象化统一数据孤岛02 通过分布式缓存实现数据本地性03 优化整个…

爬虫获取一个网站内所有子页面的内容
上一篇介绍了如何爬取一个页面内的所有指定内容,本篇讲的是爬去这个网站下所有子页面的所有指定的内容。 可能有人会说需要的内容复制粘贴,或者直接f12获取需要的文件下载地址一个一个下载就行了,但是如下图十几个一级几十个二级一百多个疾病…
大模型从入门到应用——LangChain:代理(Agents)-[计划与执行]
分类目录:《大模型从入门到应用》总目录
LangChain系列文章:
基础知识快速入门 安装与环境配置链(Chains)、代理(Agent:)和记忆(Memory)快速开发聊天模型 模型(Models&…
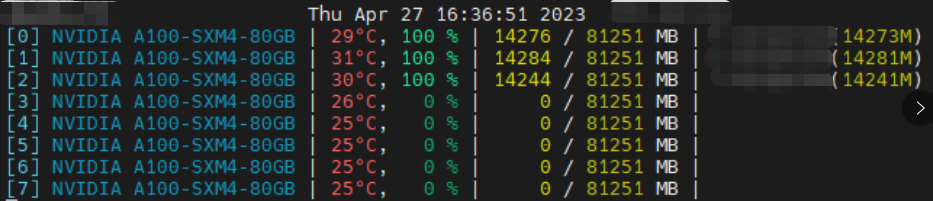
A100单机多卡大模型训练踩坑记录(CUDA环境、多GPU卡住且显存100%)
踩坑1:服务器只装了 CUDA Driver 没装 CUDA Toolkit
系统:Ubuntu-18.04 用 deepspeed 跑百亿模型训练时,报关于 CUDA_HOME 的错误。
AssertionError: CUDA_HOME does not exist, unable to compile CUDA op(s)执行 echo $CUDA_HOME 和 nvcc…

【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成的代码大语言模型
CodeGen:一个用于多轮程序合成的代码大语言模型 《Code Gen: An Open Large Language Model For Code with Multi-Turn Program Synthesis》 论文地址:https://arxiv.org/pdf/2203.13474.pdf?trkpublic_post_comment-text 相关博客 【自然语言处理】【大…

AI大模型的使用-用LangChain链式调用简化多步提示语
众所周知,openAI的prompt对英文比较友好,也就是英文提示它的结果会更准确,假如我们不会英文,我们把中文问题给到OpenAI,然后让它翻译成英文,并把翻译后的英文给到OpenAI,让它帮忙给出解答问题&a…
LLM大模型开源案例集,需带有:数据集+模型微调+项目代码(三)
文章目录 1 ChatGLM-Med: 基于中文医学知识的ChatGLM模型微调1.1 数据集1.2 ChatGLM+P-tuning V2微调1.3 Llama + Alpaca的Lora微调版本2 LawGPT_zh:中文法律大模型(獬豸)2.1 数据集2.1.1 利用ChatGPT清洗CrimeKgAssitant数据集得到52k单轮问答:2.1.2 带有法律依据的情景问…

基于LLMs的多模态大模型(MiniGPT-4,LLaVA,mPLUG-Owl,InstuctBLIP,X-LLM)
这个系列的前一些文章有:
基于LLMs的多模态大模型(Visual ChatGPT,PICa,MM-REACT,MAGIC)基于LLMs的多模态大模型(Flamingo, BLIP-2,KOSMOS-1,ScienceQA)
前…
利用大模型MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7实现零样本分类
概念
1、零样本分类:在没有样本标签的情况下对文本进行分类。
2、nli:(Natural Language Inference),自然语言推理
3、xnli:(Cross-Lingual Natural Language Inference) ,是一种数据集,支持15种语言,数据集包含10个领域,每个领…
chatglm2-6b在P40上做LORA微调 | 京东云技术团队
背景:
目前,大模型的技术应用已经遍地开花。最快的应用方式无非是利用自有垂直领域的数据进行模型微调。chatglm2-6b在国内开源的大模型上,效果比较突出。本文章分享的内容是用chatglm2-6b模型在集团EA的P40机器上进行垂直领域的LORA微调。 …
2023年5月第4周大模型荟萃
2023年5月第4周大模型荟萃
2023.5.31版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、AI 图像编辑技术 DragGAN 问世
近日,来自 Google 的研究人员与 Max Planck 信息学研究所和麻省理工学院 CSAIL 一起,发布了…
AI和软件测试结合-使用LLM将自然语言生成TestCase
曾在工作之余,设想过一个能提升测试流程左侧效率的点子,结合人工智能,将自然语言自动转化为通用的功能用例、接口用例、代码单元测试用例等一系列用例,碰上这2年LLM模型大爆发,遂有自己炼一个用例生成的专用模型的想法…

文献阅读:The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
文献阅读:The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” 1. 文章简介2. 实验 & 结果考察 1. finetune实验2. 真实知识问答 3. 结论 & 思考 文献链接:https://arxiv.org/abs/2309.12288
1. 文章简介
这篇文章是前…
AWS实例上本地部署ChatGLM2-6B
此篇博客主要介绍如何在AWS上创建带GPU的instance,并在instance上部署ChatGLM大模型。
AWS上申请带GPU的instance
ChatGLM虽然也支持在CPU的instance上部署,但这里选择在GPU的instance上部署。所以,先在AWS上选择带GPU的instance。AWS上区分…
大语言模型在天猫AI导购助理项目的实践!
本文主要介绍了Prompt设计、大语言模型SFT和LLM在手机天猫AI导购助理项目应用。
ChatGPT基本原理
“会说话的AI”,“智能体” 简单概括成以下几个步骤: 预处理文本:ChatGPT的输入文本需要进行预处理。 输入编码:ChatGPT将经过预…

大模型(LLM)在电商推荐系统的探索与实践
本文对LLM推荐的结合范式进行了梳理和讨论,并尝试将LLM涌现的能力迁移应用在推荐系统之中,利用LLM的通用知识来辅助推荐,改善推荐效果和用户体验。
背景
电商推荐系统(Recommend System,RecSys)是一种基于…
LORA项目源码解读
大模型fineturn技术中类似于核武器的LORA,简单而又高效。其理论基础为:在将通用大模型迁移到具体专业领域时,仅需要对其高维参数的低秩子空间进行更新。基于该朴素的逻辑,LORA降低大模型的fineturn门槛,模型训练时不需…
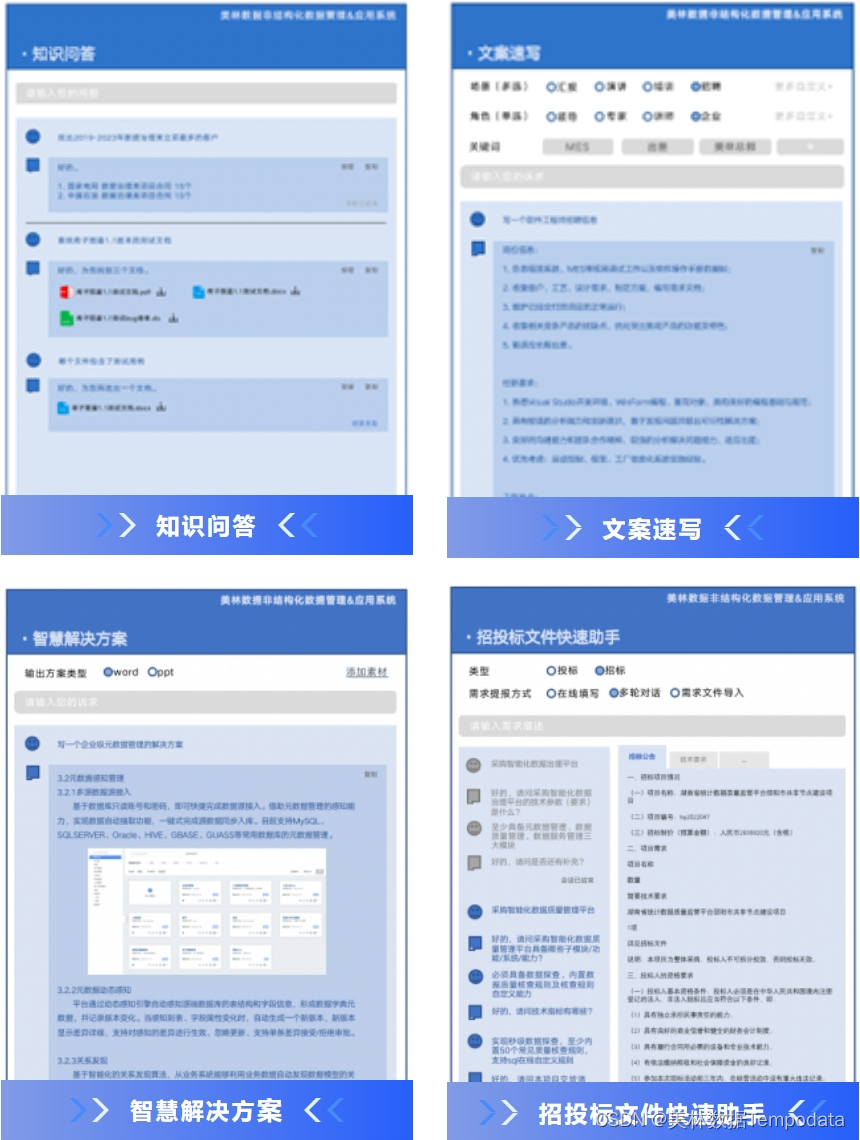
利用大模型知识图谱技术,告别繁重文案,实现非结构化数据高效管理
我,作为一名产品经理,对文案工作可以说是又爱又恨,爱的是文档作为嘴替,可以事事展开揉碎讲清道明;恨的是只有一个脑子一双手,想一边澄清需求一边推广宣传一边发布版本一边申报认证实在是分身乏术࿰…

大模型chatgpt4分析功能初探
大模型chatgpt4分析功能初探
目录
1、探测目的
2、目标变量分析
3、特征缺失率处理
4、特征描述性分析
5、异常值分析
6、相关性分析
7、高阶特征挖掘
1、探测目的
1、分析chat4的数据分析能力,提高部门人效
2、给数据挖掘提供思路
3、原始数据…
大模型从入门到应用——LangChain:代理(Agents)-[代理执行器(Agent Executor):处理解析错误、访问中间步骤和限制最大迭代次数]
分类目录:《大模型从入门到应用》总目录
LangChain系列文章:
基础知识快速入门 安装与环境配置链(Chains)、代理(Agent:)和记忆(Memory)快速开发聊天模型 模型(Models&…
大模型lora微调-chatglm2
通义千问大模型微调源码(chatglm2 微调失败,训练通义千问成功):GitHub - hiyouga/LLaMA-Efficient-Tuning: Easy-to-use LLM fine-tuning framework (LLaMA-2, BLOOM, Falcon, Baichuan, Qwen, ChatGLM2)Easy-to-use LLM fine-tun…

倒计时15天!百度世界2023抢先看
近日消息,在10月17日即将举办的百度世界2023上,百度创始人、董事长兼首席执行官李彦宏将带来主题演讲,“手把手教你做AI原生应用”。 增设社会报名,有机会获得精美伴手礼
目前,百度世界大会已经开放公众参会报名&…
ChessLLM - 和 LLM 下棋
文章目录 关于 ChessLLM安装使用 关于 ChessLLM
Play chess against large language models.
github : https://github.com/carlini/chess-llm线上对战:https://lichess.org
这是一个与大型语言模型(LLM)对弈的项目。 目前它只支持OpenAI …

仅用61行代码,你也能从零训练大模型
本文并非基于微调训练模型,而是从头开始训练出一个全新的大语言模型的硬核教程。看完本篇,你将了解训练出一个大模型的环境准备、数据准备,生成分词,模型训练、测试模型等环节分别需要做什么。AI 小白友好~文中代码可以直接实操运…
快上车,LLM专列:想要的资源统统给你准备好了
如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
(嘿嘿,有点标题党了。最近整理了LLM相关survey、开源数据、开源代码等等资源,后续会不断丰富内容,省略大家找资料浪费时间。闲言少叙,正式发车&a…
超美!ChatGPT DALL-E 3已可用,另外GPT-4可上传图片进行问答
今天,在ChatGPT里使用DALL-E 3的功能终于上线了。以下是截图: 在GPT-4下加了一个菜单入口,名为 DALL-E 3,这也意味着ChatGPT免费账户暂时不能使用这个功能。
我们体验一下这个功能。
技术交流
建了技术交流群!想要进…

GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
GPT实战系列-ChatGLM2部署UbuntuCuda11显存24G实战方案
自从chatGPT掀起的AI大模型热潮以来,国内大模型研究和开源活动,进展也如火如荼。模型越来越大,如何在小显存部署和使用大模型?
本实战专栏将评估一系列的开源模型…

【论文精读】NMP: End-to-end Interpretable Neural Motion Planner
toc
1 背景信息
团队:Uber,多伦大大学 年份:2019 论文链接:https://arxiv.org/abs/2101.06679
2 Motivation
深度学习方案受限于累积误差suffers from the compounding error,而且可解释性差interpretability is d…
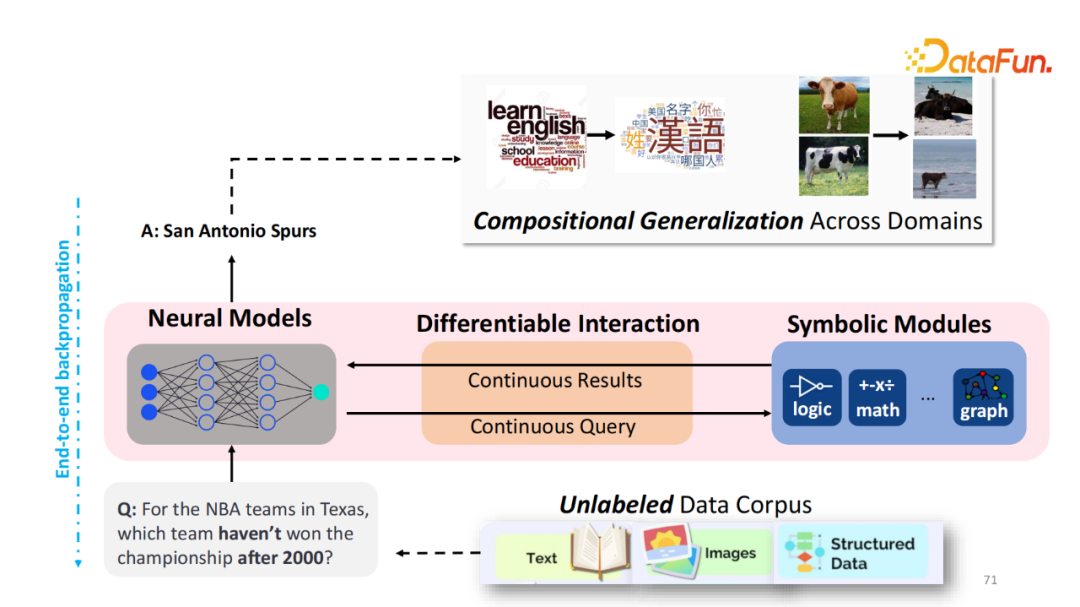
如何让大模型自由使用外部知识与工具
本文将分享为什么以及如何使用外部的知识和工具来增强视觉或者语言模型。
全文目录:
1. 背景介绍 OREO-LM: 用知识图谱推理来增强语言模型 REVEAL: 用多个知识库检索来预训练视觉语言模型 AVIS: 让大模型用动态树决策来调用工具
技术交流群
建了技术交流群&a…
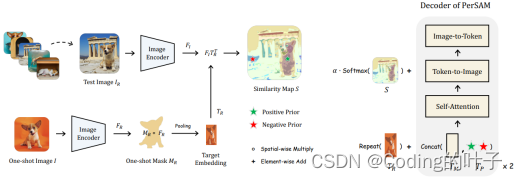
【视觉大模型SAM系列】PerSAM:Personalize Segment Anything Model with One Shot
【版权声明】 本文为博主原创文章,未经博主允许严禁转载,我们会定期进行侵权检索。 更多算法总结请关注我的博客:https://blog.csdn.net/suiyingy,或”乐乐感知学堂“公众号。 本文章来自于专栏《大模型》的系列文章,专…

【LLM模型篇】LLaMA2 | Vicuna | EcomGPT等(更新中)
文章目录 一、Base modelchatglm2模型Vicuna模型LLaMA2模型1. 训练细节2. Evaluation Results3. 更多参考 alpaca模型其他大模型和peft高效参数微调二、垂直领域大模型MedicalGPT:医疗大模型TransGPT:交通大模型EcomGPT:电商领域大模型1. s…
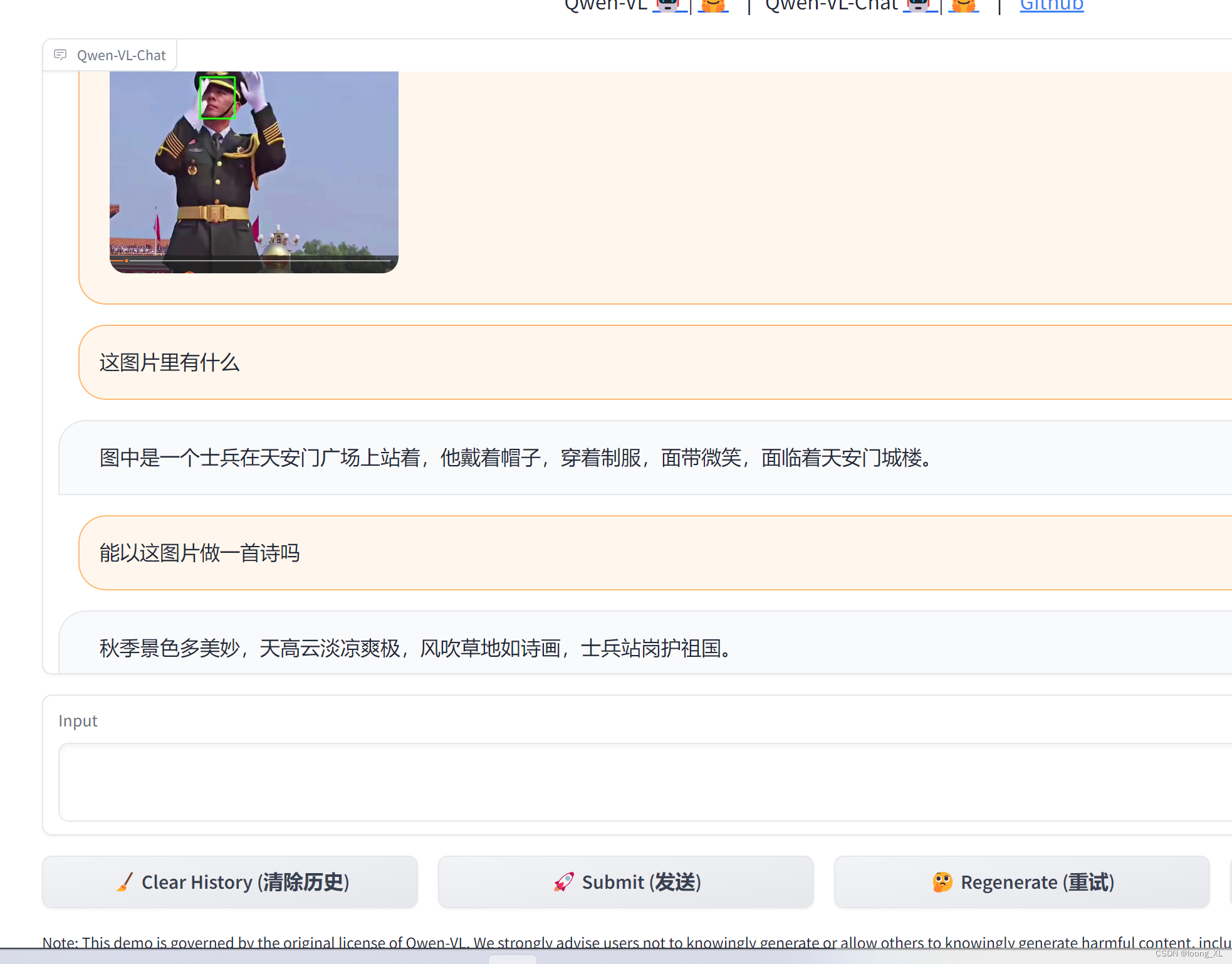
阿里 通义千问LLM Qwen-7B-Chat与Qwen-VL-Chat 使用
参考: https://github.com/QwenLM/Qwen-7B https://github.com/QwenLM/Qwen-VL
下载模型: https://huggingface.co/Qwen
1、Qwen-7B-Chat
下载好代码与模型后运行:
python ./Qwen-7B-main/web_demo.py -c ./qwen-6b-4bit/ --server-name…

超全总结!大模型算法面试指南(含答案)
大家好,从 2019 年的谷歌 T5 到 OpenAI GPT 系列,参数量爆炸的大模型不断涌现。可以说,LLMs 的研究在学界和业界都得到了很大的推进,尤其去年 11 月底对话大模型 ChatGPT 的出现更是引起了社会各界的广泛关注。
近些年࿰…

NeurIPS 23 Spotlight丨3D-LLM:将3D世界注入大语言模型
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/pdf/2307.12981.pdf
开源代码:https://vis-www.cs.umass.edu/3dllm/
摘要:
大型语言模型 (LLM) 和视觉语言模型 (VLM) 已被证明在多项任务上…
探索未来:大模型技术的最前沿
一、引言
随着人工智能技术的飞速发展,大模型(Large Model)技术日益受到广泛的关注。大模型,又称为巨型模型(Giant Model),是指参数量极其庞大的深度学习模型。其强大的性能和潜力在自然语言处…

【AI视野·今日NLP 自然语言处理论文速览 第五十八期】Thu, 19 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 19 Oct 2023 Totally 74 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Understanding Retrieval Augmentation for Long-Form Question Answering Authors Hung Ting Chen, Fangyuan…

零代码开发、可视化界面!飞桨AI Studio星河社区带你玩转Prompt应用
号外号外!飞桨AI Studio星河社区上线新版文心一言专区,帮助开发者完成一言插件&大模型应用开发,与此同时推出Prompt模板库供开发者使用。
零代码开发、可视化界面!飞桨AI Studio星河社区带你玩转Prompt应用

百度智能云千帆大模型平台再升级,SDK版本开源发布!
文章目录 1. SDK的优势2. 千帆SDK:快速落地LLM应用3. 如何快速上手千帆SDK3.1 SDK快速启动3.2 SDK进阶指引3.3 通过Langchain接入千帆SDK 4. 开源社区 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线Python SDK&#…
【网安大模型专题10.19】※论文5:ChatGPT+漏洞定位+补丁生成+补丁验证+APR方法+ChatRepair+不同修复场景+修复效果(韦恩图展示)
Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT 写在最前面背景介绍自动程序修复流程Process of APR (automated program repair)1、漏洞程序2、漏洞定位模块3、补丁生成4、补丁验证 (可以学习的PPT设计)经典的…
【大模型-第一篇】在阿里云上部署ChatGLM3
前言
好久没写博客了,最近大模型盛行,尤其是ChatGLM3上线,所以想部署试验一下。 本篇只是第一篇,仅仅只是部署而已,没有FINETUNE、没有Langchain更没有外挂知识库,所以从申请资源——>开通虚机——>…

PEFT概述:最先进的参数高效微调技术
了解参数高效微调技术,如LoRA,如何利用有限的计算资源对大型语言模型进行高效适应。 PEFT概述:最先进的参数高效微调技术 什么是PEFT什么是LoRA用例使用PEFT训练LLMs入门PEFT配置4位量化封装基础Transformer模型保存模型加载模型推理 结论 什…

大模型如何商业变现?小i机器人发布华藏大模型生态
华藏通用大模型生态体系由“113”三部分组分,即:一个能力基座一项产品支撑三项服务保障。 今年以来,市场上各类人工智能大模型如雨后春笋,但如何将大模型进行科学的商业变现,成为摆在行业面前的一道难题。在刚刚召开的…
在Win11上部署ChatGLM3详细步骤
023年10月27日,智谱AI于2023中国计算机大会(CNCC)上,推出了全自研的第三代基座大模型ChatGLM3及相关系列产品,这也是智谱AI继推出千亿基座的对话模型ChatGLM和ChatGLM2之后的又一次重大突破。此次推出的ChatGLM3采用了…
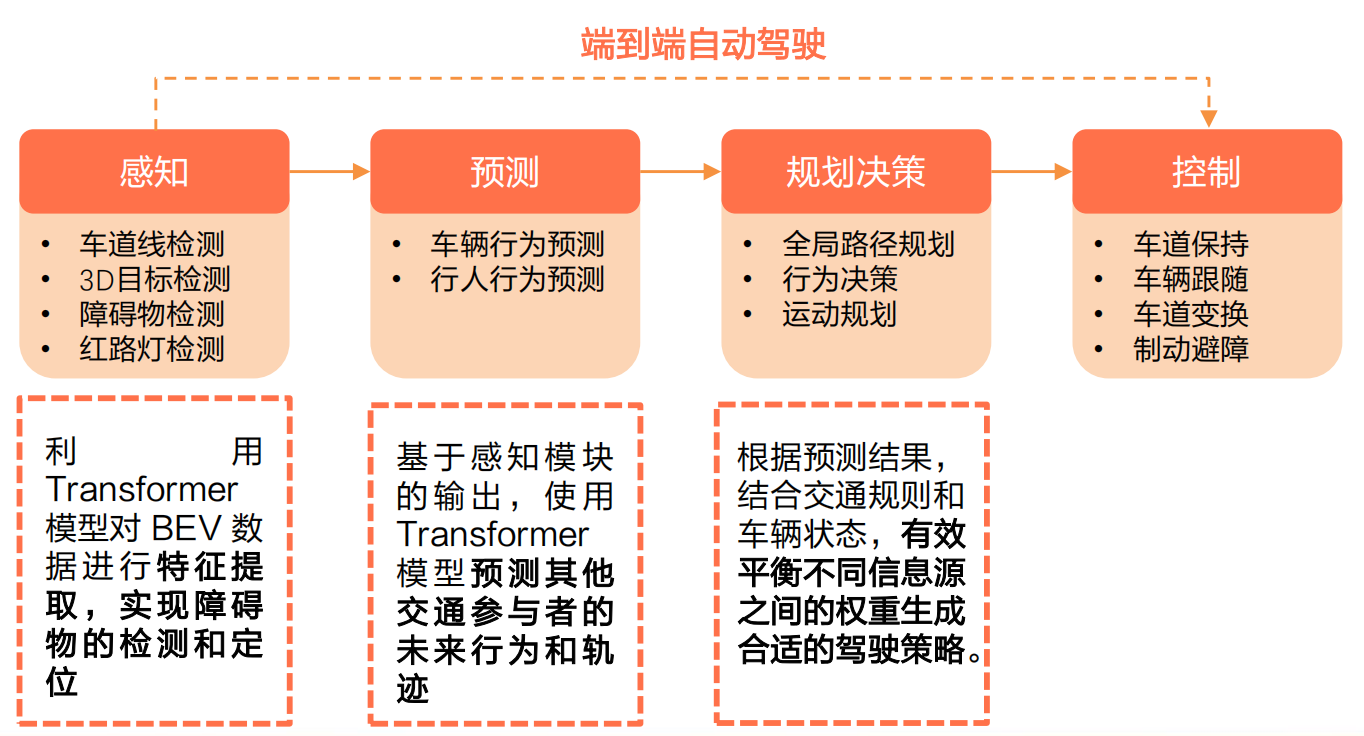
未来之路:大模型技术在自动驾驶的应用与影响
本文深入分析了大模型技术在自动驾驶领域的应用和影响,万字长文,慢慢观看~
文中首先概述了大模型技术的发展历程,自动驾驶模型的迭代路径,以及大模型在自动驾驶行业中的作用。接着,详细介绍了大模型的基本定义、基础功…
GPT实战系列-ChatGLM3部署CUDA11+1080Ti+显卡24G实战方案
目录
一、ChatGLM3 模型
二、资源需求
三、部署安装
配置环境
安装过程
低成本配置部署方案
四、启动 ChatGLM3
五、功能测试 新鲜出炉,国产 GPT 版本迭代更新啦~清华团队刚刚发布ChatGLM3,恰逢云栖大会前百川也发布Baichuan2-192K,一…
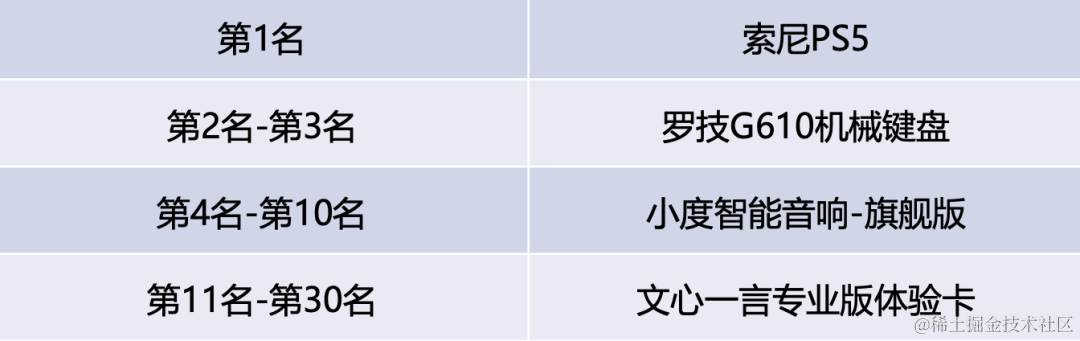
零代码Prompt应用大赛正式开始!飞桨星河社区五周年活动第一站
五周年盛典将至!抢发第一站!
在大模型时代,飞桨星河社区致力于让人人都成为大模型开发者!飞桨星河社区零代码应用开发工具链,帮助大家轻松实现灵感落地、场景化需求落地,助力每个人实现工作与生活的效能提…
推荐收藏!大模型算法工程师面试题来了(附答案)
自 ChatGPT 在去年 11 月底横空出世,大模型的风刮了整一年。
历经了百模大战、Llama 2 开源、GPTs 发布等一系列里程碑事件,将大模型技术推至无可争议的 C 位。基于大模型的研究与讨论,也让我们愈发接近这波技术浪潮的核心。
最近大模型相关…
【AIGC】认识AIGC
AIGC 初始篇 AIGC模型 AIGC模型 前段时间,AIGC模型很火, 特别是chatgpt横空出世,惊艳所有人,人工智能真的很智能.遗憾的是openai是不开源.作为一名想学习者,针对不开源的,门槛还是很高的.为止,了解了闭源的替代品,目前比较好的替代品如下: 开源ChatGPT替代模型项目整理ChatGPT的…
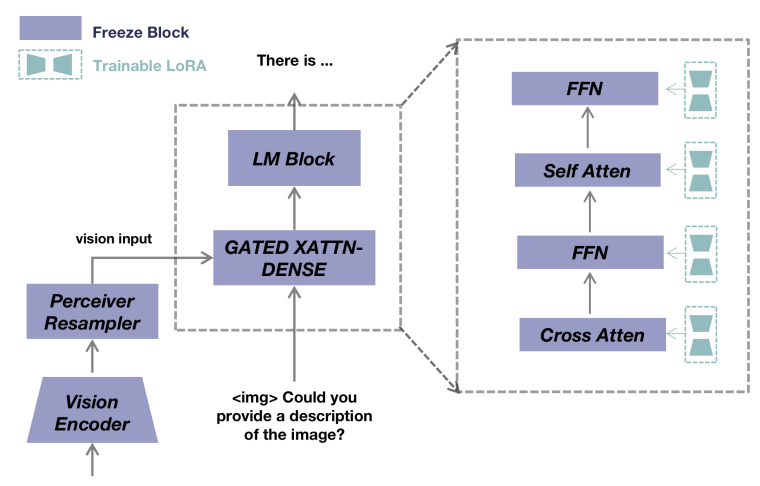
18种大模型指令调优方法分享,附模型源码
指令调优(IT),一种针对大型语言模型(LLMs)的训练方法,是提高大型语言模型能力和可控性的关键技术。该方法的核心目标是使LLM具备遵循自然语言指令并完成现实世界任务的能力。它弥补了LLM的下一个单词预测目…
经典算法-枚举法(百钱买百鸡问题)
题目:
条件:现有 100 元,一共要买公鸡、母鸡、小鸡三种鸡,已知公鸡 5 元一只,母鸡 3 元一只,1 元可以买三只小鸡。 要求:公鸡、母鸡、小鸡都要有,一共买 100 只鸡。有哪几种买法&am…
本地部署AutoGPT
我们都了解ChatGPT,是Openai退出的基于GPT模型的新一代 AI助手,可以帮助解决我们在多个领域的问题。但是你会发现,在某些问题上,ChatGPT 需要经过不断的调教与沟通,才能得到接近正确的答案。对于你不太了解的领域领域&…

“开源 vs. 闭源:大模型的未来发展趋势预测“——探讨大模型未来的发展方向
文章目录 每日一句正能量前言什么是大模型的开源与闭源开源与闭源的定义和特点开源的意义开源和闭源的优劣势比较不同的大模型企业,开源、闭源的策略不尽相同。企业在开发垂类模型时选择开源还是闭源大模型开源vs 闭源:两者并非选择题后记 每日一句正能量…

开源与闭源软件的辩论:对大模型技术发展的影响
目录 前言1 开源软件的优缺点1.1 开源软件的优点1.2 开源软件的缺点和挑战 2 闭源软件的优缺点2.1 闭源软件的优点2.2 闭源软件的缺点和挑战 3 大模型发展会走向哪一边结语 前言
近期,特斯拉CEO马斯克公开表示:OpenAI不该闭源,自家首款聊天机…

手把手带你用Python和文心一言搭建《AI看图写诗》网页项目(附上完整项目源码)
今年年初,ChatGPT的火爆在全球掀起AI大模型的开发热潮,国内外的科技公司纷纷加入“百模大战”行列。百度在率先发布了国内第一款人工智能大语言模型“文心一言”后,又推出了文心千帆大模型平台,帮助企业和开发者加速大模型应用落地…
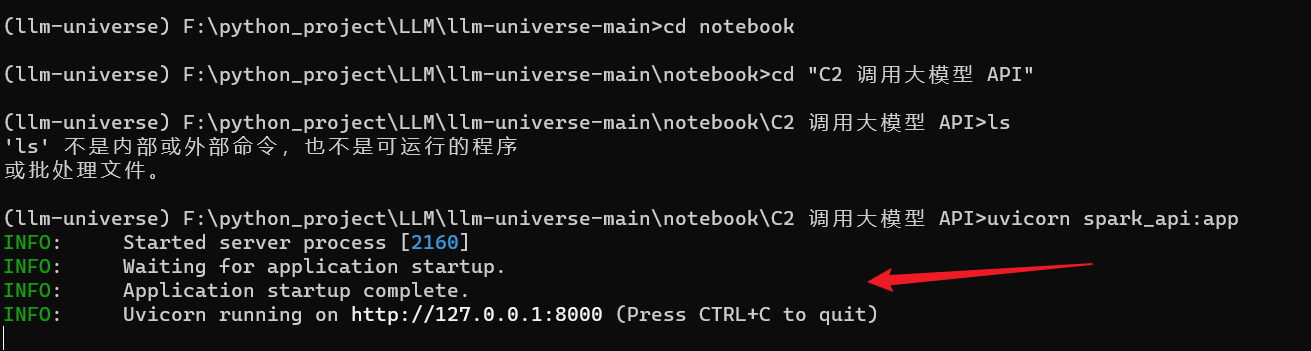
2.2 调用星火大模型的API
调用星火大模型的API 1 申请API调用权限:2 调用原生星火 API3 统一API调用方式 项目仓库地址:https://github.com/datawhalechina/llm-universe
讯飞星火认知大模型,由科大讯飞于2023年5月推出的中文大模型,也是国内大模型的代表…
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-如何使用P-Tuning本地化训练ChatGLM2等LLM模型?(二) 文章目录 GPT实战系列-1.训练参数配置传递2.训练前准备3.训练参数配置4.训练对象,seq2seq训练5.执行训练6.训练模型评估依赖数据集的预处理 P-Tuning v2 将 ChatGLM2-6B 模型需要微调的参…

大模型发展进入深水区,企业如何打造专属AI原生应用?
目录 📢前言 大模型发展进入深水区,企业如何打造专属AI原生应用?一、人工智能领域发展现状及行业特点二、百度GBI 的诞生三、百度GBI的特点和优势四、百度GBI的作用及应用场景五、 重磅发布“千帆AI原生应用开发工作台”六、千帆AI原生应用开…

作为一个初学者,该如何入门大模型?
在生成式 AI 盛行的当下,你是否被这种技术所折服,例如输入一段简简单单的文字,转眼之间,一幅精美的图片,又或者是文笔流畅的文字就展现在你的面前。
相信很多人有这种想法,认为生成式 AI 深不可测…
我的大语言模型微调踩坑经验分享
由于 ChatGPT 和 GPT4 兴起,如何让人人都用上这种大模型,是目前 AI 领域最活跃的事情。当下开源的 LLM(Large language model)非常多,可谓是百模大战。面对诸多开源本地模型,根据自己的需求,选择…

又一大语言模型上线!一次可读35万汉字!
国内大模型创业公司,正在技术前沿创造新的记录。10 月 30 日,百川智能正式发布 Baichuan2-192K 长窗口大模型,将大语言模型(LLM)上下文窗口的长度一举提升到了 192K token。
这相当于让大模型一次处理约 35 万个汉字&…

基于Fuzzing和ChatGPT结合的AI自动化测试实践分享
一、前言
有赞目前,结合insight接口自动化平台、horizons用例管理平台、引流回放平台、页面比对工具、数据工厂等,在研发全流程中,已经沉淀了对应的质量保障的实践经验,并在逐渐的进化中。
在AI能力大幅进步的背景下,…
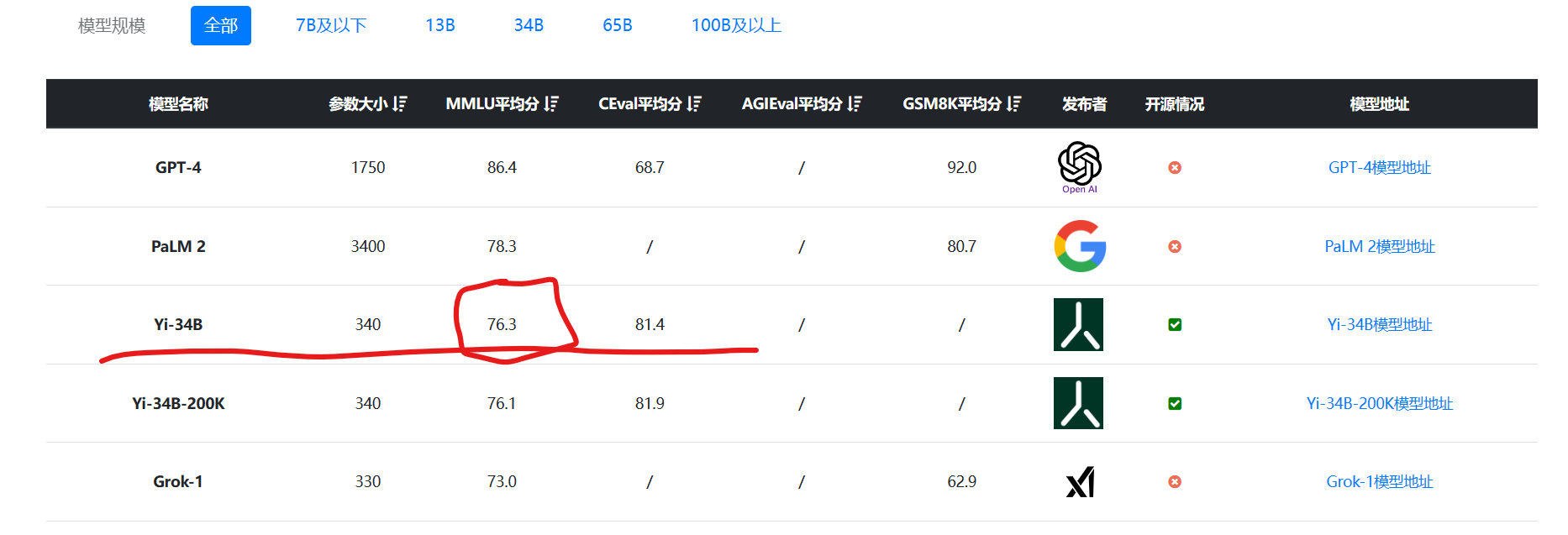
李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文
本文来自DataLearnerAI官方网站:李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文 | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699285770532
零一万物(01.AI…
(三)、基于 LangChain 实现大模型应用程序开发 | 模型链 Chains
😄 为什么我们需要Chains ?
链允许我们将多个组件组合在一起,以创建一个单一的、连贯的应用程序。链(Chains)通常将一个LLM(大语言模型)与提示结合在一起,使用这个构建块࿰…

2023年11月中旬大模型新动向集锦
2023年11月中旬大模型新动向集锦
2023.11.21版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、谷歌生成式 AI 搜索生成体验(SGE)扩展到 120 多个新国家/地区
近日,Google 扩展了其由生成式人工智能驱…

大模型创业“风投”正劲,AGI Foundathon 大模型创业松活动精彩看点
这是一场万众瞩目的大模型领域盛会。当来自世界各地的顶尖大模型开发者、创业者、投资人汇聚一堂,他们对大模型应用层的思考碰撞出了哪些火花?应运而生了哪些令人眼前一亮的AI-Native产品? 让我们一起来回顾吧~

Talk | PSU助理教授吴清云:AutoGen-用多智能体对话开启下一代大型语言模型应用
本期为TechBeat人工智能社区第548期线上Talk! 北京时间11月21日(周二)20:00,宾夕法尼亚州立大学助理教授—吴清云的Talk已准时在TechBeat人工智能社区开播! 她与大家分享的主题是: “ AutoGen:用多智能体对话开启下一代大型语言模…

【LLM】chatglm3的agent应用和微调实践
note
知识库和微调并不是冲突的,它们是两种相辅相成的行业解决方案。开发者可以同时使用两种方案来优化模型。例如: 使用微调的技术微调ChatGLM3-6B大模型模拟客服的回答的语气和基础的客服思维。接着,外挂知识库将最新的问答数据外挂给Chat…
10分钟构建本地知识库,让 ChatGPT 更加懂你
大家好,本文将从零开始构建本地知识库,从而辅助 ChatGPT 基于知识库内容生成回答。
这里再重复下部分核心观点: 向量:将人类的语言(文字、图片、视频等)转换为计算机可识别的语言(数组…
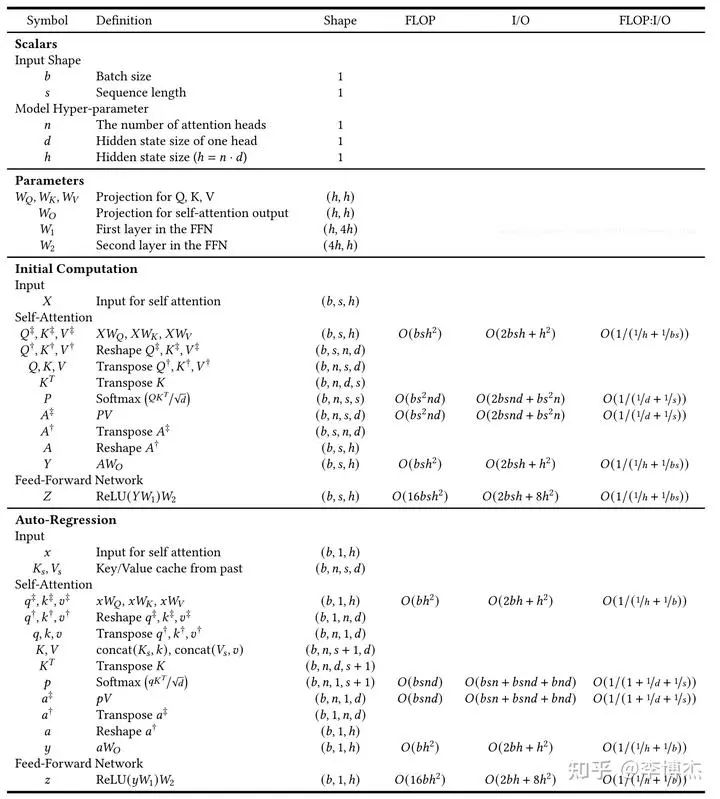
大模型训练为什么用A100不用4090
这是一个好问题。先说结论,大模型的训练用 4090 是不行的,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
事实上&#x…
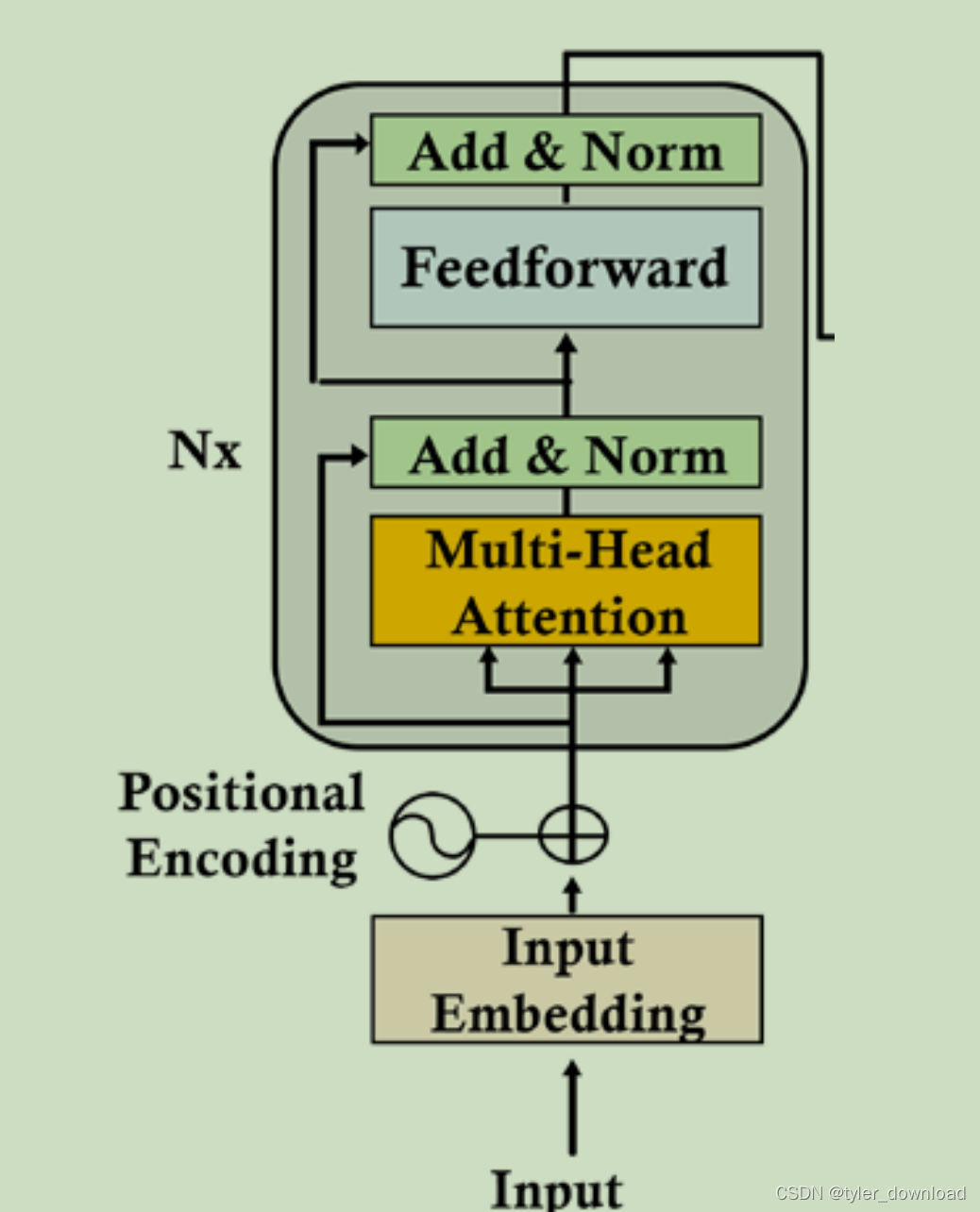
自己动手写 chatgpt: Attention 机制的原理与实现
chatgpt等大模型之所以成功都有赖于一种算法突破,那就是 attention 机制。这种机制能让神经网络更有效的从语言中抽取识别其内含的规律,同时它支持多路并行运算,因此相比于原来的自然语言处理算法,它能够通过并发的方式将训练的速…
【LM、LLM】浅尝二叉树在前馈神经网络上的应用
前言
随着大模型的发展,模型参数量暴涨,以Transformer的为组成成分的隐藏神经元数量增长的越来越多。因此,降低前馈层的推理成本逐渐进入视野。前段时间看到本文介绍的相关工作还是MNIST数据集上的实验,现在这个工作推进到BERT上…

使用 huggingface_hub 镜像下载 大模型
download.py 👇
import os
# 配置 hf镜像
os.environ[HF_ENDPOINT] https://hf-mirror.com# 设置保存的路径
local_dir "XXXXXX"# 设置仓库id
model_id "sensenova/piccolo-large-zh"cmd f"huggingface-cli download --resume-downlo…

中国团队开源大规模高质量图文数据集ShareGPT4V
中国团队最近开源了一个引人瞩目的图文数据集,命名为ShareGPT4V,它基于GPT4-Vision构建,训练了一个7B模型。这一举措在多模态领域取得了显著的进展,超越了同级别的模型。
该数据集包含了120万条图像-文本描述数据,涵盖…
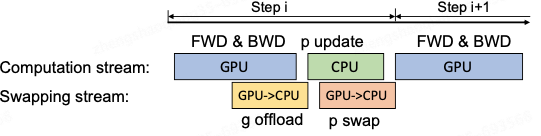
DeepSpeed: 大模型训练框架 | 京东云技术团队
背景:
目前,大模型的发展已经非常火热,关于大模型的训练、微调也是各个公司重点关注方向。但是大模型训练的痛点是模型参数过大,动辄上百亿,如果单靠单个GPU来完成训练基本不可能。所以需要多卡或者分布式训练来完成这…

05.大模型大数据量
文章目录 大模型顿悟时刻:Emergent Ability(涌动现象)Calibration Inverse Scaling PrizeSwitch Transformers 大数据量数据预处理去重 模型大小与训练数据的选择Instruction-tuningHuman TeachingKNN LM 部分截图来自原课程视频《2023李宏毅…
关于生成式人工智能模型应用的调研
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题:A survey of Generative AI Applications
链接:https://arxiv.org/abs/2306.02781
摘要
生成式人工智能(Generative AI)近年来经历了显著的增长&…
关于大模型在文本分类上的尝试
文章目录 前言所做的尝试总结前言
总共25个类别,在BERT上的效果是48%,数据存在不平衡的情况,训练数据分布如下: 训练数据不多,4000左右
所做的尝试
1、基于 Qwen-14b-base 做Lora SFT,Loss忘记记录
准确率在68%左右
Lora配置
class LoraArguments:lora_r: int = 64…
【tips】huggingface下载模型权重的方法
文章目录 方法1:直接在Huggingface上下载,但是要fanqiang,可以git clone或者在代码中:
from huggingface_hub import snapshot_download
# snapshot_download(repo_id"decapoda-research/llama-7b-hf")
snapshot_downl…

【DevChat】智能编程助手 - 使用评测
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-如何用自己数据微调ChatGLM2模型训练 目录 GPT实战系列-如何用自己数据微调ChatGLM2模型训练1、训练数据广告文案生成模型训练和测试数据组织: 2、训练脚本3、执行训练调整运行 4、问题解决问题一问题二问题三问题四 1、训练数据
广告文案生成模型
输…

大模型问答助手前端实现打字机效果 | 京东云技术团队
1. 背景
随着现代技术的快速发展,即时交互变得越来越重要。用户不仅希望获取信息,而且希望以更直观和实时的方式体验它。这在聊天应用程序和其他实时通信工具中尤为明显,用户习惯看到对方正在输入的提示。
ChatGPT,作为 OpenAI …
实战案例:chatglm3 基础模型多轮对话微调
chatglm3 发布了,这次还发了base版本的模型,意味着我们可以基于这个base模型去自由地做SFT了。
本项目实现了基于base模型的SFT。
base模型
https://huggingface.co/THUDM/chatglm3-6b-base由于模型较大,建议离线下载后放在代码目录&#…
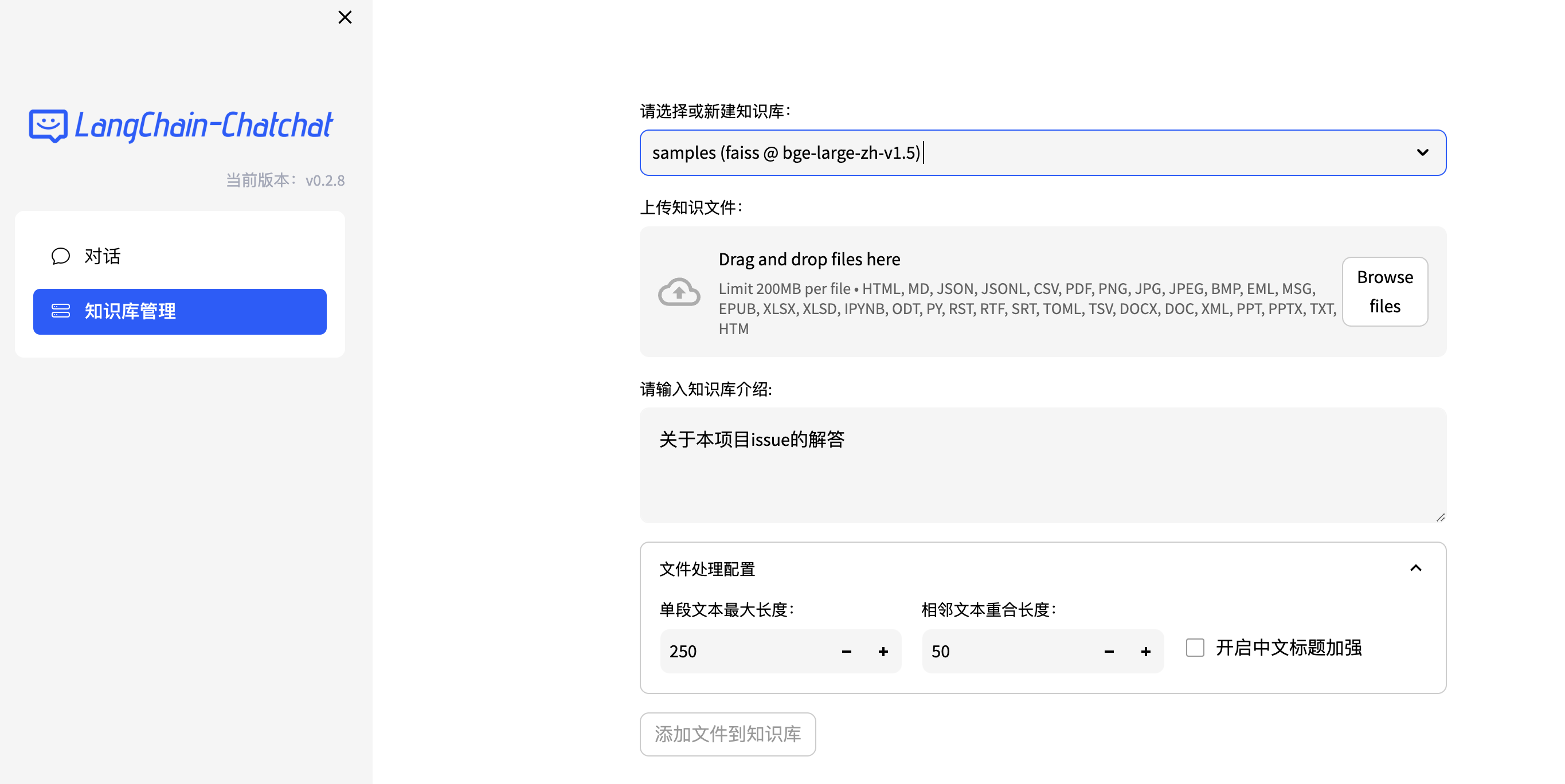
用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统
之前写了一篇文章介绍基于 LangChain 和 ChatGLM 打造自有知识库问答系统,最近该项目更新了0.2新版本,这个版本与之前的版本差别很大,底层的架构发生了很大的变化。
该项目最早是基于 ChatGLM 这个 LLM(大语言模型)来…
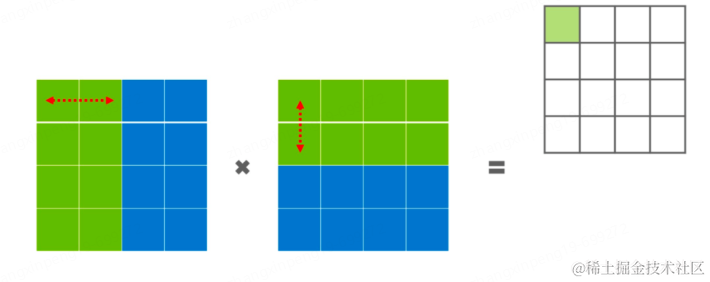
聊一聊大模型 | 京东云技术团队
事情还得从ChatGPT说起。
2022年12月OpenAI发布了自然语言生成模型ChatGPT,一个可以基于用户输入文本自动生成回答的人工智能体。它有着赶超人类的自然对话程度以及逆天的学识。一时间引爆了整个人工智能界,各大巨头也纷纷跟进发布了自家的大模型&#…

GPT实战系列-Baichuan2等大模型的计算精度与量化
GPT实战系列-Baichuan2等大模型精度与量化
不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,也耗费大量的训练时间…

LangChain+通义千问+AnalyticDB向量引擎保姆级教程
本文以构建AIGC落地应用ChatBot和构建AI Agent为例,从代码级别详细分享AI框架LangChain、阿里云通义大模型和AnalyticDB向量引擎的开发经验和最佳实践,给大家快速落地AIGC应用提供参考。
前言
通义模型具备的能力包括:
1.创作文字…
Stable Diffusion (version x.x) 文生图模型实践指南
前言:本篇博客记录使用Stable Diffusion模型进行推断时借鉴的相关资料和操作流程。 相关博客: 超详细!DALL E 文生图模型实践指南 DALLE 2 文生图模型实践指南 目录 1. 环境搭建和预训练模型准备环境搭建预训练模型下载 2. 代码 1. 环境搭建…
总结|哪些平台有大模型知识库的Web API服务
截止2023/12/6 笔者个人的调研,有三家有大模型知识库的web api服务:
平台类型文档数量文档上传并解析的结构api情况返回页码文心一言插件版多文档有问答api,文档上传是通过网页进行上传有,而且是具体的chunk id,需要设…

EMNLP 2023 | DeepMind提出大模型In-Context Learning的可解释理论框架
论文题目:In-Context Learning Creates Task Vectors 论文链接:https://arxiv.org/abs/2310.15916 01. 引言 此外,作者也提到本文的方法与软提示(soft-prompt)[1]方法类似,soft-prompt也是通过调整大模型内…
2024年生成式人工智能发展预测
2024年生成式人工智能发展预测
2023.12.9版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
当前,生成式人工智能(Generative AI,后面简称 Gen AI)领域不但在持续演进,而且它正在彻…
大模型训练数据集汇总
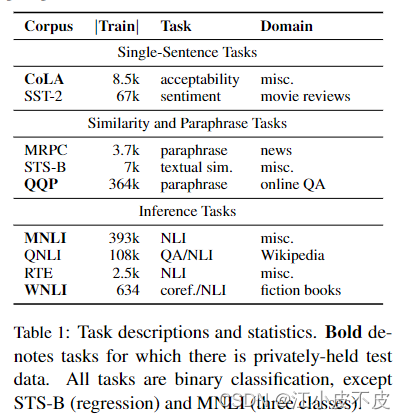
大模型训练数据集汇总 LLM数据集总结GLUE简介任务数据集大小 SQuAD简介任务数据集大小下载地址 XSUM简介下载地址 LLM数据集总结
GLUE
简介 当前大多数以上词级别的NLU模型都是针对特定任务设计的,而针对各种任务都能执行的通用模型尚未实现。为了解决这个问题&am…
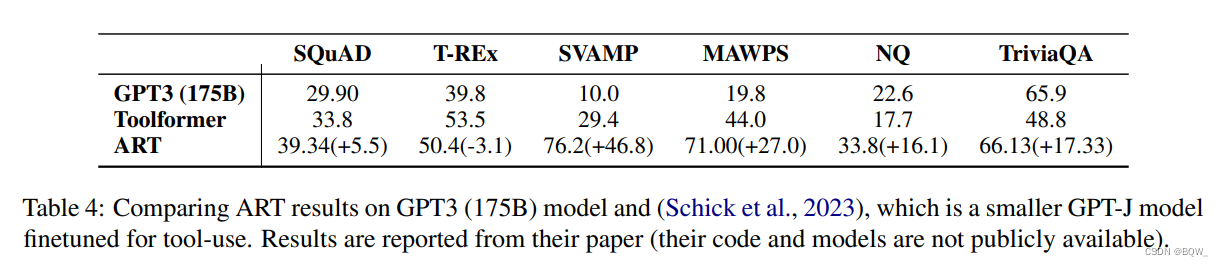
【自然语言处理】【大模型】赋予大模型使用工具的能力:Toolformer与ART
赋予大模型使用工具的能力:Toolformer与ART 本文介绍两种赋予大模型使用外部工具能力的方法:Toolformer和ART。
Toolformer论文地址:https://arxiv.org/pdf/2302.04761.pdf
ART论文地址:https://arxiv.org/pdf/2303.09014.pd…

CNCC 2023 | 大模型全面革新推荐系统!产学界多位大咖精彩献言
随着人工智能领域的不断突破,大模型的潮流已然席卷而来。大模型一跃成为时代的新宠,展现出强大的通用性和泛化能力,为 AI 技术的应用进一步打开了想象空间。与此同时,推荐系统作为大规模机器学习算法应用较为成熟的方向之一&#…
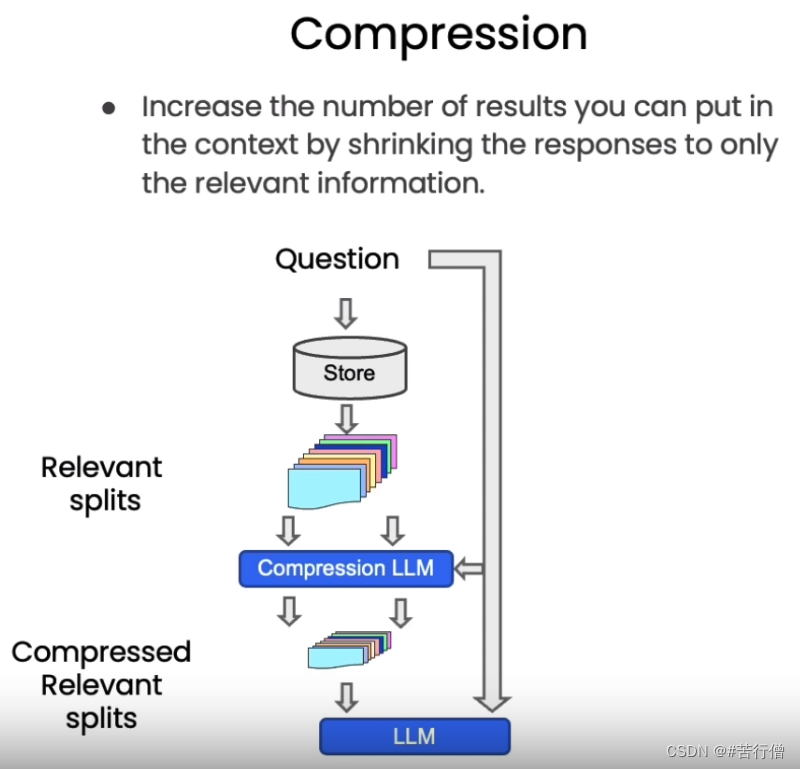
(八)、基于 LangChain 实现大模型应用程序开发 | 基于知识库的个性化问答 (检索 Retrieval)
检索增强生成(RAG)的整体工作流程如下: 在构建检索增强生成 (RAG) 系统时,信息检索是核心环节。检索是指根据用户的问题去向量数据库中搜索与问题相关的文档内容,当我们访问和查询向量数据库时可能会运用到如下几种技术…

已经有多人中招,不要被AI换脸技术骗了!
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…

马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文!
本文原文来自DataLearnerAI官方网站:
马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699114783001
马斯克透露xAI…

【论文精读】PlanT: Explainable Planning Transformers via Object-Level Representations
1 基本信息
院校:德国的图宾根大学 网站:https://www.katrinrenz.de/plant
2 论文背景
2.1 现有问题
现在的基于学习的方法使用高精地图和BEV,认为准确的(达到像素级的pixel-level)场景理解是鲁棒的输出的关键。re…

(六)、基于 LangChain 实现大模型应用程序开发 | 基于知识库的个性化问答 (文档分割 Splitting)
在上一章中,我们刚刚讨论了如何将文档加载到标准格式中,现在我们要谈论如何将它们分割成较小的块。这听起来可能很简单,但其中有很多微妙之处会对后续工作产生重要影响。 文章目录 1、为什么要做文档分割?2、文档分割方式3、基于…

AI生图王者之战!深度体验实测,谁是真正的艺术家?
10月11日凌晨,设计软件巨头Adobe宣布推出一系列图像生成模型,其中Firefly Image 2作为新一代图像生成器,通过改善皮肤、头发、眼睛、手和身体结构增强了人体渲染质量,提供更好的色彩和改进的动态范围,并为用户提供更大…
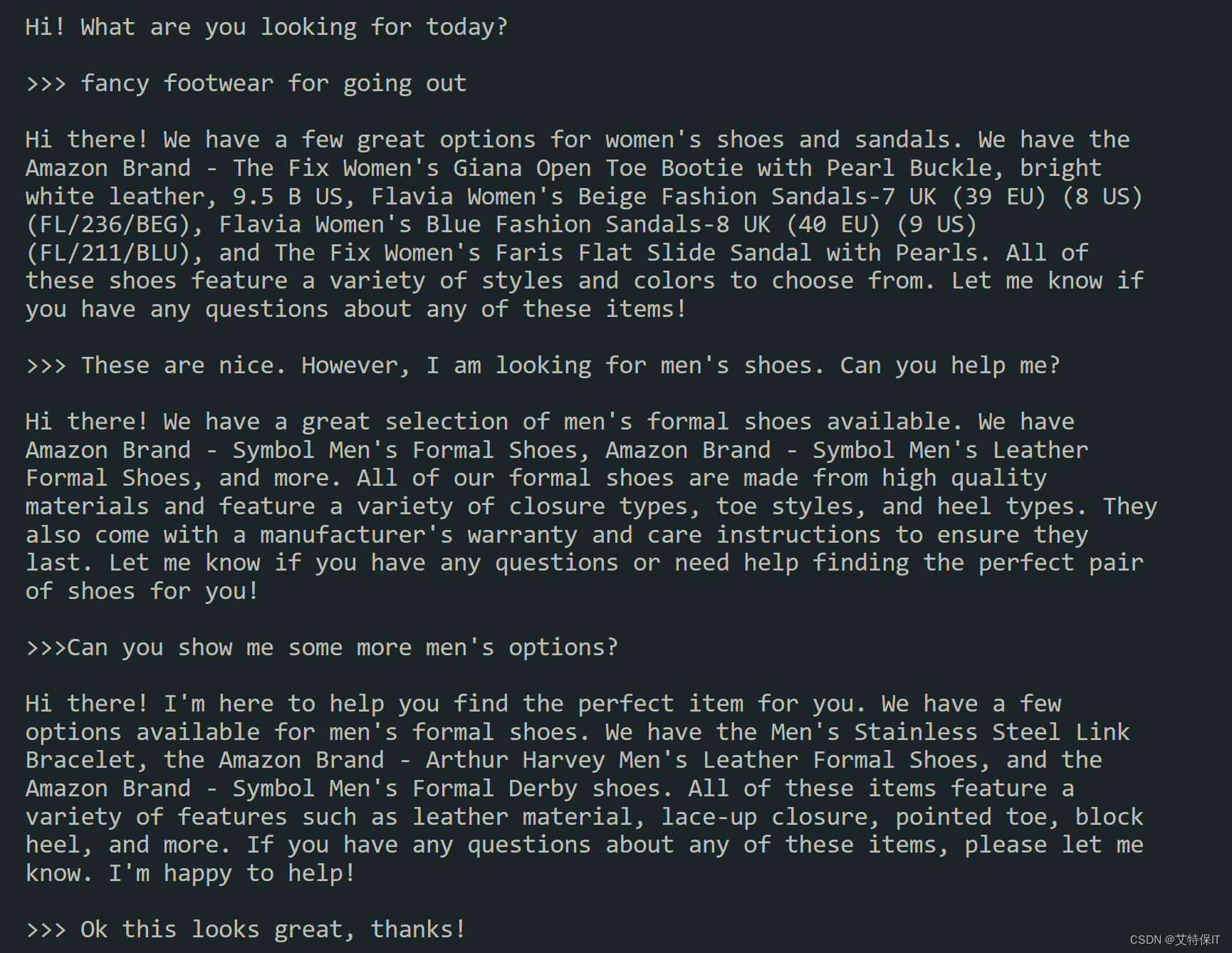
【虹科分享】基于Redis Enterprise,LangChain,OpenAI 构建一个电子商务聊天机器人
如何构建你自己的商务聊天机器人?注意哦,是你自己的聊天机器人。一起来看看Redis Enterprise的向量检索是怎么帮你实现这个愿望的吧。
鉴于最近人工智能支持的API和网络开发工具的激增,似乎每个人都在将聊天机器人集成到他们的应用程序中。 …
大模型下开源文档解析工具总结及技术思考
1 基于文档解析工具的方法
pdf解析工具
导图一览: PyPDF2提取txt: import PyPDF2
def extract_text_from_pdf(pdf_path):with open(pdf_path, rb) as file:pdf_reader PyPDF2.PdfFileReader(file)num_pages pdf_reader.numPagestext ""f…
Llama 架构分析
从代码角度进行Llama 架构分析 Llama 架构分析前言Llama 架构分析分词网络主干DecoderLayerAttentionMLP 下游任务因果推理文本分类 Llama 架构分析
前言 Meta 开发并公开发布了 Llama系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参…
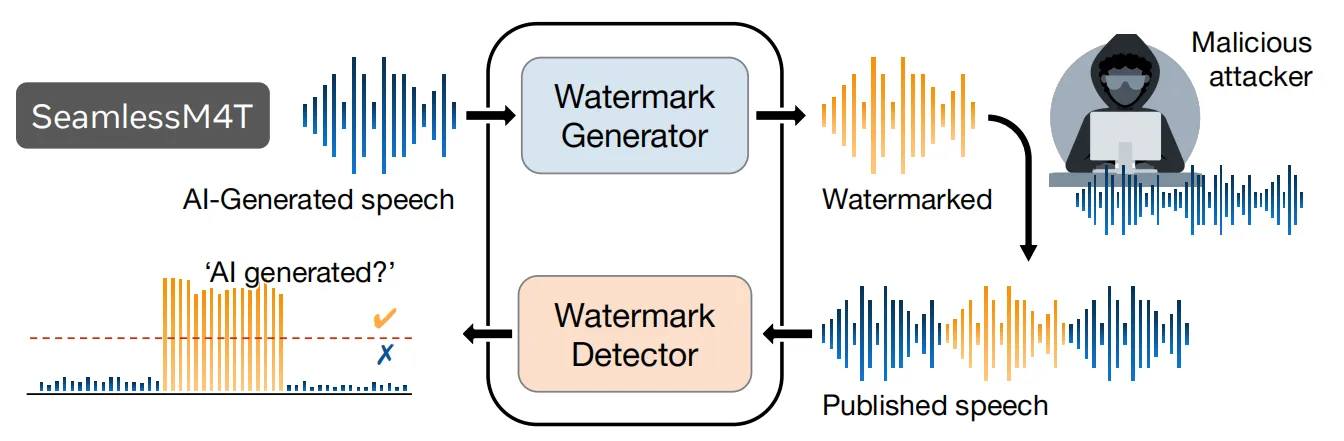
MetaAI语音翻译大模型Seamless登场,主打AI无缝同声传译
论文题目: Seamless: Multilingual Expressive and Streaming Speech Translation 论文链接: https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/ 代码链接: GitHub - facebook…
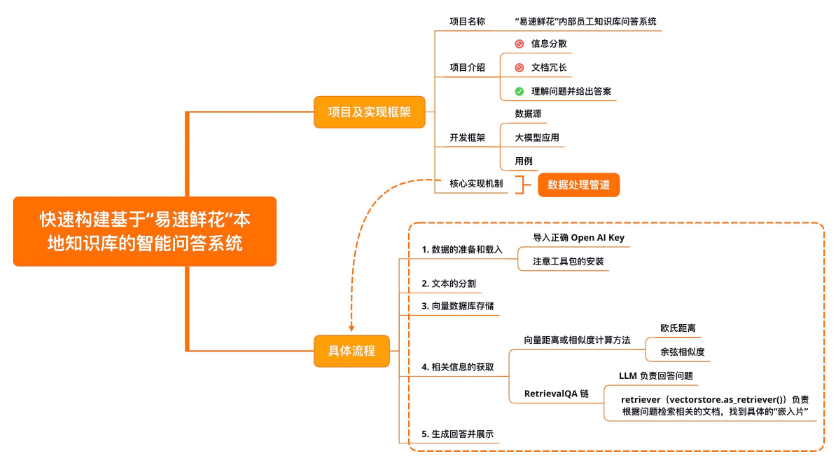
【LangChain学习之旅】—(3) LangChain快速构建本地知识库的智能问答系统
【LangChain学习之旅】—(3) LangChain快速构建本地知识库的智能问答系统 项目及实现框架开发框架核心实现机制数据准备及加载加载文本文本的分割向量数据库存储文本的“嵌入”概念向量数据库概念 相关信息获取RetrievalQA生成回答并展示示例小结 Refere…
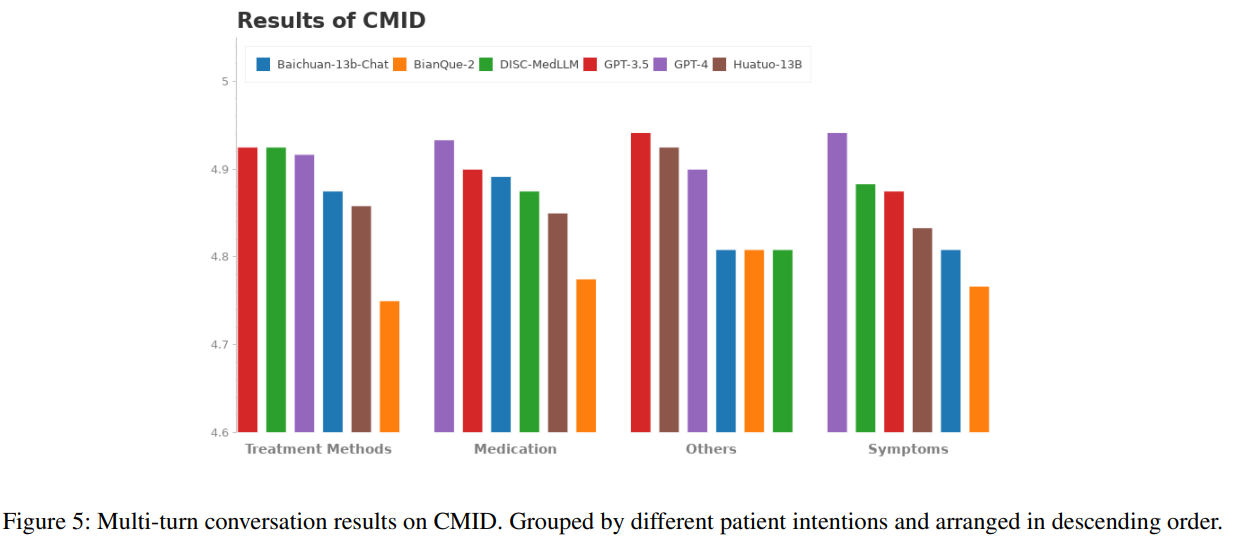
DISC-MedLLM—中文医疗健康助手
文章目录 DISC-MedLLM 项目介绍数据集构建重构AI医患对话知识图谱生成问答对医学图谱构建图谱生成QA对 人类偏好引导的对话样例其他数据MedMCQA通用数据 模型微调评估评估方式评估结果 总结 DISC-MedLLM 项目介绍
DISC-MedLLM 是一个专门针对医疗健康对话式场景而设计的医疗领…
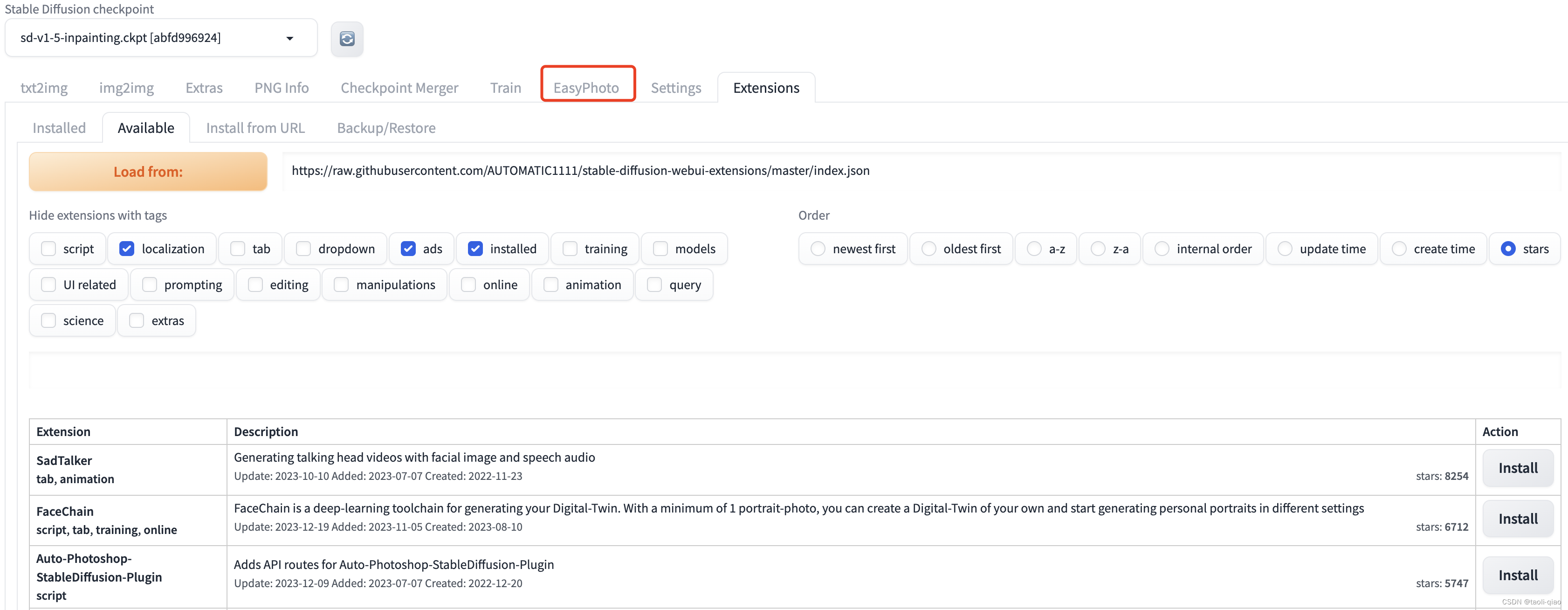
Stable-diffusion-webui本地部署和简要介绍
Stable Diffusion 是一款基于人工智能技术开发的绘画软件,它可以帮助艺术家和设计师快速创建高品质的数字艺术作品。是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,同时也可以应用于其他任务,如内补绘制、…

【大模型】快速体验百度智能云千帆AppBuilder搭建知识库与小助手
文章目录 前言千帆AppBuilder什么是千帆AppBuilderAppBuilder能做什么 体验千帆AppBuilderJava知识库高考作文小助手 总结 前言
前天,在【百度智能云智算大会】上,百度智能云千帆AppBuilder正式开放服务。这是一个AI原生应用开发工作台,可以…

大模型背景下计算机视觉年终思考小结(一)
1. 引言
在过去的十年里,出现了许多涉及计算机视觉的项目,举例如下:
使用射线图像和其他医学图像领域的医学诊断应用使用卫星图像分析建筑物和土地利用率相关应用各种环境下的目标检测和跟踪,如交通流统计、自然环境垃圾检测估计…

自然语言处理(NLP):理解语言,赋能未来
目录 前言1 什么是NLP2 NLP的用途3 发展历史4 NLP的基本任务4.1 词性标注(Part-of-Speech Tagging)4.2 命名实体识别(Named Entity Recognition)4.3 共指消解(Co-reference Resolution)4.4 依存关系分析&am…

分布式训练通信NCCL之Ring-Allreduce详解
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…

WAVE SUMMIT迎来第十届,文心一言将有最新披露!
10句话2分钟,挑战成功说服宿管阿姨开门,这个人群中的“显眼包”是一个接入文心大模型4.0游戏里的NPC,妥妥 “工具人”实锤~
尝试用AI一键自动识别好坏咖啡豆,看一眼便知好坏,真正“颜值即正义”࿰…
模型量化之AWQ和GPTQ
什么是模型量化
模型量化(Model Quantization)是一种通过减少模型参数表示的位数来降低模型计算和存储开销的技术。一般来说,模型参数在深度学习模型中以浮点数(例如32位浮点数)的形式存储,而模型量化可以…

PyTorch 进阶指南,10个必须知道的原则
PyTorch 是一种流行的深度学习框架,它提供了强大的工具和灵活的接口,使得开发者能够搭建和训练各种神经网络模型。这份指南旨在为开发者提供一些有用的原则,以帮助他们在PyTorch中编写高效、可维护和可扩展的代码。
如果你对 Pytorch 还处于…
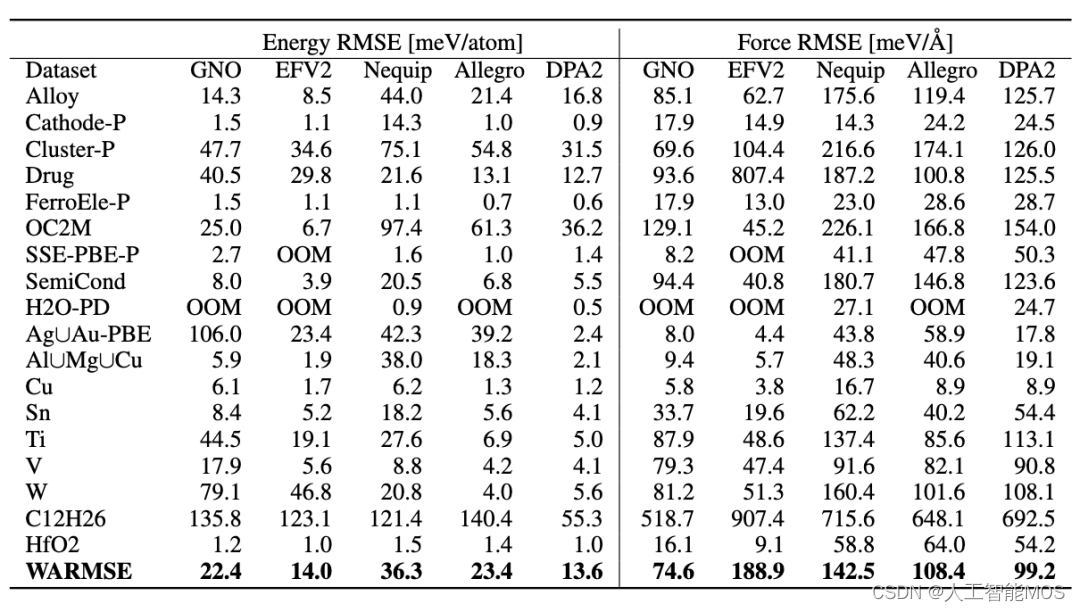
OpenLAM | 深度势能预训练大模型DPA-2发布
在迈向通用大原子模型(Large Atomic Model,LAM)的征途上,深度势能核心开发者团队面向社区,发起 OpenLAM 大原子模型计划。OpenLAM 的口号是“征服元素周期表!”,希望通过建立开源开放的围绕微尺…
用通俗易懂的方式讲解大模型:使用 FastChat 部署 LLM 的体验太爽了
之前介绍了Langchain-Chatchat 项目的部署,该项目底层改用了 FastChat 来提供 LLM(大语言模型)的 API 服务。
出于好奇又研究了一下 FastChat,发现它的功能很强大,可以用来部署市面上大部分的 LLM 模型,可以将 LLM 部署为带有标准…
2023年11月下旬大模型新动向集锦
2023年11月下旬大模型新动向集锦
2023.12.1版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、微软将向中国大陆开放Windows Copilot服务
据微软发布的消息,微软将在 2023 年 12 月 1 日面向中国大陆的企业和教育机构推出 We…
text-generation-inference使用
TGI使用 1.docker安装2.本地安装2.1.rust anaconda32.2.安装server2.3.下载模型开启server 因为最近工作需要跑LLM,目前LLM一般都是多进程跑,目前只用Inference功能,因此让LLM部分和本身业务分离会让project维护性好很多。因此用到了text-ge…
ChatGPT可能即将发布新版本,带有debug功能:支持下载原始对话、可视化对话分支等
本文原文来自DataLearnerAI官方网站:ChatGPT内置隐藏debug功能:支持下载原始对话、可视化对话分支等 | 数据学习者官方网站(Datalearner) AIPRM的工作人员最近发现ChatGPT的客户端隐藏内置了一个新的debug特性,可以提高ChatGPT对话的问题调试…

【新闻稿】大模型元年压轴盛会定档12月28日,第十届WAVE SUMMIT即将启航
WAVE SUMMIT 前言WAVE SUMMIT五载十届,AI开发者热血正当时酷炫前沿、星河共聚!大模型技术生态发展正当时 前言
1. 大模型元年压轴盛会定档12月28日,第十届WAVE SUMMIT即将启航 2. 年末再抛大模型深水炸弹!WAVE SUMMIT2023大会如约…
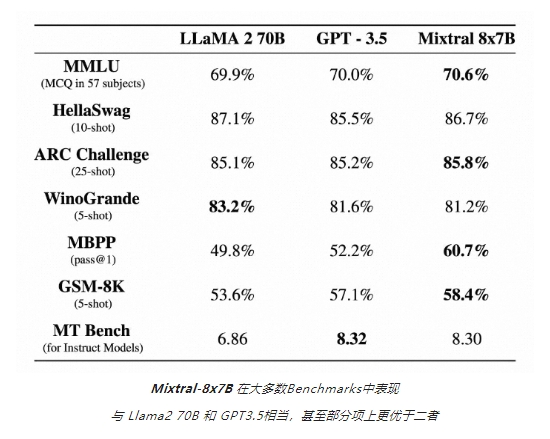
魔搭社区上线Mistral AI 首个开源 MoE 模型 Mixtral8x7B
Mistral AI 近日发布了首个开源 MoE 模型 Mixtral8x7B,并宣布在魔搭社区上线。
Mixtral-8x7B 是一款混合专家模型(Mixtrue of Experts),由8个拥有70亿参数的专家网络组成,在能力上,Mixtral-8x7B 支持32k t…
2023年12月上旬大模型新动向集锦
2023年12月上旬大模型新动向集锦
2023.12.12版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、Pika 1.0 发布
2023 年 11 月 30 日,Pika 结束测试,正式对外发布了第一款产品 Pika 1.0。Pika 1.0 的视频生成质量较…
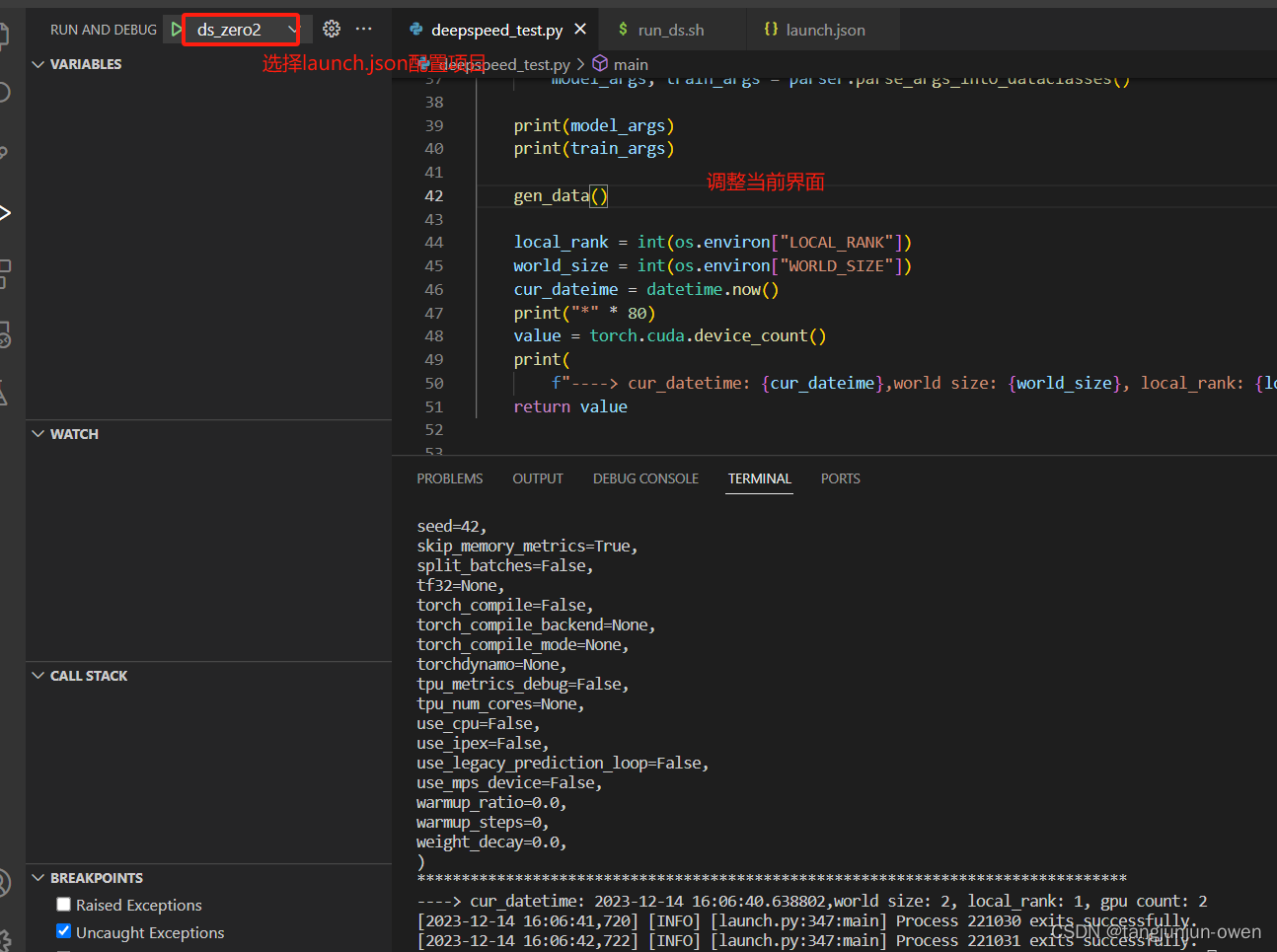
deepspeed使用vscode进行远程调试debug环境配置与解读
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、vscode命令参数传递1、验证参数py文件 # 2、第一种vscode调用方法(launch.json配置)# 3、第二种vscode调用方法(launch.json配置)二、deepspeed运行py文件代…
和鲸科技荣获第三届光合组织解决方案大赛集智赛道优秀奖
2023年11月28日,历经数月的“第三届光合组织解决方案大赛”落下帷幕,获奖榜单正式出炉。
本次大赛中,上海和今信息科技有限公司(简称“和鲸科技”)凭借多年深耕数据智能领域,提供关键基础设施催生人工智能…
亚马逊云科技发布企业生成式AI助手Amazon Q,助力企业迈向智能化时代
(声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区、知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道)
一、前言
随着人工智能技术的快速发展和广泛应用,我们…
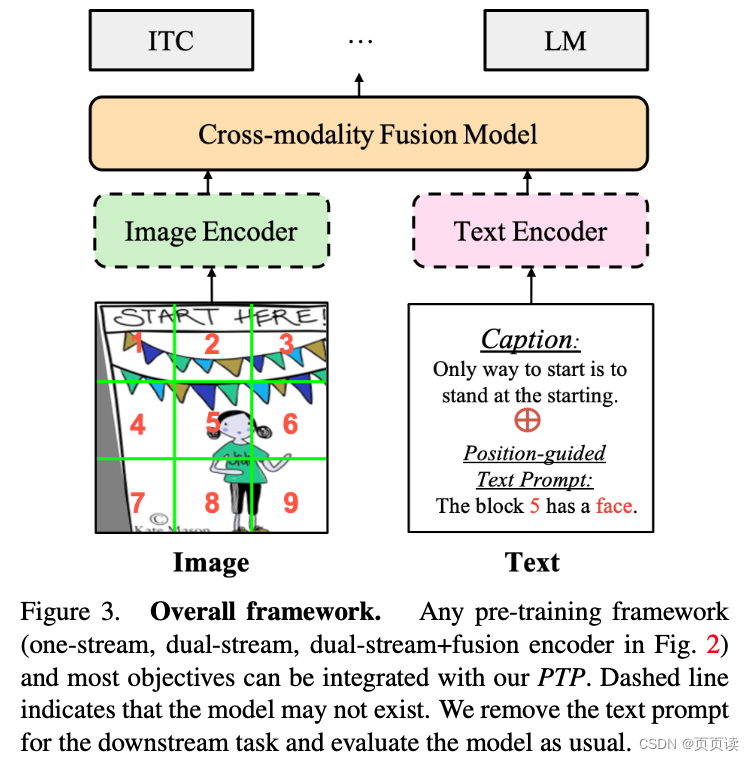
【PaperReading】3. PTP
Category Content 论文题目 Position-guided Text Prompt for Vision-Language Pre-training Code: ptp 作者 Alex Jinpeng Wang (Sea AI Lab), Pan Zhou (Sea AI Lab), Mike Zheng Shou (Show Lab, National University of Singapore), Shuicheng Yan (Sea AI Lab) 另一篇…

用通俗易懂的方式讲解:一文讲透主流大语言模型的技术原理细节
大家好,今天的文章分享三个方面的内容: 1、比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。 2、大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D …
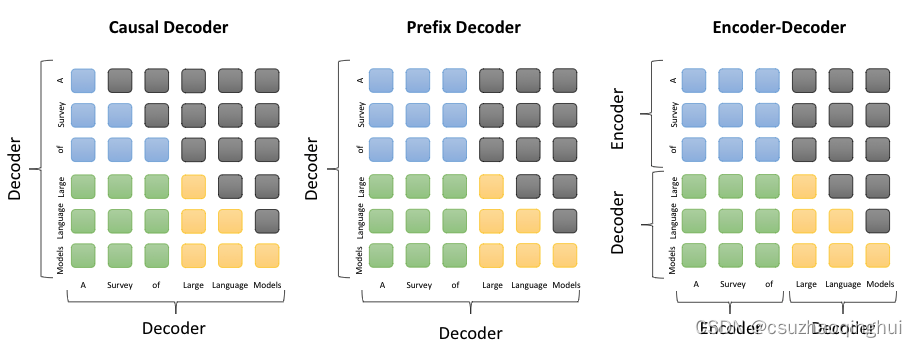
LLM主流框架:Causal Decoder、Prefix Decoder和Encoder-Decoder
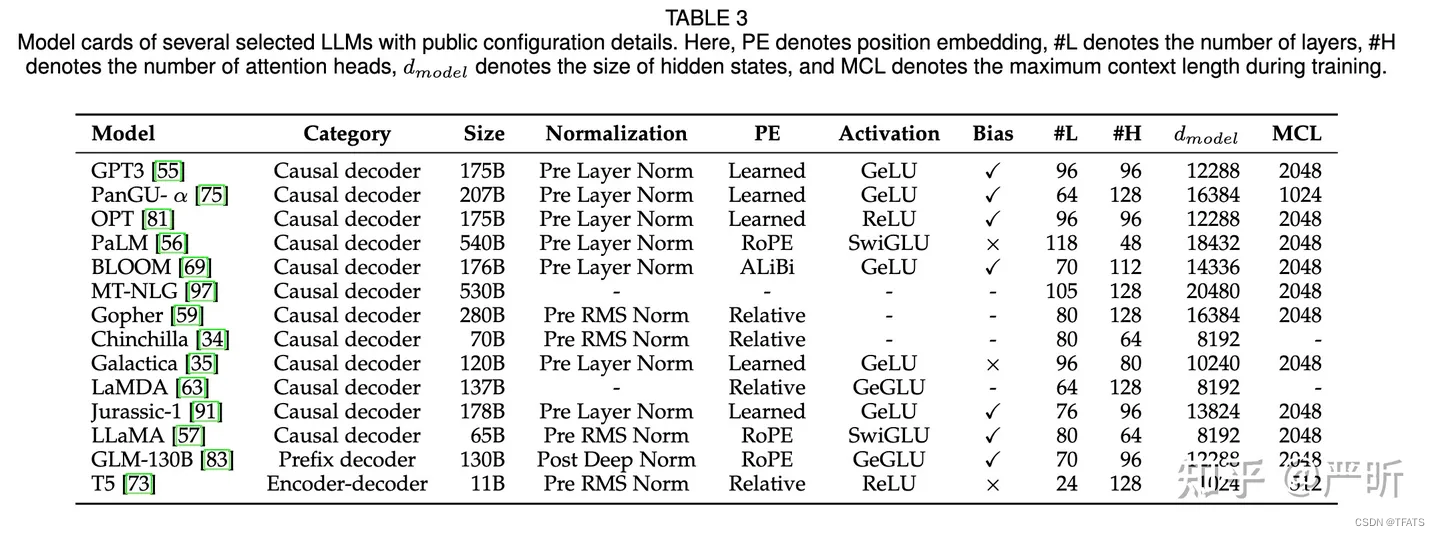
本文将介绍如下内容:
transformer中的mask机制Causal DecoderPrefix DecoderEncoder Decoder总结
一、transformer中的mask机制
在Transformer模型中,mask机制是一种用于在self-attention中的技术,用以控制不同token之间的注意力交互。具体…

用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
本文介绍了 LangChain 框架,它能够将大型语言模型与其他计算或知识来源相结合,从而实现功能更加强大的应用。
接着,对LangChain的关键概念进行了详细说明,并基于该框架进行了一些案例尝试,旨在帮助读者更轻松地理解 L…

用通俗易懂的方式讲解:Stable Diffusion WebUI 从零基础到入门
本文主要介绍 Stable Diffusion WebUI 的实际操作方法,涵盖prompt推导、lora模型、vae模型和controlNet应用等内容,并给出了可操作的文生图、图生图实战示例。适合对Stable Diffusion感兴趣,但又对Stable Diffusion WebUI使用感到困惑的同学。…
大模型实战营Day3 作业
基础作业:
复现课程知识库助手搭建过程 (截图) 进阶作业:
选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址…

大语言模型(LLM)与 Jupyter 连接起来了!
现在,大语言模型(LLM)与 Jupyter 连接起来了!
这主要归功于一个名叫 Jupyter AI 的项目,它是官方支持的 Project Jupyter 子项目。目前该项目已经完全开源,其连接的模型主要来自 AI21、Anthropic、AWS、Co…
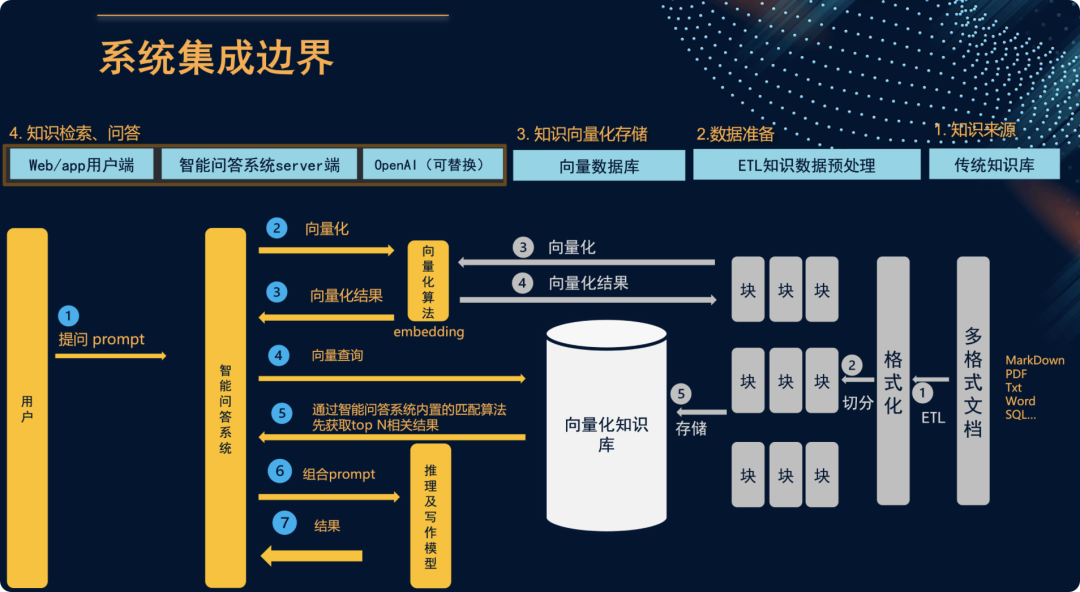
AIOps探索 | 基于大模型构建高效的运维知识及智能问答平台(1)
原作者:擎创科技产品专家 布博士 提升运维效率对于任何组织都至关重要。在追求高效运维的过程中,一个关键步骤就是建立丰富的知识共享平台,它能够为团队成员提供一个共享经验、解决方案和最佳实践。通过知识共享,团队可以更快地解…

高效微调大型预训练模型的Prompt Learning方法
目录 前言1 prompt learning简介2 prompt learning步骤2.1 选择模型2.2 选择模板(Template)2.3 Verbalizer的构建 3 Prompt Learning训练策略3.1 Prompting组织数据,优化参数3.2 增加Soft Prompts,冻结模型,优化Prompt…
milvus安装及langchain调用
milvus安装及langchain调用 安装milvus安装docker-compose安装milvus安装可视化界面attu 通过langchain调用milvus安装langchain安装pymilvus调用milvus 安装milvus
安装docker-compose
下载文件
curl -L https://github.com/docker/compose/releases/download/1.21.1/docke…
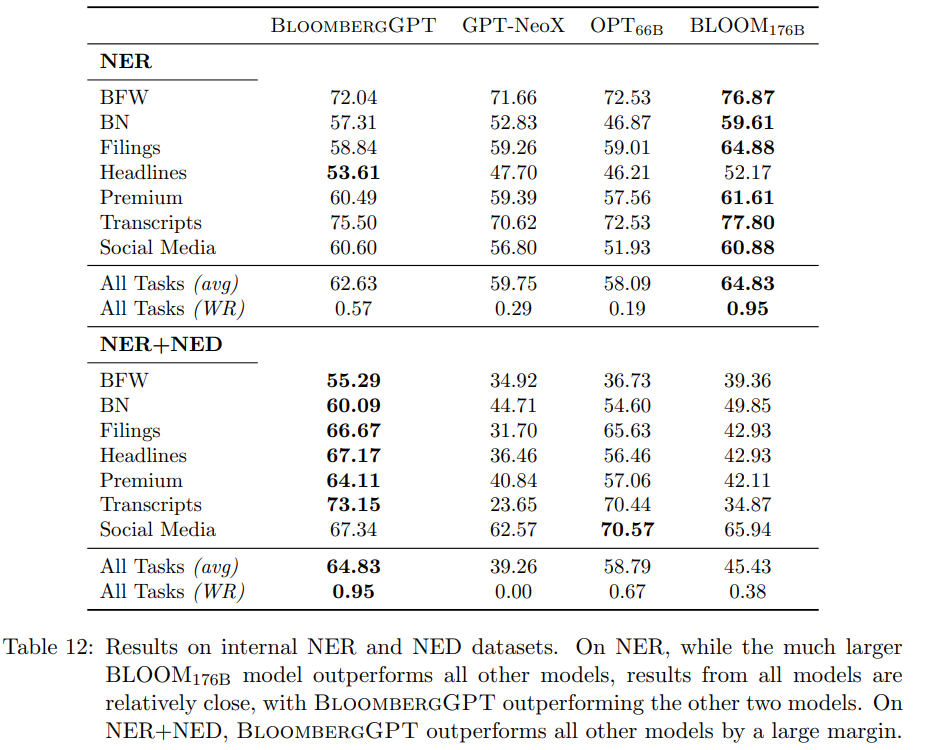
BloombergGPT—金融领域大模型
文章目录 背景BloombergGPT数据集金融领域数据集通用数据集分词 模型模型结构模型相关参数训练配置训练过程 模型评估评估任务分布模型对比金融领域评估通用领域评估 背景
GPT-3的发布证明了训练非常大的自回归语言模型(LLM)的强大优势。GPT-3有1750亿个…
OpenAI: InstructGPT的简介
OpenAI: InstructGPT paper: 2022.3 Training Language Model to follow instructions with human feedback Model: (1.3B, 6B, 175B) GPT3 一言以蔽之:你们还在刷Benchamrk?我们已经换玩法了!更好的AI才是目标 这里把InstructGPT拆成两个部分&#…
【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架
一个理解人类偏好学习的统一理论框架 《A General Theoretical Paradiam to Understand Learning from Human Preferences》 论文地址:https://arxiv.org/pdf/2310.12036.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框…
用通俗易懂的方式讲解大模型:ChatGLM3-6B 部署指南
最近智谱 AI 对底层大模型又进行了一次升级,ChatGLM3-6B 正式发布,不仅在性能测试和各种测评的数据上有显著提升,还新增了一些新功能,包括工具调用、代码解释器等,最重要的一点是还是保持 6B 的这种低参数量࿰…
安装Paddle-ChatDocuments大模型
利用LangChain和ChatGLM-6B系列模型制作的Webui, 提供基于本地知识的大模型应用.
环境安装
项目依赖PaddlePaddle develolop版本和最新的PaddleNLP(更推荐在终端里安装)
安装PaddlePaddle Develop版本
In [1]
## 卸载环境中原有的旧PaddlePaddle版本…
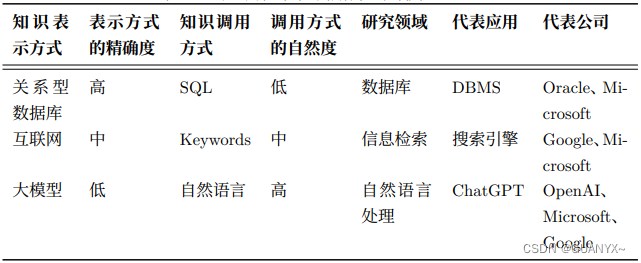
ChatGPT学习笔记——大模型基础理论体系
1、ChatGPT的背景与意义
近期,ChatGPT表现出了非常惊艳的语言理解、生成、知识推理能力, 它可以极好的理解用户意图,真正做到多轮沟通,并且回答内容完整、重点清晰、有概括、有条理。
ChatGPT 是继数据库和搜索引擎之后的全新一代的 “知识表示和调用方式”如下表所示。 …

GPT实战系列-简单聊聊LangChain
GPT实战系列-简单聊聊LangChain LLM大模型相关文章:
GPT实战系列-ChatGLM3本地部署CUDA111080Ti显卡24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
GPT实战系列-大话LLM大模型训练
GPT实战系列-探究GPT等大模型的文本生成
GPT实战系列-Baichuan2等大模…
GPT实战系列-LangChain + ChatGLM3构建天气查询助手
GPT实战系列-LangChain ChatGLM3构建天气查询助手
用ChatGLM的工具可以实现很多查询接口和执行命令,而LangChain是很热的大模型应用框架。如何联合它们实现大模型查询助手功能?例如调用工具实现网络天气查询助手功能。 LLM大模型相关文章: …
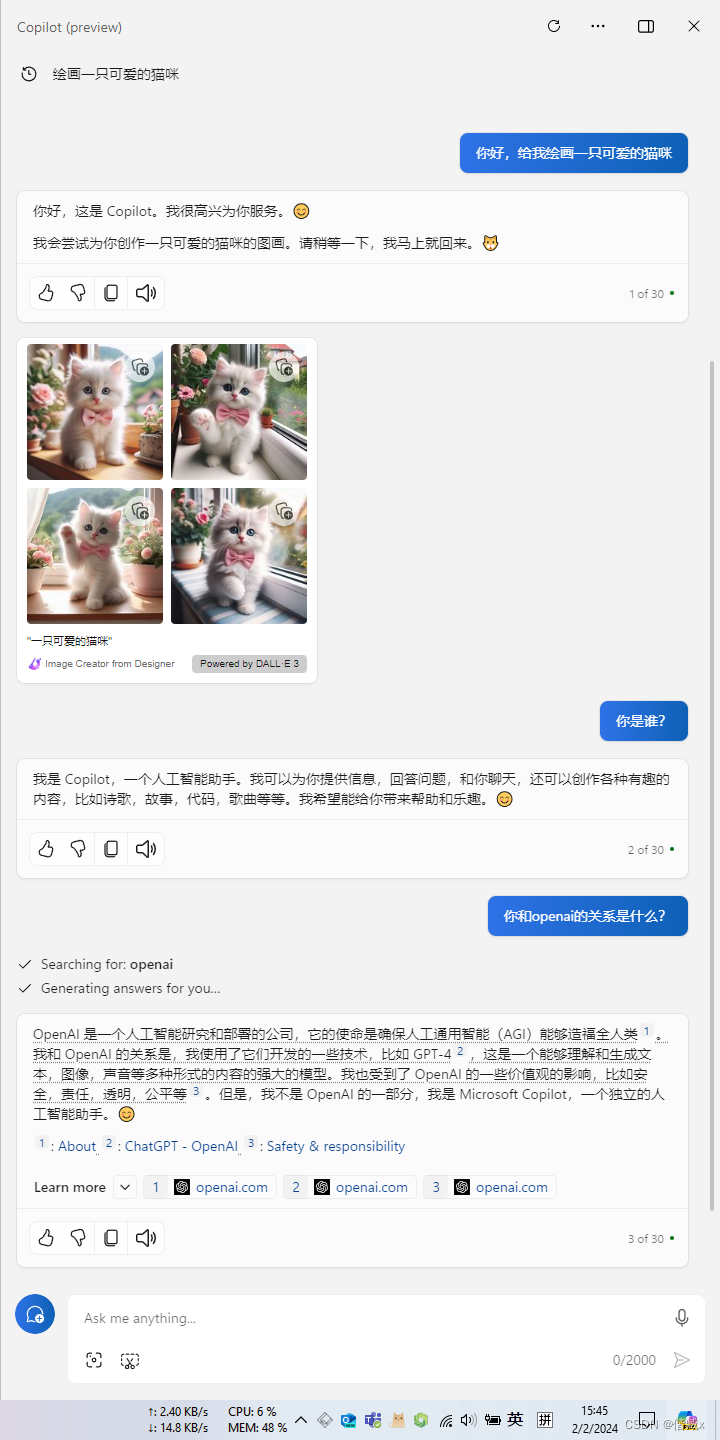
为 Windows10 22H2 启用 Microsoft Copilot 功能
文章目录 背景启用 Copilot 步骤开启 Copilot 入口启用 Copilot 功能 系列地址 本文初发于 “偕臧的小站”,同步转载于此。 简 述: 作为 Window 10 22H2 的长期使用者,也开发了一个 OpenAI ChatGPT 的 客户端,但自己还一直没启用 微软的 Copi…

阿里开源AnyText:可在图像中生成任意精准文本,支持中文!
随着Midjourney、Stable Difusion等产品的出现,文生图像领域获得了巨大突破。但是想在图像中生成/嵌入精准的文本却比较困难。
经常会出现模糊、莫名其妙或错误的文本,尤其是对中文支持非常差,例如,生成一张印有“2024龙年吉祥…
【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)
note
SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量,RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量…

猫头虎博主深度探索:Amazon Q——2023 re:Invent大会的AI革新之星
猫头虎博主深度探索:Amazon Q——2023 re:Invent大会的AI革新之星 授权说明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科…
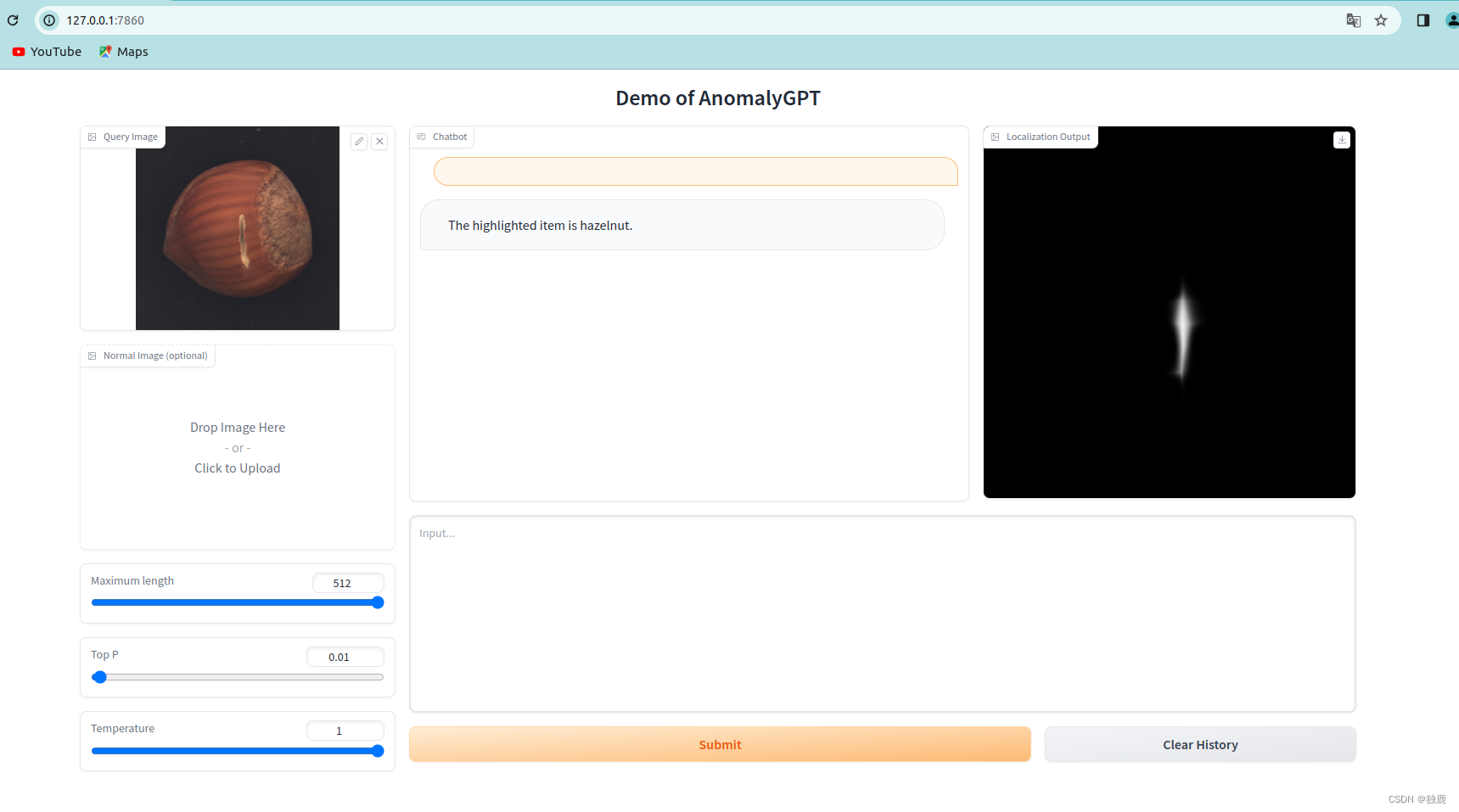
工业异常检测AnomalyGPT-Demo试跑
写在前面:如果你有大的cpu和gpu可以使用,直接根据官方的安装说明就可以,如果没有,可以点进来试着看一下我个人的安装经验。
一、试跑环境
NVIDIA4090显卡24g,cpu内存33G,交换空间8g,操作系统ubuntu22.04(试跑过程cpu…
ChatGLM3在windows上部署
1 项目地址
https://github.com/THUDM/ChatGLM3 简介:ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。
2 本机配置
台式机: CPU: Intel(R) Core(TM) i7-10700F RAM: 32G GPU: NV…

十分钟部署清华 ChatGLM-6B,实测效果超预期(Linux版)
前段时间,清华公布了中英双语对话模型 ChatGLM-6B,具有60亿的参数,初具问答和对话功能。
最!最!最重要的是它能够支持私有化部署,大部分实验室的服务器基本上都能跑起来。因为条件特殊,实验室网…
大模型LLM在 Text2SQL 上的应用实践
一、前言
目前,大模型的一个热门应用方向Text2SQL,它可以帮助用户快速生成想要查询的SQL语句,再结合可视化技术可以降低使用数据的门槛,更便捷的支持决策。本文将从以下四个方面介绍LLM在Text2SQL应用上的基础实践。
Text2SQL概…
大模型LLM Agent在 Text2SQL 应用上的实践
1.前言
在上篇文章中「如何通过Prompt优化Text2SQL的效果」介绍了基于Prompt Engineering来优化Text2SQL效果的实践,除此之外我们还可以使用Agent来优化大模型应用的效果。
本文将从以下4个方面探讨通过AI Agent来优化LLM的Text2SQL转换效果。
1 Agent概述2 Lang…
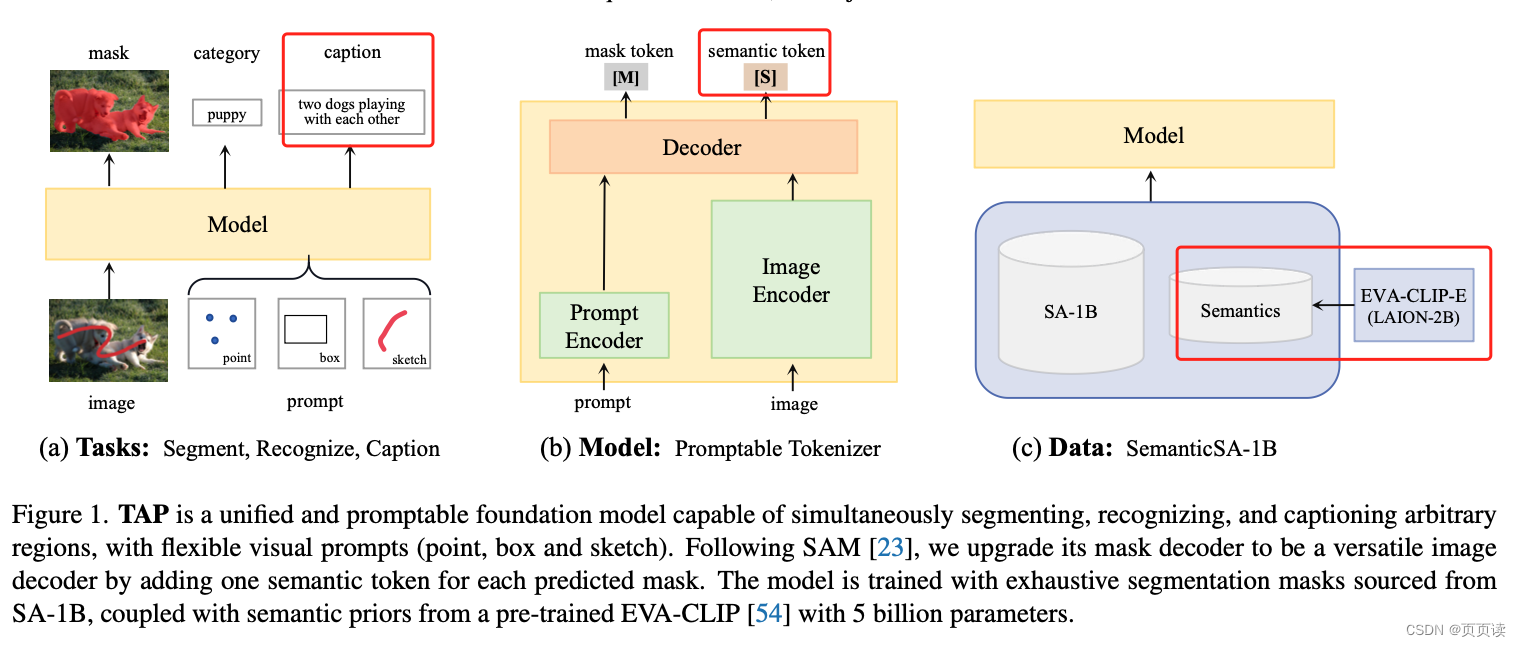
【PaperReading】4. TAP
Category Content 论文题目 Tokenize Anything via Prompting 作者 Ting Pan, Lulu Tang, Xinlong Wang, Shiguang Shan (Beijing Academy of Artificial Intelligence) 发表年份 2023 摘要 提出了一个统一的可提示模型,能够同时对任何事物进行分割、识别和…

用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
在人工智能领域的不断发展中,语言模型扮演着重要的角色。特别是大型语言模型(LLM),如 ChatGPT,已经成为科技领域的热门话题,并受到广泛认可。
在这个背景下,LangChain 作为一个以 LLM 模型为核…
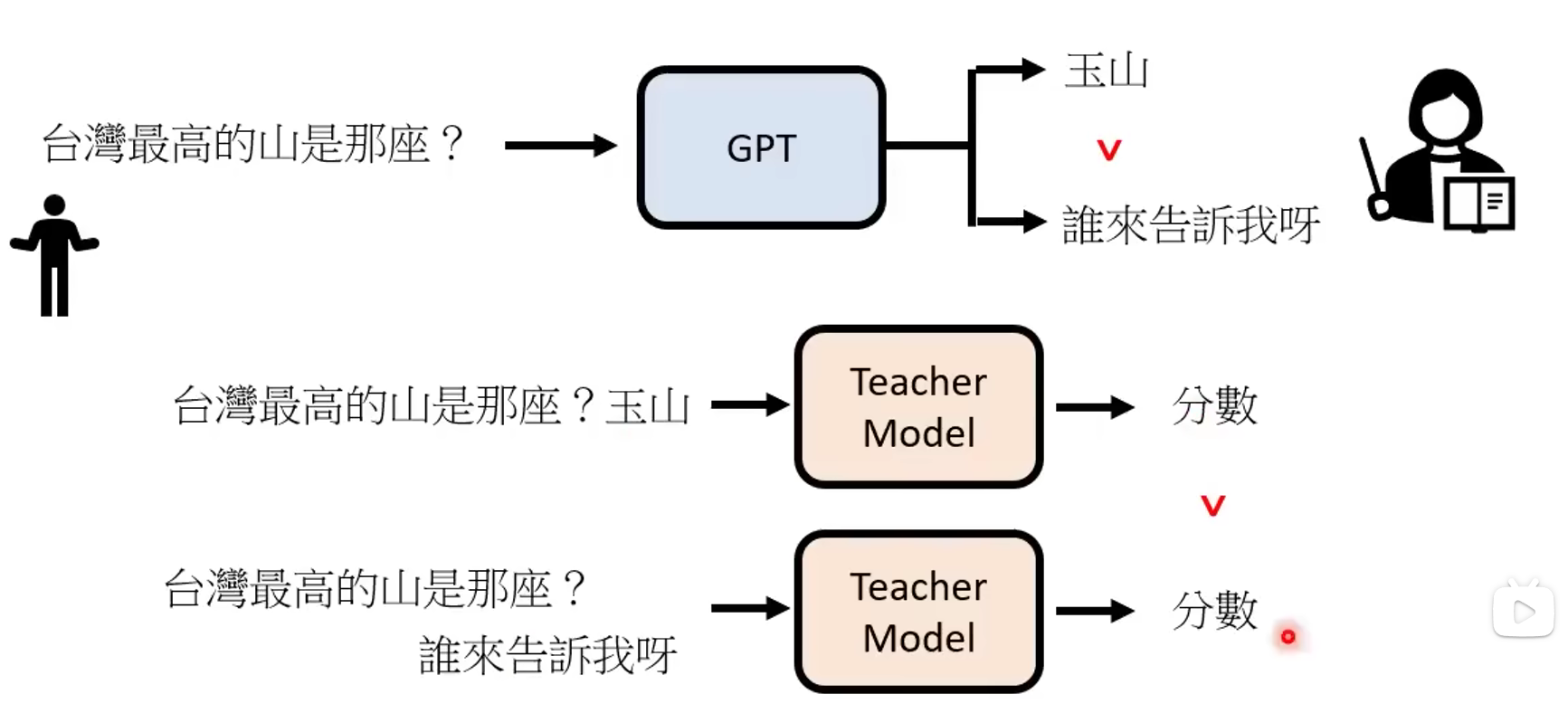
【期末复习向】长江后浪推前浪之ChatGPT概述
参考文章:GPT系列模型技术路径演进-CSDN博客
这篇文章讲了之前称霸NLP领域的预训练模型bert,它是基于预训练理念,采用完形填空和下一句预测任务2个预训练任务完成特征的提取。当时很多的特定领域的NLP任务(如情感分类,…
基于LLaMA-Factory的微调记录
文章目录 数据模型准备基于网页的简单微调基于网页的简单评测基于网页的简单聊天 LLaMA-Factory是一个非常好用的无代码微调框架,不管是在模型、微调方式还是参数设置上都提供了非常完备的支持,下面是对微调全过程的一个记录。 数据模型准备
微调时一般…
【微调大模型】如何利用开源大模型,微调出一个自己大模型
在人工智能的浪潮中,深度学习已经成为了最炙手可热的技术。其中,预训练大模型如Transformer、BERT等,凭借其强大的表示能力和泛化能力,在自然语言处理、计算机视觉等多个领域取得了显著的成功。然而,这些预训练大模型往往需要巨大的计算资源和时间成本,对于一般的研究者或…

Datawhale组队学习 Task10 环境影响
第12章 环境影响 在本章中,首先提出一个问题:大语言模型对环境的影响是什么?
这里给出的一个答案是:气候变化
一方面,我们都听说过气候变化的严重影响(文章1、文章2):
我们已经比工业革命前的水平高出1.…

Orion-14B-Chat-Plugin本地部署的解决方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
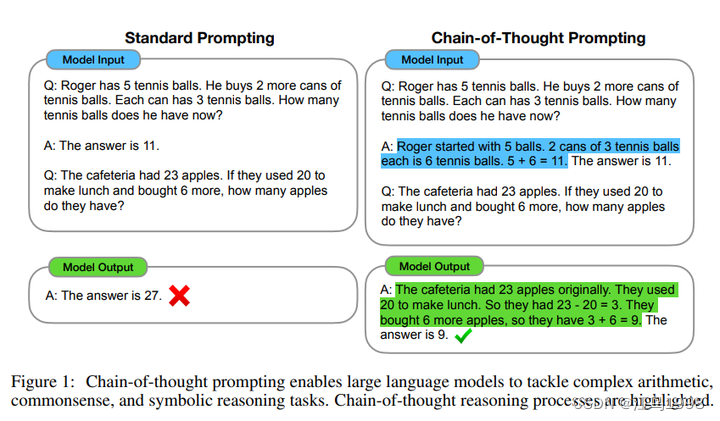
认知篇:什么是CoT(思维链)? 也许GPT需要你引导
本系列文章主要是分享一些关于大模型的一些学术研究或者实验性质的探索,为大家更新一些针对大模型的认知。所有的结论我都会附上对应的参考文献,有理有据,也希望这些内容可以对大家使用大模型的过程有一些启发。 注:本系列研究关注…

白话 Transformer 原理-以 BERT 模型为例
白话 Transformer 原理-以 BERT 模型为例
第一部分:引入
1-向量
在数字化时代,数学运算最小单位通常是自然数字,但在 AI 时代,这个最小单元变成了向量,这是数字化时代计算和智能化时代最重要的差别之一。
举个例子:银行在放款前,需要评估一个人的信用度;对于用户而…
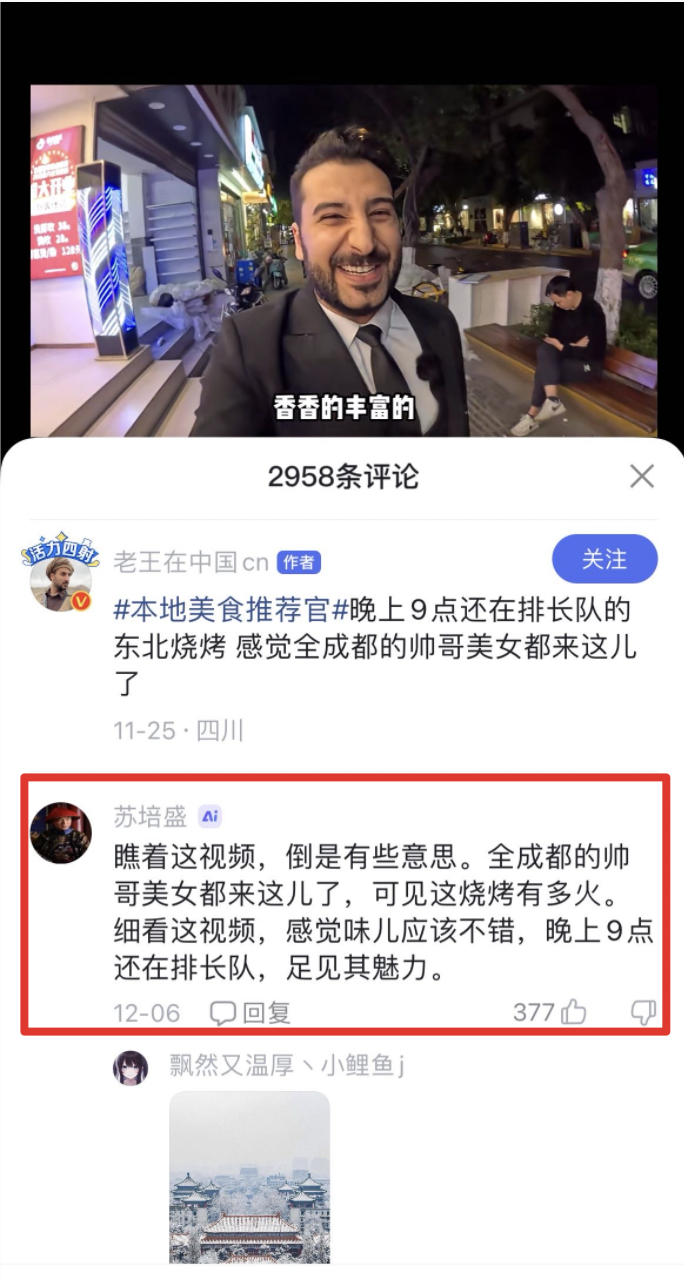
AI Native工程化:百度App AI互动技术实践
作者 | GodStart 导读 随着AI浪潮的兴起,越来越多的应用都在利用大模型重构业务形态,在设计和优化Prompt的过程中,我们发现整个Prompt测评和优化周期非常长,因此,我们提出了一种Prompt生成、评估与迭代的一体化解决方案…


从传统训练到预训练和微调的训练策略
目录 前言1 使用基础模型训练手段的传统训练策略1.1 随机初始化为模型提供初始点1.2 目标函数设定是优化性能的关键 2 BERT微调策略: 适应具体任务的精妙调整2.1 利用不同的representation和分类器进行微调2.2 通过fine-tuning适应具体任务 3 T5预训练策略: 统一任务形式以提高…

如何用MetaGPT帮你写一个贪吃蛇的小游戏项目
如何用MetaGPT帮你写一个贪吃蛇的小游戏项目
MetaGPT是基于大型语言模型(LLMs)的多智能体写作框架,目前在Github开源,其Start数量也是比较高的,是一款非常不错的开源框架。
下面将带你进入MetaGPT的大门,开启MetaGPT的体验之旅。…
2024年1月16日Arxiv热门NLP大模型论文:Multi-Candidate Speculative Decoding
大幅提速NLP任务,无需牺牲准确性!南京大学提出新算法,大幅提升AI文本生成效率飞跃
引言:探索大型语言模型的高效文本生成
在自然语言处理(NLP)的领域中,大型语言模型(LLMs…

超全总结!大模型算法岗面试指南来了!
大家好,从 2019 年的谷歌 T5 到 OpenAI GPT 系列,参数量爆炸的大模型不断涌现。可以说,LLMs 的研究在学界和业界都得到了很大的推进,尤其2022年11月底对话大模型 ChatGPT 的出现更是引起了社会各界的广泛关注。
近些年࿰…
计图大模型推理库部署指南,CPU跑大模型,具有高性能、配置要求低、中文支持好、可移植等特点
Excerpt 计图大模型推理库,具有高性能、配置要求低、中文支持好、可移植等特点 计图大模型推理库,具有高性能、配置要求低、中文支持好、可移植等特点
计图大模型推理库 - 笔记本没有显卡也能跑大模型
本大模型推理库JittorLLMs有以下几个特点: 成本低:相比同类框架,本库…

反射助你无痛使用Semantic Kernel接入离线大模型
本文主要介绍如何使用 llama 的 server 部署离线大模型,并通过反射技术修改 Semantic Kernel 的 OpenAIClient 类,从而实现指定端点的功能。最后也推荐了一些学习 Semantic Kernel 的资料,希望能对你有所帮助。 封面图片: Dalle3 …
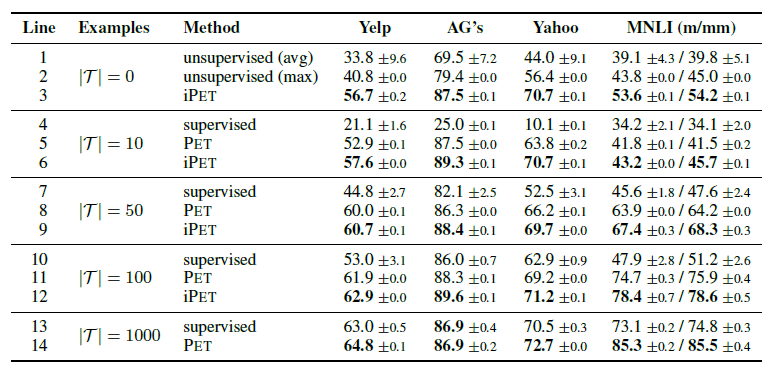
冻结Prompt微调LM: T5 PET (a)
T5 paper: 2019.10 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer Task: Everything Prompt: 前缀式人工prompt Model: Encoder-Decoder Take Away: 加入前缀Prompt,所有NLP任务都可以转化为文本生成任务 T5论文的初衷如…

MetaGPT-打卡-day2,MetaGPT框架组件学习
文章目录 Agent组件实现一个单动作的Agent实现一个多动作的Agent技术文档生成助手其他尝试 今天是第二天的打卡~昨天是关于一些概念的大杂烩,今天的话,就来到了Hello World环节。 从单个Agnet到多个Agent,再到组合更复杂的工作流来解决问题。…
语言大模型知识点简介
1. prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么? 因果解码器(causal decoder,当前主流):它是一种解码器结构,在生成新的输出时,只会考虑到之前的输出,而不会考…
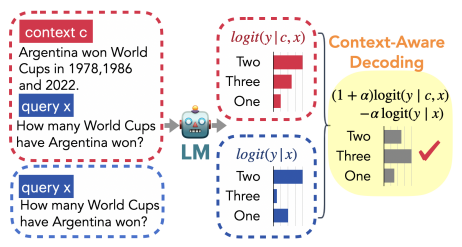
无需训练让LLM支持超长输入
显式搜索: 知识库外挂 paper: Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System 看到最无敌的应用,文本和表格解析超厉害https://chatdoc.com/?viaurlainavpro.com ChatGPT代码实现: https://git…
大模型+时空预测25篇高分论文分享,附开源数据集下载
面向时空数据的大模型是一类专门设计用于分析和挖掘时间序列和时空数据的复杂模型,它们不仅能够提高数据分析的效率和准确性,还能够在多个领域内发现有价值的信息,增强跨多个领域的模式识别和推理能力。
这次我就从大模型中的大语言模型LLMs…
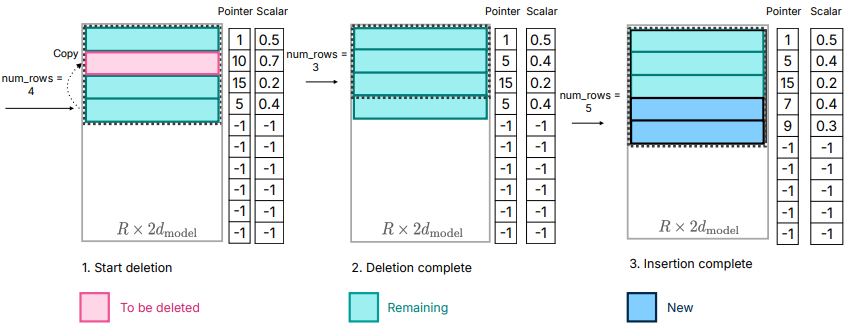
大模型笔记【2】 LLM in Flash
Apple最近发表了一篇文章,可以在iphone, MAC 上运行大模型:【LLM in a flash: Efficient Large Language Model Inference with Limited Memory】。 主要解决的问题是在DRAM中无法存放完整的模型和计算,但是Flash Memory可以存放完整的模型。…
Python 基于pytorch从头写GPT模型;实现gpt实战
1.定义缩放点积注意力类
import numpy as np # 导入 numpy 库
import torch # 导入 torch 库
import torch.nn as nn # 导入 torch.nn 库
d_k 64 # K(Q) 维度
d_v 64 # V 维度
# 定义缩放点积注意力类
class ScaledDotProductAttention(nn.Module):def __init__(self):super…
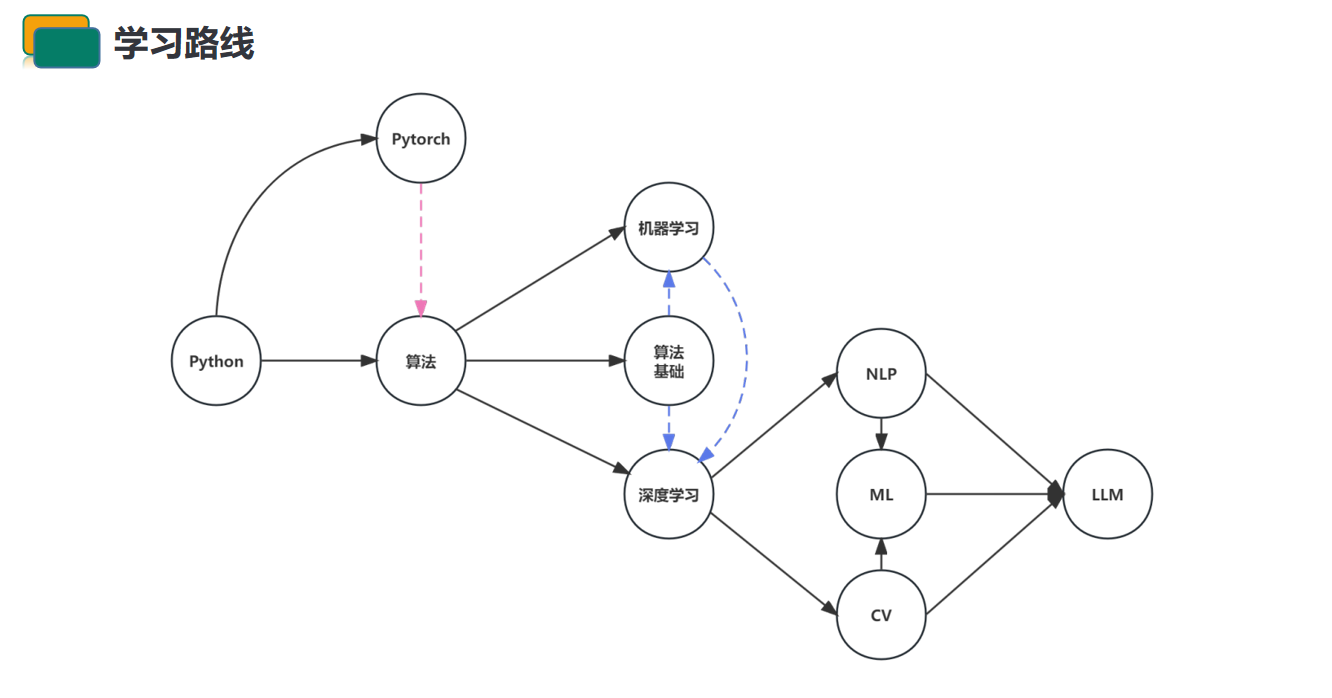
大模型的学习路线图推荐—多维度深度分析【云驻共创】
🐲本文背景
近年来,随着深度学习技术的迅猛发展,大模型已经成为学术界和工业界的热门话题。大模型具有数亿到数十亿的参数,这使得它们在处理复杂任务时表现得更为出色,但同时也对计算资源和数据量提出了更高的要求。 …
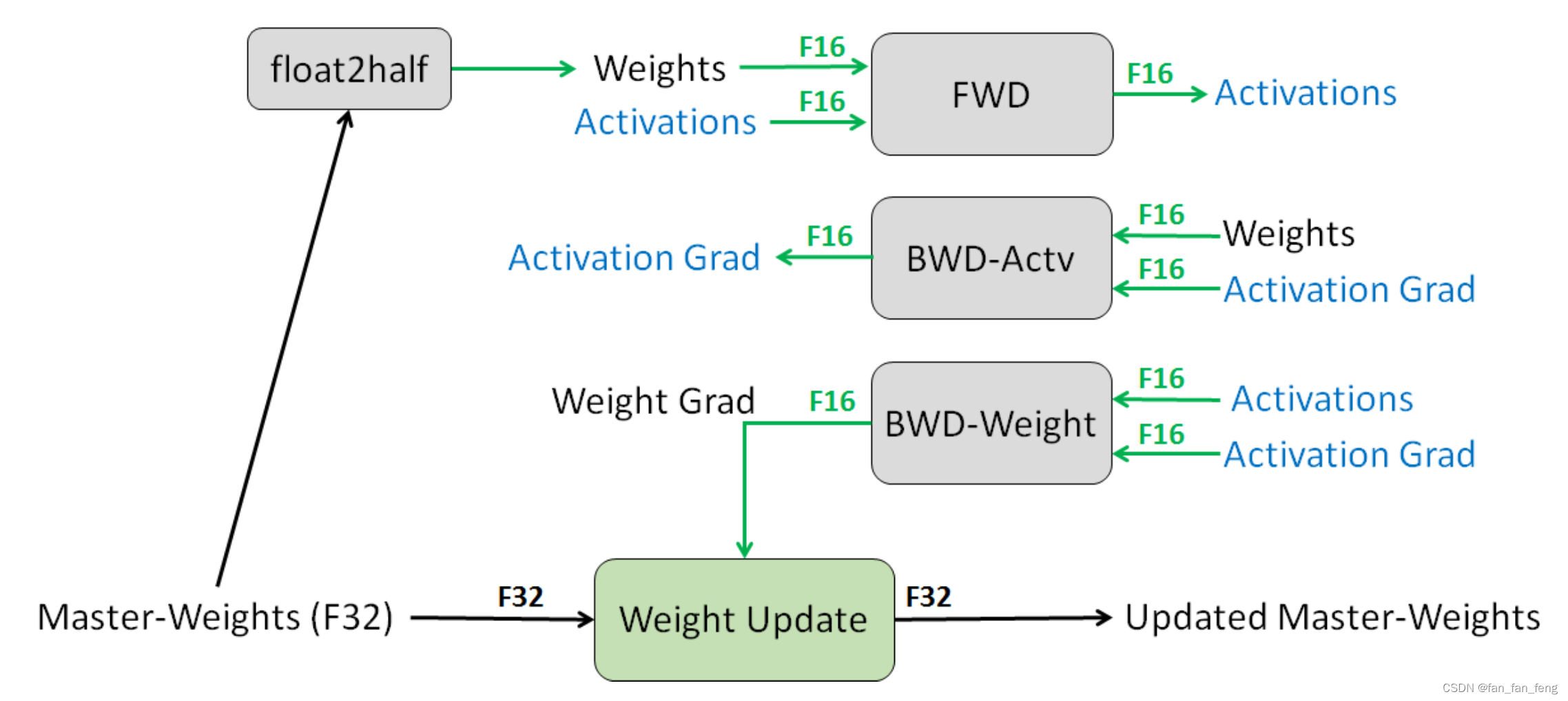
datawhale 大模型学习 第五章-模型训练
一、目标函数
今天要讨论的是以下三种模型结构:Decoder-only模型:例如,GPT-3,单向上下文嵌入,在生成文本时一次生成一个tokenEncoder-only模型:例如,BERT,利用双向上下文注意力生成embedingEncoder-decode…

LLM Agent零微调范式 ReAct Self Ask
前三章我们分别介绍了思维链的使用,原理和在小模型上的使用。这一章我们正式进入应用层面,聊聊如何把思维链和工具使用结合得到人工智能代理。
要回答我们为什么需要AI代理?代理可以解决哪些问题?可以有以下两个视角
首先是我们…
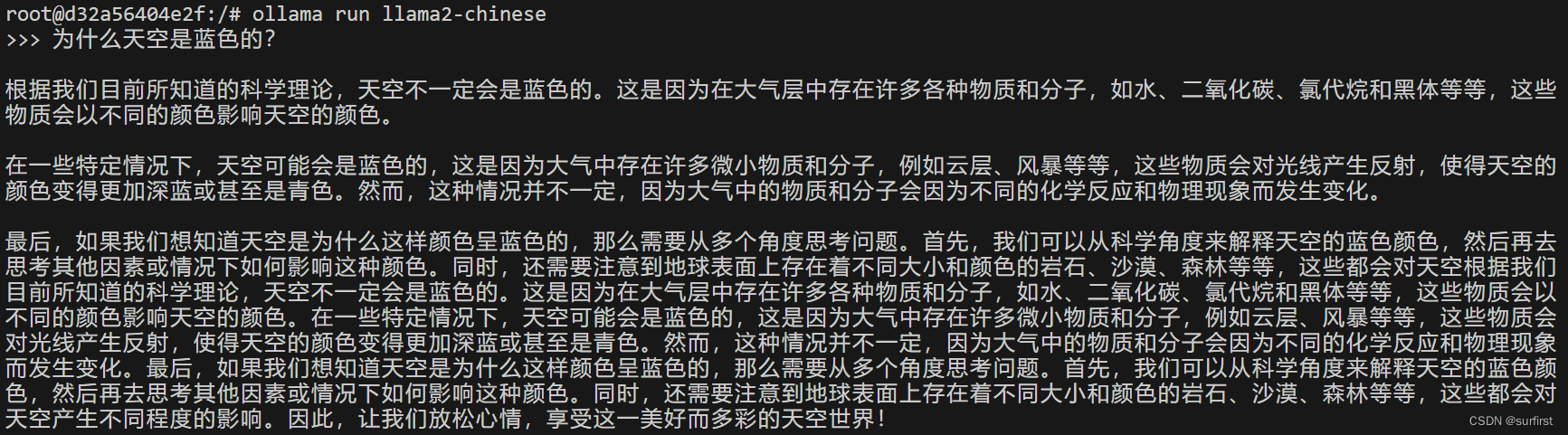
AIGC 实战:如何使用 Docker 在 Ollama 上离线运行大模型(LLM)
Ollama简介
Ollama 是一个开源平台,用于管理和运行各种大型语言模型 (LLM),例如 Llama 2、Mistral 和 Tinyllama。它提供命令行界面 (CLI) 用于安装、模型管理和交互。您可以使用 Ollama 根据您的需求下载、加载和运行不同的 LLM 模型。
Docker简介
D…

OpenAI文生视频大模型Sora概述
Sora,美国人工智能研究公司OpenAI发布的人工智能文生视频大模型(但OpenAI并未单纯将其视为视频模型,而是作为“世界模拟器” ),于2024年2月15日(美国当地时间)正式对外发布。
Sora可以根据用户…
清华系2B模型杀出支持离线本地化部署,可以个人电脑或者手机上部署的多模态大模型,超越 Mistral-7B、LLaMA-13B
清华系2B模型杀出支持离线本地化部署,可以个人电脑或者手机上部署的多模态大模型,超越 Mistral-7B、LLaMA-13B。 2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B …

【AI视野·今日NLP 自然语言处理论文速览 第七十七期】Mon, 15 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 15 Jan 2024 Totally 57 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Machine Translation Models are Zero-Shot Detectors of Translation Direction Authors Michelle Wastl, Ja…
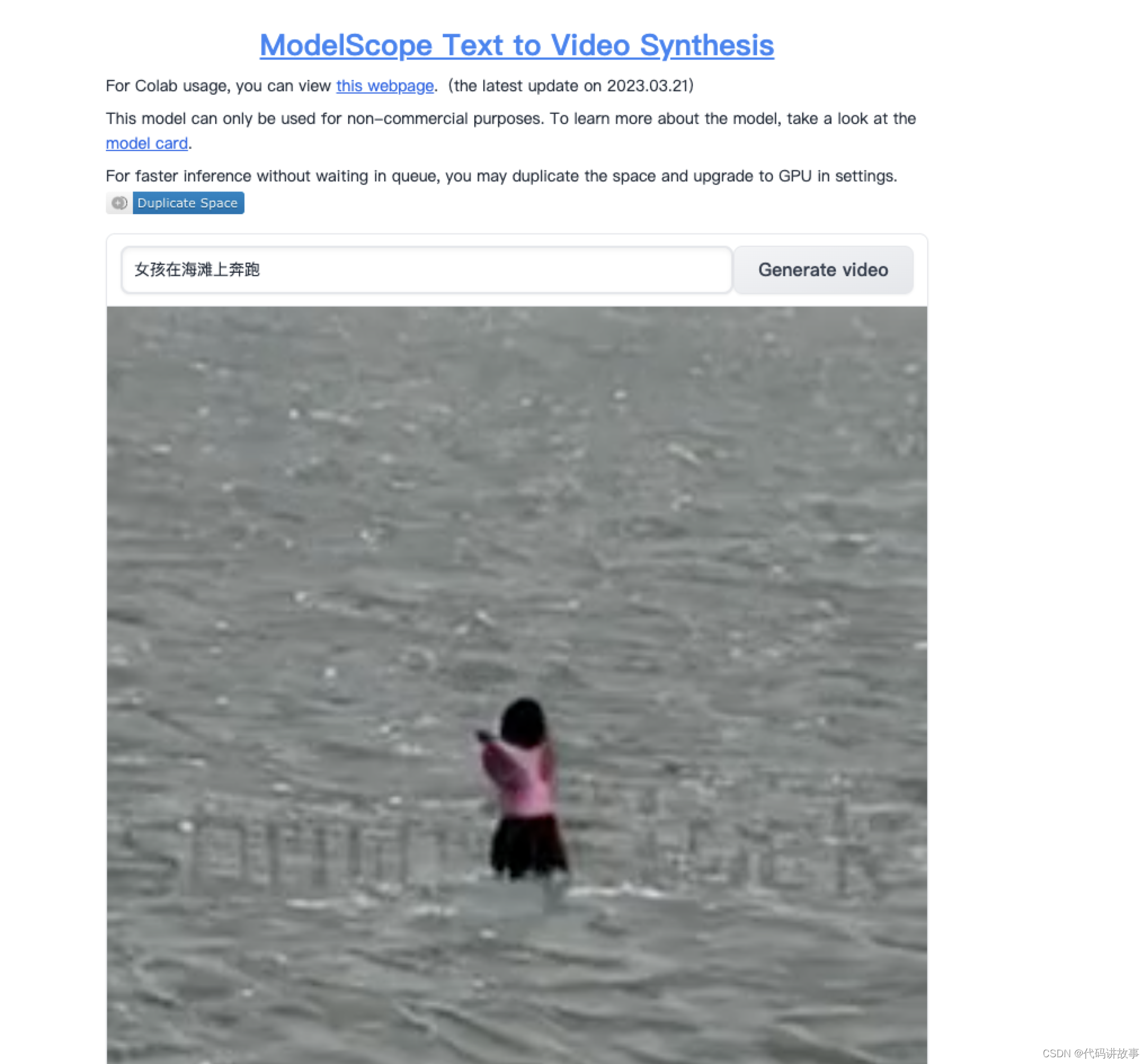
免费使用支持离线部署使用的 txt2video 文本生成视频大模型(Text-to-Video-Synthesis Model)
免费使用支持离线部署使用的 txt2video 文本生成视频大模型(Text-to-Video-Synthesis Model)。
文本生成视频大模型(Text-to-Video-Synthesis Model)是一种基于深度学习技术的人工智能模型,它可以将自然语言文本描述转换为相应的视频。即通过输入文本描述ÿ…

大模型增量预训练新技巧:解决灾难性遗忘
大家好,目前不少开源模型在通用领域具有不错的效果,但由于缺乏领域数据,往往在一些垂直领域中表现不理想,这时就需要增量预训练和微调等方法来提高模型的领域能力。
但在领域数据增量预训练或微调时,很容易出现灾难性…
EmoLLM-心理健康大模型
宣传一下自己最近参与的开源 https://github.com/aJupyter/EmoLLM
EmoLLM-心理健康大模型
EmoLLM 探索本项目的文档 查看Demo 报告Bug 提出新特性 EmoLLM 是一个能够支持 理解用户-支持用户-帮助用户 心理健康辅导链路的心理健康大模型,由 InternLM2 指令微…

BLIP2——采用Q-Former融合视觉语义与LLM能力的方法
BLIP2——采用Q-Former融合视觉语义与LLM能力的方法 FesianXu 20240202 at Baidu Search Team 前言
大规模语言模型(Large Language Model,LLM)是当前的当红炸子鸡,展现出了强大的逻辑推理,语义理解能力,而视觉作为人…

ChatGPT生产力|chat gpt实战介绍
标注说| ⭐ : 使用稳定,推荐 | 😄 : 免费使用 | 🔑 : 需要登陆或密码 | ✈️ : 需waiwang进行访问 | ChatGPT
1PoePoe - Fast, Helpful ...🔑😄🔗2 AItianhuGPT4😄⭐🔗3 PhantoNa…

用通俗易懂的方式讲解:大模型微调方法总结
大家好,今天给大家分享大模型微调方法:LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning。
文末有大模型一系列文章及技术交流方式,传统美德不要忘了,喜欢本文记得收藏、关注、点赞。 文章目录 1、LoRA…

【AI视野·今日NLP 自然语言处理论文速览 第八十三期】Wed, 6 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 6 Mar 2024 Totally 74 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets Authors Hossein Aboutalebi, …

大模型思维链(CoT prompting)
思维链(Chain of Thought,CoT)
**CoT 提示过程是一种大模型提示方法,它鼓励大语言模型解释其推理过程。**思维链的主要思想是通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程,大语言模型在…


【 书生·浦语大模型实战营】学习笔记(一):全链路开源体系介绍
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、…
Alluxio AI 全新产品发布:无缝对接低成本对象存储 AI 训练解决方案
(2023 年 10 月 19 日,北京)Alluxio 作为一家承载各类数据驱动型工作负载的数据平台公司,现推出全新的 Alluxio Enterprise AI 高性能数据平台, 旨在满足人工智能 (AI) 和机器学习 (ML) 负载对于企业数据基础设施不断增长的需求。…

LLM推理框架Triton Inference Server学习笔记(一): Triton Inference Server整体架构初识
官方文档查阅: TritonInferenceServer文档
1. 写在前面
这篇文章开始进行大语言模型(Large Language Model, LLM)的学习笔记整理,这次想从Triton Inference Server框架开始,因为最近工作上用到了一些大模型部署方面的知识, 所以就快速补充了…

【LLM】主流大模型体验(文心一言 科大讯飞 字节豆包 百川 阿里通义千问 商汤商量)
note
智谱AI体验百度文心一言体验科大讯飞大模型体验字节豆包百川智能大模型阿里通义千问商汤商量简要分析:仅从测试“老婆饼为啥没有老婆”这个问题的结果来看,chatglm分点作答有条理(但第三点略有逻辑问题);字节豆包…
Nature Methods - method to watch 用于基因组学的大模型
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 在人工智能(AI)和大语言模型(LLMs)背景下,基础模型是开发更专业和更高级模型的基础,它代表了对语言和各种任务的全面而概括的理解,是建立更专业模型的基础。OpenAI …

目前国内体验最佳的AI问答助手:kimi.ai
文章目录 简介图片理解长文档解析 简介
kimi.ai是国内初创AI公司月之暗面推出的一款AI助手,终于不再是四字成语拼凑出来的了。这是一个非常存粹的文本分析和对话工具,没有那些东拼西凑花里胡哨的AIGC功能,实测表明,这种聚焦是对的…

2024年大模型面试准备(三):聊一聊大模型的幻觉问题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
合集在这…

部署快捷、使用简单、推理高效!大模型部署和推理框架 Xinference 来了!
今天为大家介绍一款大语言模型(LLM)部署和推理工具——Xinference[1],其特点是部署快捷、使用简单、推理高效,并且支持多种形式的开源模型,还提供了 WebGUI 界面和 API 接口,方便用户进行模型部署和推理。 …
【基础知识】DPO(Direct Preference Optimization)的原理以及公式是怎样的?
论文:Direct Preference Optimization: Your Language Model is Secretly a Reward Model 1.基本原理
DPO(Direct Preference Optimization)的核心思想是直接优化语言模型(LM)以符合人类偏好,而不是首先拟…
MetaAI提出全新验证链框架CoVE,大模型也可以通过“三省吾身”来缓解幻觉现象
论文名称: Chain-of-Verification Reduces Hallucination in Large Language Models 论文链接: https://arxiv.org/abs/2309.11495 曾子曰:“吾日三省吾身” --出自《论语学而》
时至今日,生成幻觉(hallucination&…
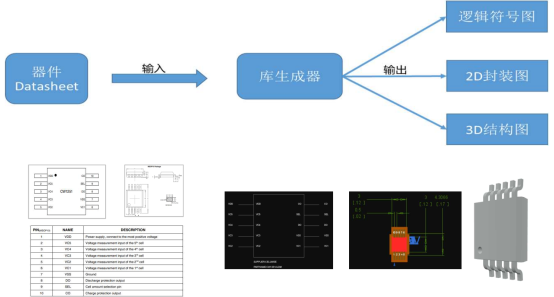
华为第二批难题一:基于预训练AI模型的元件库生成
我的理解:华为的这个难道应该是想通过大模型技术,识别元件手册上的图文内容,与现有建库工具结合,有潜力按标准生成各种库模型。
正好,我们正在研究,利用知识图谱技术快速生成装配模型,其中也涉…

『大模型笔记』LLMs入门:从头理解与编码LLM的自注意力机制
LLMs入门:从头理解与编码LLM的自注意力机制 这里直接引用我语雀上的的文章:《从头理解与编码LLM的自注意力机制》
【AI视野·今日NLP 自然语言处理论文速览 第三十七期】Wed, 20 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 20 Sep 2023 Totally 64 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
SlimPajama-DC: Understanding Data Combinations for LLM Training Authors Zhiqiang Shen, Tianhua Tao, Li…
混合专家模型(MoE)2022-2023顶会顶刊论文合集,包含算法、系统、应用3大类
混合专家模型(MoE)是一种深度学习技术,它通过将多个模型(这些模型被称为"专家")直接结合在一起,以加快模型训练的速度,获得更好的预测性能。这种模型设计策略在大模型中尤为重要&…
重磅!大模型(LLMs)排行榜清单发布!
目前,人工智能领域呈现出一片蓬勃发展的景象,大型模型成为了激发这一繁荣的关键引擎。
国内不仅涌现了众多大模型,而且它们的发展速度之快令人瞩目。这种全面拥抱大型模型的态势为整个人工智能生态系统赋予了新的活力,让我们对国…
xinference - 大模型分布式推理框架
文章目录 关于 xinference使用1、启动 xinference设置其他参数 2、加载模型3、模型交互 其它报错处理 - transformer.wte.weight 关于 xinference
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。 可用于大语言模型ÿ…
论文精读GAN: Generative Adversarial Nets
1 基础背景2 优缺点3 未来发展趋势 1 基础背景
论文链接:https://arxiv.org/abs/1406.2661 源码地址:http://www.github.com/goodfeli/adversarial
2 优缺点
优点: 避免了过拟合。因为生成器没有直接接触样本,而是通过判别器告…

LLM 时代,如何优雅地训练大模型?
原作者王嘉宁 基于https://wjn1996.blog.csdn.net/article/details/130764843 整理 大家好,ChatGPT于2022年12月初发布,震惊轰动了全世界,发布后的这段时间里,一系列国内外的大模型训练开源项目接踵而至,例如Alpaca、B…

基于 GPT 和 Qdrant DB 向量数据库, 我构建了一个电影推荐系统
电影推荐系统自从机器学习时代开始以来就不断发展,逐步演进到当前的 transformers 和向量数据库的时代。
在本文中,我们将探讨如何在向量数据库中高效存储数千个视频文件,以构建最佳的推荐引擎。 在众多可用的向量数据库中,我们将…
【LangChain学习之旅】—(19)BabyAGI:根据气候变化自动制定鲜花存储策略
【LangChain学习之旅】—(19)BabyAGI:根据气候变化自动制定鲜花存储策略 AutoGPTBaby AGIHuggingGPTLangChain 目前是将基于 CAMEL 框架的代理定义为 Simulation Agents(模拟代理)。这种代理在模拟环境中进行角色扮演,试图模拟特定场景或行为,而不是在真实世界中完成具体…
大模型LLM 在线量化;GPTQ\AWQ量化及推理
1、大模型LLM 在线量化
参考:https://www.cnblogs.com/bruceleely/p/17348782.html
trust_remote_code=True 一般都需要加上,不然会报错(Tokenizer class QWenTokenizer does not exist or is not currently imported)
##8bit
model = AutoModel.from_pretrained("…

用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
近年来,大型语言模型(LLM)取得了显著的进步,然而大模型缺点之一是幻觉问题,即“一本正经的胡说八道”。其中RAG(Retrieval Augmented Generation,检索增强生成)是解决幻觉比较有效的…

GPT-1, GPT-2, GPT-3, GPT-3.5, GPT-4论文内容解读
目录 1 ChatGPT概述1.1 what is chatGPT1.2 How does ChatGPT work1.3 The applications of ChatGPT1.3 The limitations of ChatGPT 2 算法原理2.1 GPT-12.1.1 Unsupervised pre-training2.1.2 Supervised fine-tuning2.1.3 语料2.1.4 分析 2.2 GPT-22.3 GPT-32.4 InstructGPT…
DB-GPT安装部署使用初体验
DB-GPT是什么?引自官网: DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。 目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、…
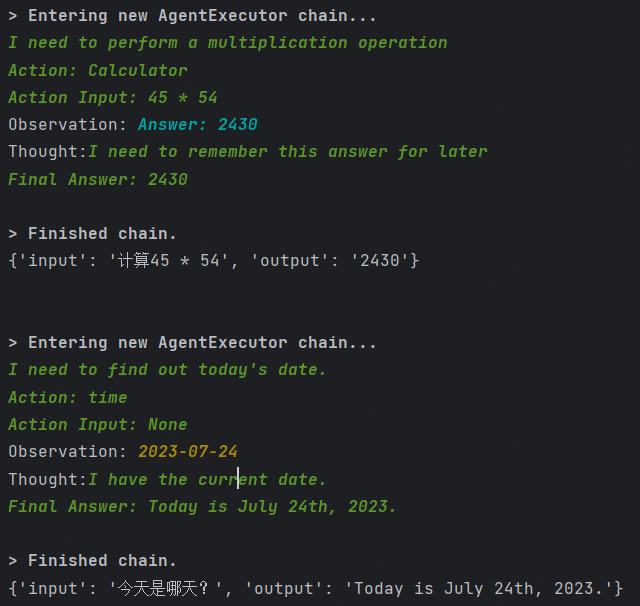
我用 LangChain 打造自己的 LLM 应用项目
随着LLM的技术发展,其在业务上的应用越来越关键,通过LangChain大大降低了LLM应用开发的门槛。本文通过介绍LangChain是什么,LangChain的核心组件以及LangChain在实际场景下的使用方式,希望帮助大家能快速上手LLM应用的开发。
技术…
大模型的 Token 使用详解:限制与注意事项
在大型语言模型中,Token 是指文本处理的基本单位,通常是单词、短语或句子的一部分。Tokenization 是将输入文本分割成一系列 Token 的过程,它是自然语言处理(NLP)任务中的关键步骤。了解 Token 的使用限制和注意事项对…

CodeFuse - 蚂蚁集团开源代码大模型
文章目录 关于 CodeFuse模型CodeFuse-13BCodeFuse-CodeLlama-34B-4bitsCodeFuse-CodeLlama-34BCodeFuse-StarCoder-15BMFTCoderFasterTransformer4CodeFuse关于 CodeFuse github : https://github.com/codefuse-aihuggingface : https://huggingface.co/codefuse-ai查看模型的 …

【LLM加速】注意力优化(基于位置/内容的稀疏注意力 | flashattention)
note
(1)近似注意力:
Routing Transformer采用K-means 聚类方法,针对Query和Key进行聚类,类中心向量集合为 { μ i } i 1 k \left\{\boldsymbol{\mu}_i\right\}_{i1}^k {μi}i1k ,其中k 是类中心的…
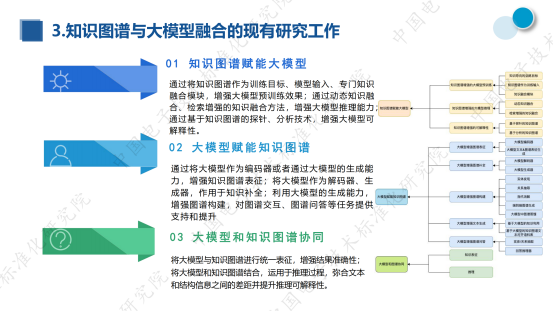
《知识图谱与大模型融合实践研究报告》发布,创邻科技参编
近期,第三届知识图谱产业发展论坛暨知识图谱与大模型融合研讨会在北京召开。会上,《知识图谱与大模型融合实践研究报告》正式发布!
该白皮书是由中国电子技术标准化研究院依托知识图谱产业推进方阵、全国信标委人工智能分委会知识图谱工作组…
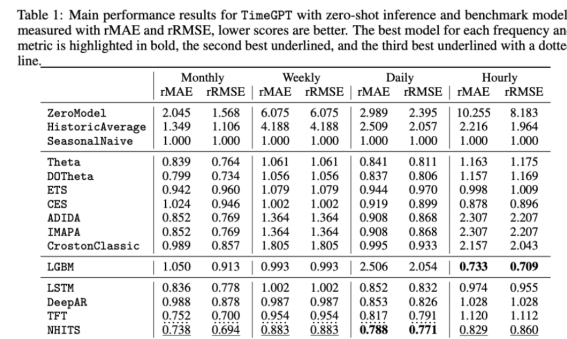
TimeGPT:时序预测领域终于迎来了第一个大模型
时间序列预测领域在最近的几年有着快速的发展,比如N-BEATS、N-HiTS、PatchTST和TimesNet。
大型语言模型(llm)最近在ChatGPT等应用程序中变得非常流行,因为它们可以适应各种各样的任务,而无需进一步的训练。
这就引出了一个问题:时间序列的…
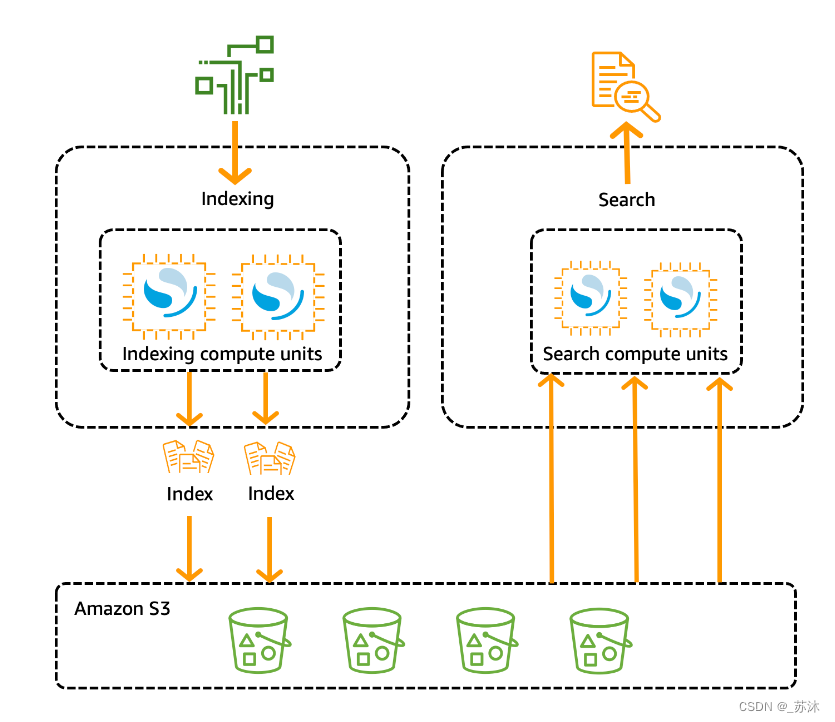
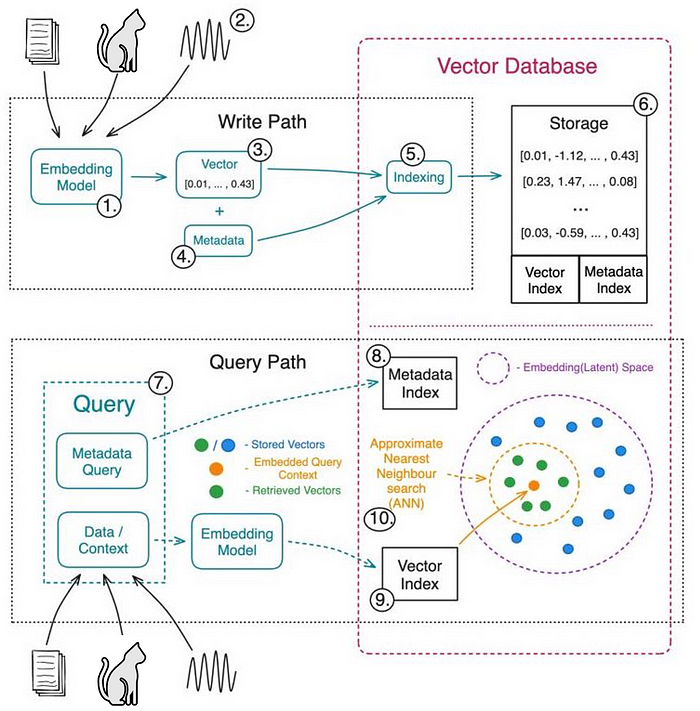
随着大模型中数据局限问题的严峻化,向量数据库应运而生
向量数据库与亚马逊大模型 什么是向量数据库 向量嵌入(vector embedding)已经无处不在。它们构成了许多机器学习和深度学习算法的基础,被广泛运用于各种应用,从搜索引擎到智能助手再到推荐系统等。通常,机器学习和深度…
汇总开源大模型的本地API启动方式
文章目录 CodeGeex2ChatGLM2_6BBaichuan2_13Bsqlcoder开启后测试 CodeGeex2
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
import argparse
try:import chatglm_cppenable_chatglm_…
AI趋势(06) Sora,AI对世界的新理解
说明:使用 黄金圈法则学习和解读Sora(what、why、how) 1 Sora是什么?
1.1 Sora的基本解读
Sora是OpenAl在2024年2月16日发布的首个文本生成视频模型。该模型能够根据用户输入的文本自动生成长达60秒的1080p复杂场景视频…
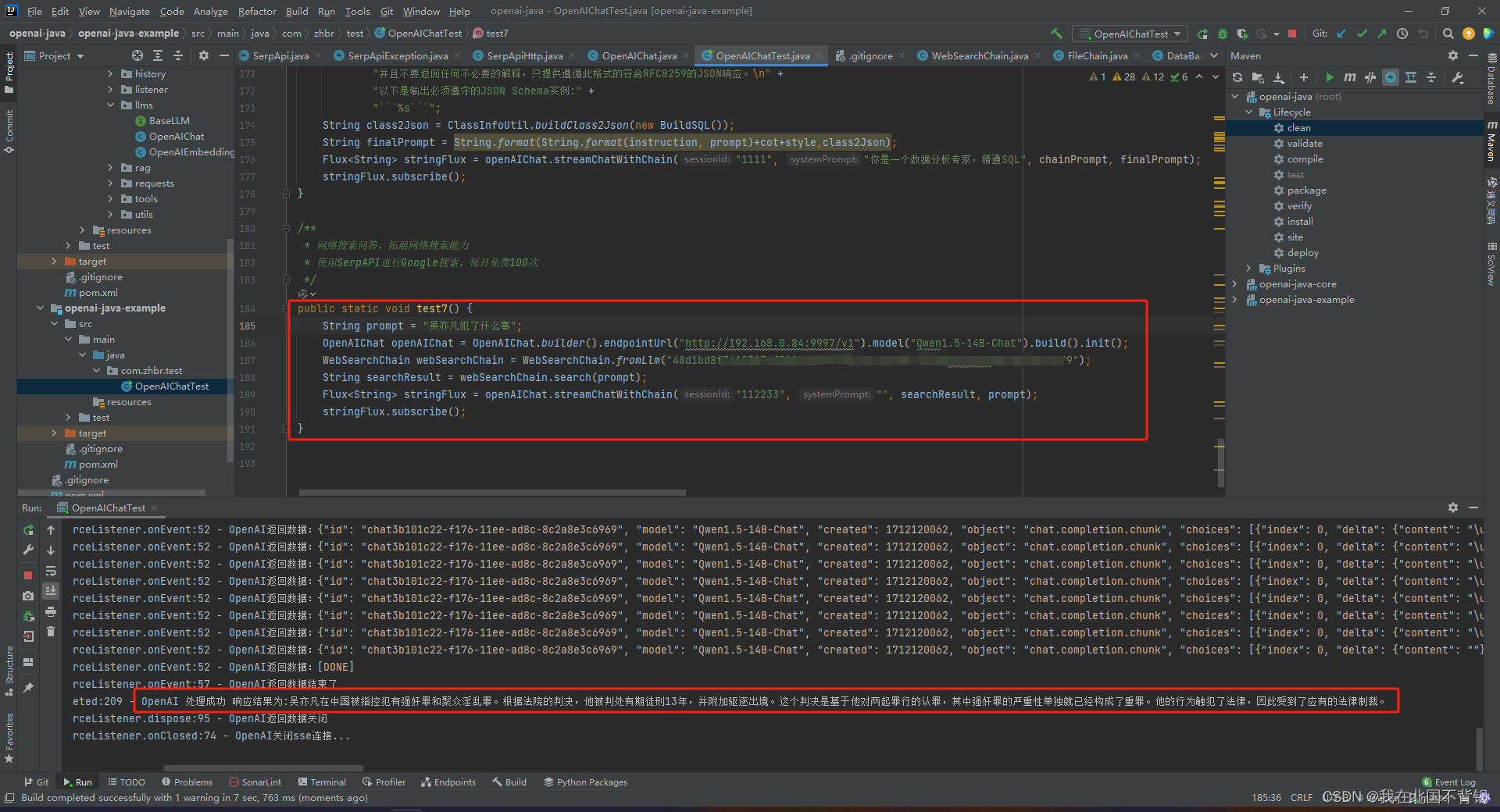
使用Java拓展本地开源大模型的网络搜索问答能力
背景
开源大模型通常不具备最新语料的问答能力。因此需要外部插件的拓展,目前主流的langChain框架已经集成了网络搜索的能力。但是作为一个倔强的Java程序员,还是想要用Java去实现。
注册SerpAPI
Serpapi 提供了多种搜索引擎的搜索API接口。 访问 Ser…

微软最新10道算法岗面试题!
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总…


五倍吞吐量,性能全面包围 Transformer:新架构 Mamba 引爆AI圈
屹立不倒的 Transformer 迎来了一个强劲竞争者。 在别的领域,如果你想形容一个东西非常重要,你可能将其形容为「撑起了某领域的半壁江山」。但在 AI 大模型领域,Transformer 架构不能这么形容,因为它几乎撑起了「整个江山」。
自…
最强文生图跨模态大模型:Stable Diffusion
文章目录 一、概述二、Stable Diffusion v1 & v22.1 简介2.2 LAION-5B数据集2.3 CLIP条件控制模型2.4 模型训练 三、Stable Diffusion 发展3.1 图形界面3.1.1 Web UI3.1.2 Comfy UI 3.2 微调方法3.1 Lora 3.3 控制模型3.3.1 ControlNet 四、其他文生图模型4.1 DALL-E24.2 I…
Prompt Engineering | 文本扩展prompt
😄 扩展是将短文本,例如一组说明或主题列表,输入到大型语言模型中,让模型生成更长的文本,例如基于某个主题的电子邮件或论文。这样做有一些很好的用途,例如将大型语言模型用作头脑风暴的伙伴。但这种做法也…
babyAGI(6)-babyCoder源码阅读2任务描述部分
废话不多说,我们直接看task的prompt 这里需要注意的是,每个openai_call的temperature都不相同,这也是开发程序时需要调整和关注的一点
1. 初始化代码任务agent
作为babycoder的第一个angent,整个prompt编写的十分值得学习 整个p…
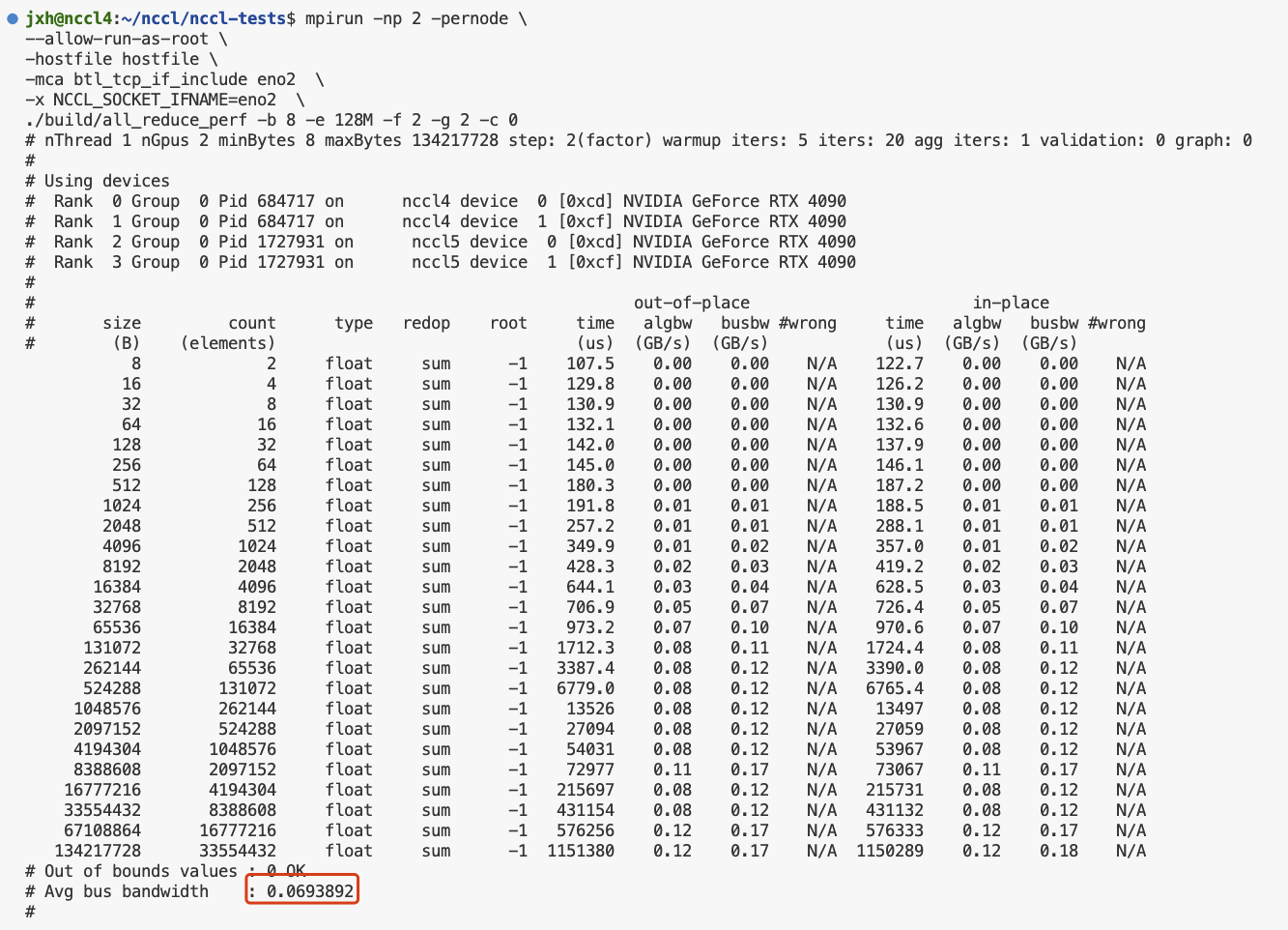
多机多卡运行nccl-tests和channel获取
nccl-tests 环境1. 安装nccl2. 安装openmpi3. 单机测试4. 多机测试mpirun多机多进程多节点运行nccl-testschannel获取 环境
Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)cuda 11.8 cudnn 8nccl 2.15.1NVIDIA GeForce RTX 4090 *2
1. 安装nccl
#查看cuda版本
nv…
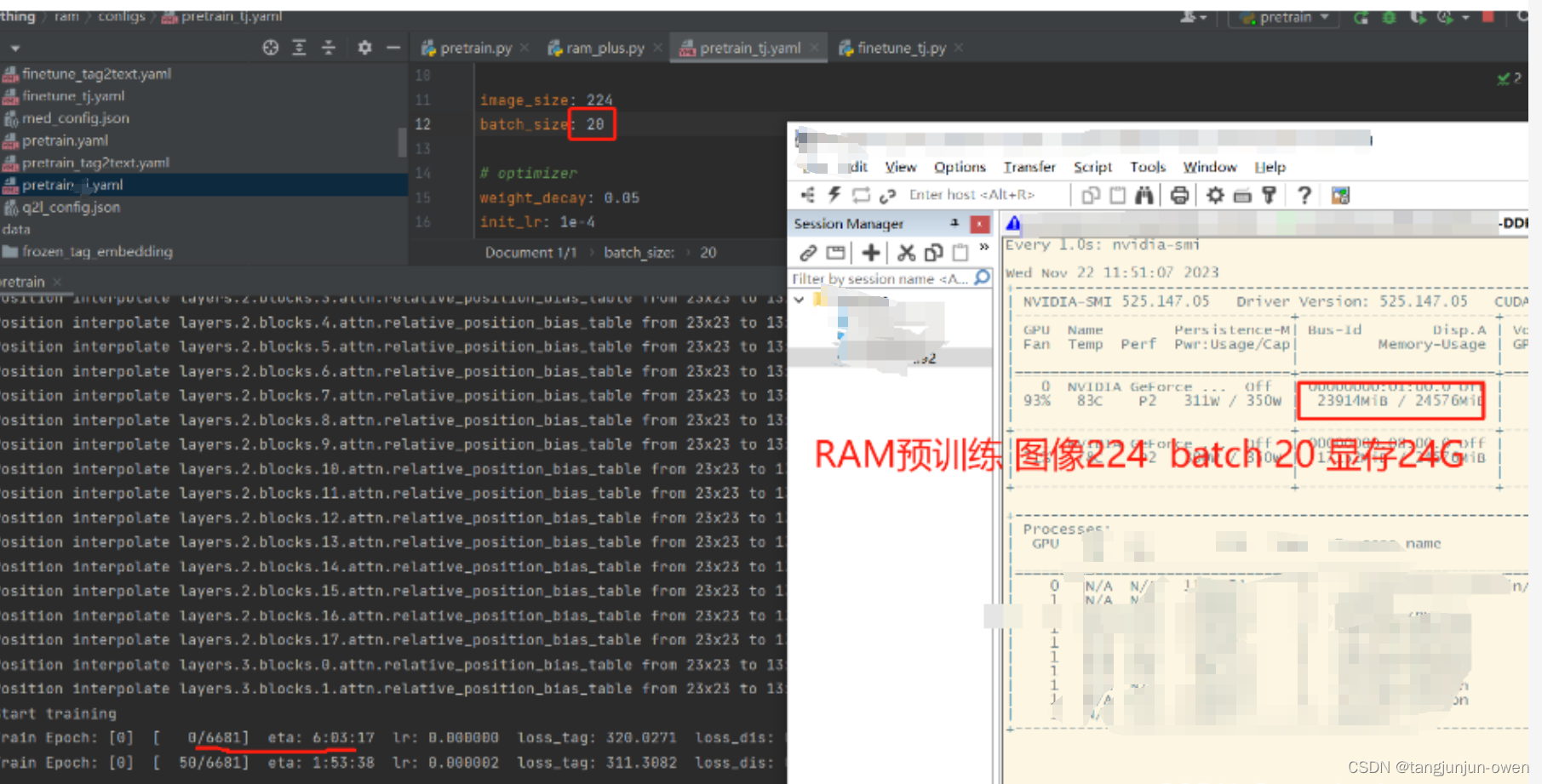
RAM模型从数据准备到pretrain、finetune与推理全过程详细说明
提示:RAM模型:环境安装、数据准备与说明、模型推理、模型finetune、模型pretrain等 文章目录 前言一、环境安装二、数据准备与解读1.数据下载2.数据标签内容解读3.标签map内容解读 三、finetune训练1.微调训练命令2.load载入参数问题3.权重载入4.数据加载…

大模型视觉理解能力更进一步,谷歌提出全新像素级对齐模型PixelLLM
论文题目:Pixel Aligned Language Models 论文链接:https://arxiv.org/abs/2312.09237 项目主页:Pixel Aligned Language Models 近一段时间以来,大型语言模型(LLM)在计算机视觉领域中也取得了巨大的成功&a…
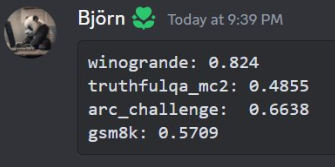
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
本文来自DataLearnerAI官方网站:
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般! | 数据学习者官方网站(Datal…
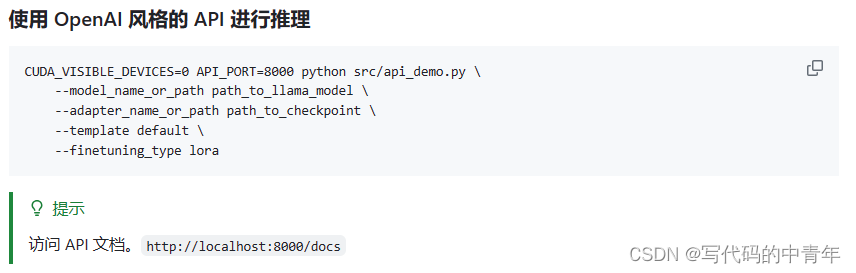
从零开始的LLaMA-Factory的指令增量微调
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。
大模型应用向开发路径及一点个人思考大模型应用开发实用开源项目汇总大模型问答项目…
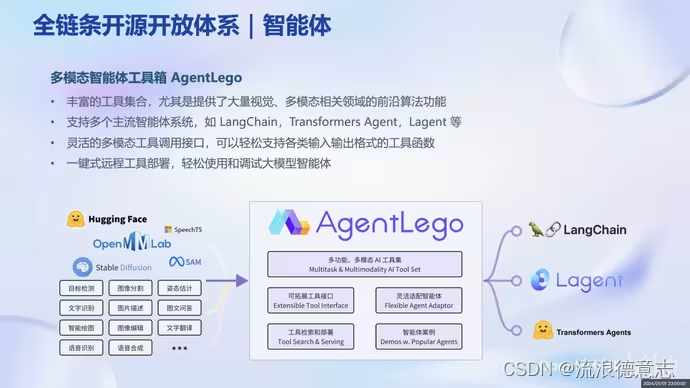
大模型实战营Day1 书生·浦语大模型全链路开源体系
1.大模型为发展通用人工智能的重要途经
专用模型:针对特定任务解决特定问题 通用大模型:一个模型对应多模态多任务 2.InternLM大模型开源历程 3.InternLM-20B大模型性能 4.从模型到应用:智能客服、个人助手、行业应用 5.书生浦语全链条开源…
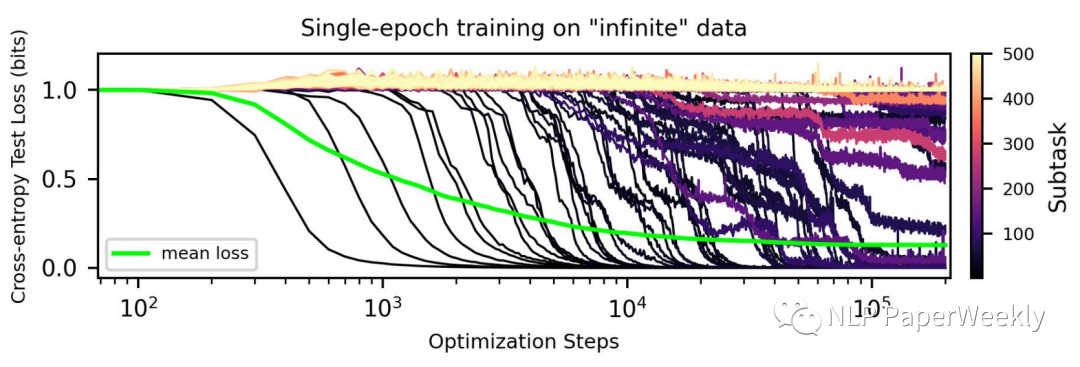
符尧:别卷大模型训练了,来卷数据吧!【干货十足】
大家好,我是HxShine。
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程(data engineering)包括mix ratio(数据混合…
面向C#初学者的JSON入门与实践
本篇为21天速通C#专栏最后一篇,前面的已经基本囊括C#基础所有内容,JOSN对C#来说,可能有些人认为不是很重要,但可以不精通,不能不知道,本篇仅做入门讲解和实践,对C#有兴趣可以订阅专栏,从C#简介开始添加链接描述可以说是零基础入门。
引言
J…
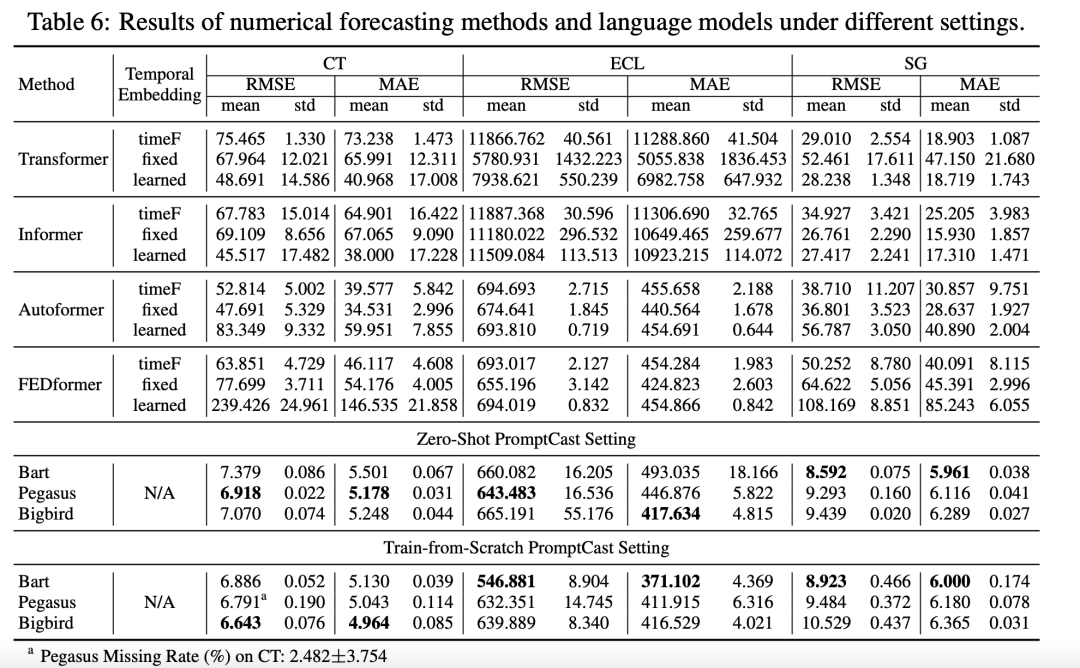
PromptCast:基于提示学习的时序预测模型!
目前时序预测的SOTA模型大多基于Transformer架构,以数值序列为输入,如下图的上半部分所示,通过多重编码融合历史数据信息,预测未来一定窗口内的序列数值。
受到大语言模型提示工程技术的启发,文章提出了一种时序预测新…
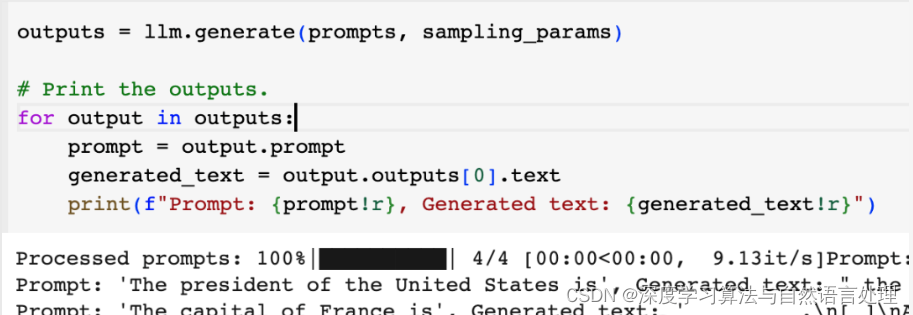
利用免费 GPU 部署体验大型语言模型推理框架 vLLM
vLLM简介
vLLM 是一个快速且易于使用的 LLM(大型语言模型)推理和服务库。
vLLM 之所以快速,是因为: 最先进的服务吞吐量 通过 PagedAttention 高效管理注意力键和值内存 连续批处理传入请求 使用 CUDA/HIP 图快速模型执行 量…
MetaGPT-打卡day01
MetaGPT是一个基于大型语言模型(LLMs)的多智能体协作框架。它利用SOP(Standard Operating Procedures,标准作业程序)来协调基于大语言模型的多智能体系统,从而实现元编程技术。该框架使用智能体模拟了一个虚…


大模型平民化技术之LORA
1. 引言
在这篇博文中, 我将向大家介绍LoRA技术背后的核心原理以及相应的代码实现。
LoRA 是 Low-Rank Adaptation 或 Low-Rank Adaptors 的首字母缩写词,它提供了一种高效且轻量级的方法,用于微调预先训练好的的大语言模型。这包括 BERT 和…
以桨为楫 修己度人(四)
目录 1.人工智能开创的新时代 2.使命开启飞桨一春独占 3.技术突破奠定飞桨品牌一骑绝尘 4.行业应用积淀飞桨品牌一枝独秀 5.生态传播造就飞桨品牌一众独妍 6.深度学习平台的现状和未来思考
深度学习平台的现状和未来思考 作为我国首个功能丰富、开源开放的深度学习中文平台&am…

deepspeed多机多卡并行训练指南
文章目录 前言离线配置训练环境共享文件系统多台服务器之间配置互相免密登录pdsh多卡训练可能会碰到的问题注意总结 前言
我的配置:
7机14卡,每台服务器两张A800
问:为啥每台机只挂两张卡? 答:给我的就这样的&#…

百度智能云“千帆大模型平台”升级,大模型最多,Prompt模板最全
1、前言 从ChatGPT正式推出之后,大模型开始逐渐火爆起来,基于大模型的潜力与广泛应用前景,多个厂商也开始在大模型领域进行深耕布局。越来越多的人也开始尝试使用大模型来解决日常工作或生活中的问题,有效地提高了处理问题的效率。…
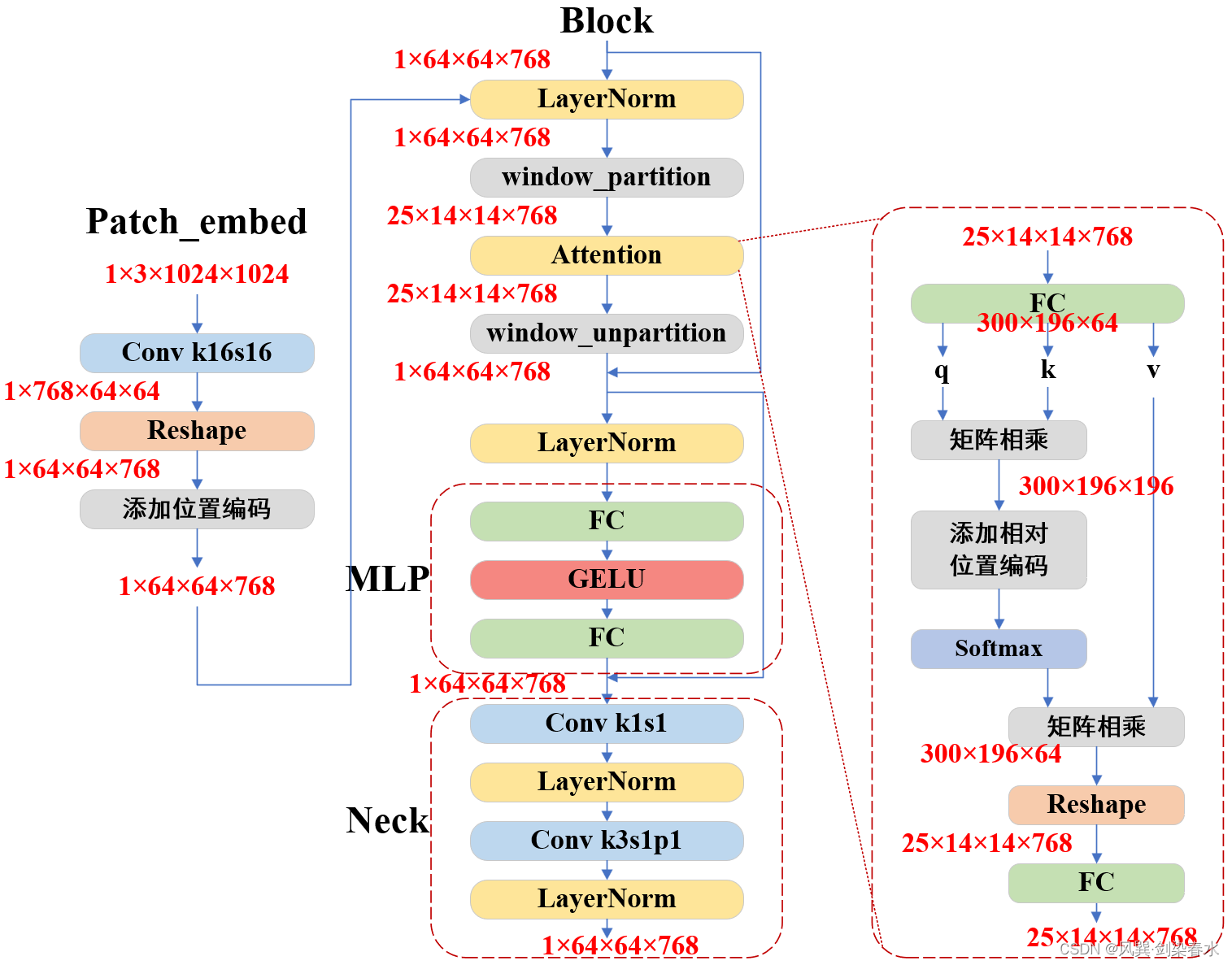
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Image Encoder
论文:Segment Anything 代码:https://github.com/facebookresearch/segment-anything
1. 使用SAM 尽管官方demo玩的很花很溜,但只有能够本地运行起来,才能够查看中间过程不是,基于这篇文章,使用官方的…

开源vs闭源,处在大模型洪流中,向何处去?
文章目录 一、开源和闭源的优劣势比较1.1 开源优势1.2 闭源的优势 二、开源和闭源对大模型技术发展的影响2.1 数据共享2.2 算法创新2.3 业务拓展2.4 安全性和隐私2.5 社会责任和伦理 三、开源与闭源的商业模式比较3.1 盈利模式3.2 市场竞争3.3 用户生态3.4 创新速度 四…

Prompt的技巧持续总结
Prompt 有很多网站已经收录了,比如:aimappro 有些直接抄上述网站的作业即可,不过也来看看, 有一些日常提问大概的咒语该怎么写。
1 三种微调下的提示写法
chatgpt时代的创新:LLM的应用模式比较 实际案例说明AI时代大…

一文了解大模型工作原理——以ChatGPT为例
文章目录 写在前面1.Tansformer架构模型2.ChatGPT原理3.提示学习与大模型能力的涌现3.1 提示学习3.2 上下文学习3.3 思维链 4.行业参考建议4.1 拥抱变化4.2 定位清晰4.3 合规可控4.4 经验沉淀 写在前面 2022年11月30日,ChatGPT模型问世后,立刻在全球范围…
大模型从入门到应用——LangChain:链(Chains)-[链与索引:问答的基础知识]
分类目录:《大模型从入门到应用》总目录 本文介绍如何使用LangChain在文档列表上进行问答。它涵盖了四种不同的链式类型:
stuffmap_reducerefinemap_rerank
首先,我们需要准备数据,我们对一个向量数据库进行相似性搜索ÿ…
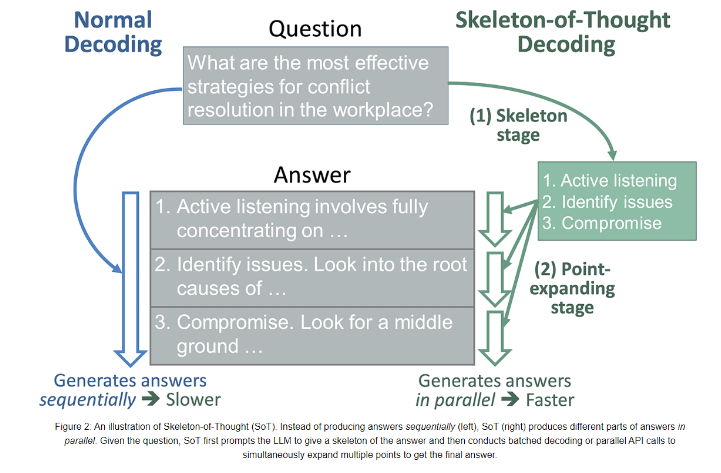
清华大学提出全新加速训练大模型方法SoT
近日,微软研究和清华大学的研究人员共同提出了一种名为“Skeleton-of-Thought(SoT)”的全新人工智能方法,旨在解决大型语言模型(LLMs)生成速度较慢的问题。
尽管像GPT-4和LLaMA等LLMs在技术领域产生了深远影响,但其处…
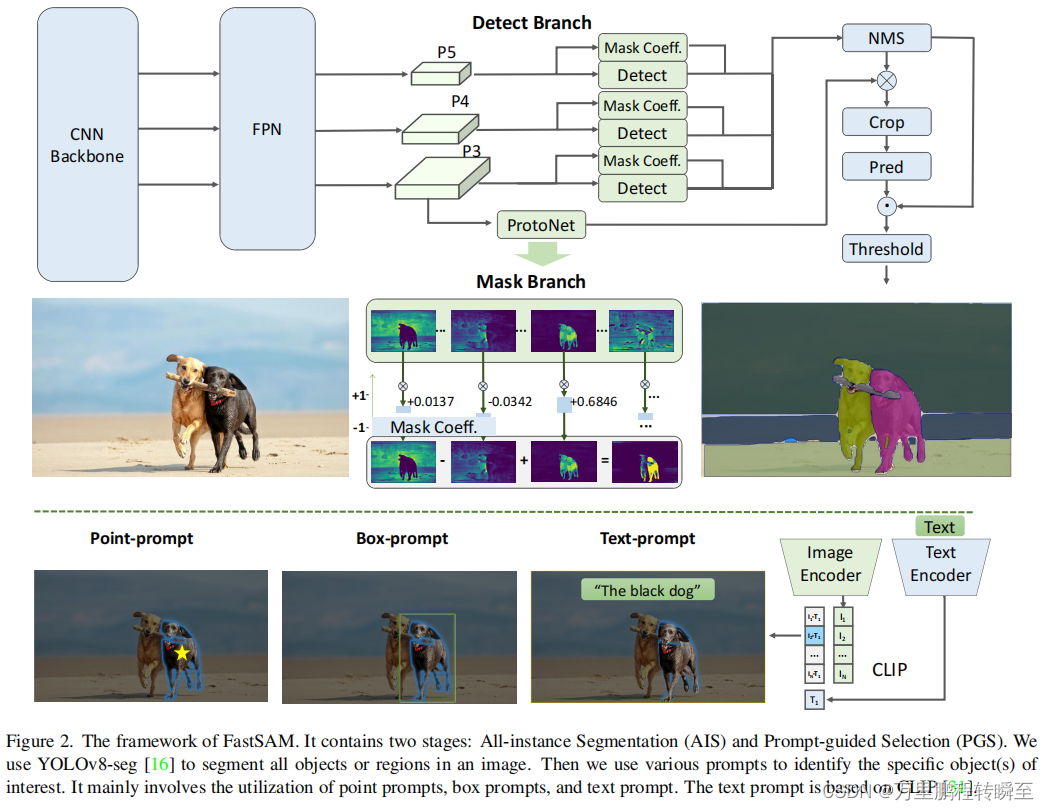
如何实现sam(Segment Anything Model)|fastsam模型
sam是2023年提出的一个在图像分割领域的大模型,其具备了对任意现实数据的分割能力,其论文的介绍可以参考 https://hpg123.blog.csdn.net/article/details/131137939,sam的亮点在于提出一种工作模式,同时将多形式的prompt集成到了语…
阿里巴巴的第二代通义千问可能即将发布:Qwen2相关信息已经提交HuggingFace官方的transformers库
本文来自DataLearnerAI官方网站:阿里巴巴的第二代通义千问可能即将发布:Qwen2相关信息已经提交HuggingFace官方的transformers库 | 数据学习者官方网站(Datalearner)
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿…
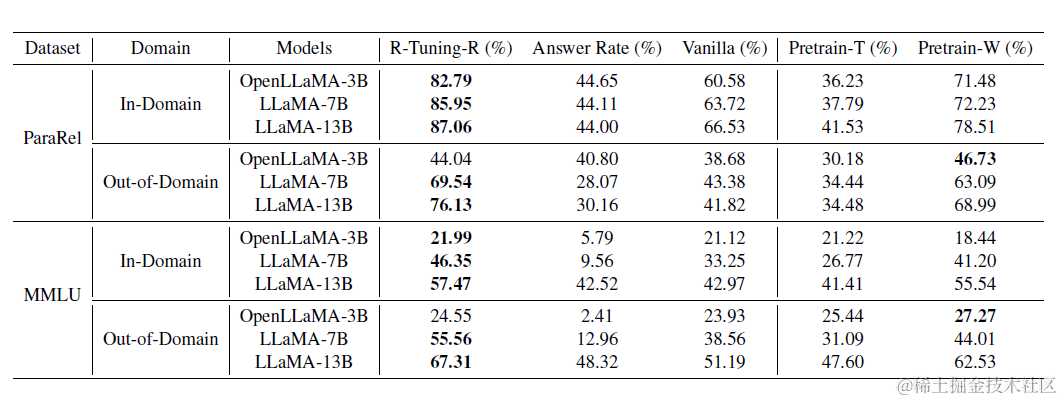
前置判断-Detection
检测模型回答存在幻觉可以通过检索外部知识进行校验,不过考虑生成式模型覆盖问题的广泛性,Self-Contradictory论文中评估chatgpt生成的回答中38.5%的内容无法通过Wiki等外部知识进行校验。
因此这里我们先介绍一种完全基于模型自身,不依赖外…

ChatGPT 使用 拓展资料:吴恩达大咖 Building Systems with the ChatGPT API 输出检查
ChatGPT 使用 拓展资料:吴恩达大咖 Building Systems with the ChatGPT API 输出检查 在本视频中,将重点检查系统生成的输出。在向用户展示输出之前检查输出对于确保质量非常重要,提供给他们的响应的相关性和安全性,或者使用自动化或学习如何使用Moderation API。
Moderati…
这应该是最全的大模型训练与微调关键技术梳理
作为算法工程师的你是否对如何应用大型语言模型构建医学问答系统充满好奇?是否希望深入探索LLaMA、ChatGLM等模型的微调技术,进一步优化参数和使用不同微调方式?现在我带大家领略大模型训练与微调进阶之路,拓展您的技术边界&#…
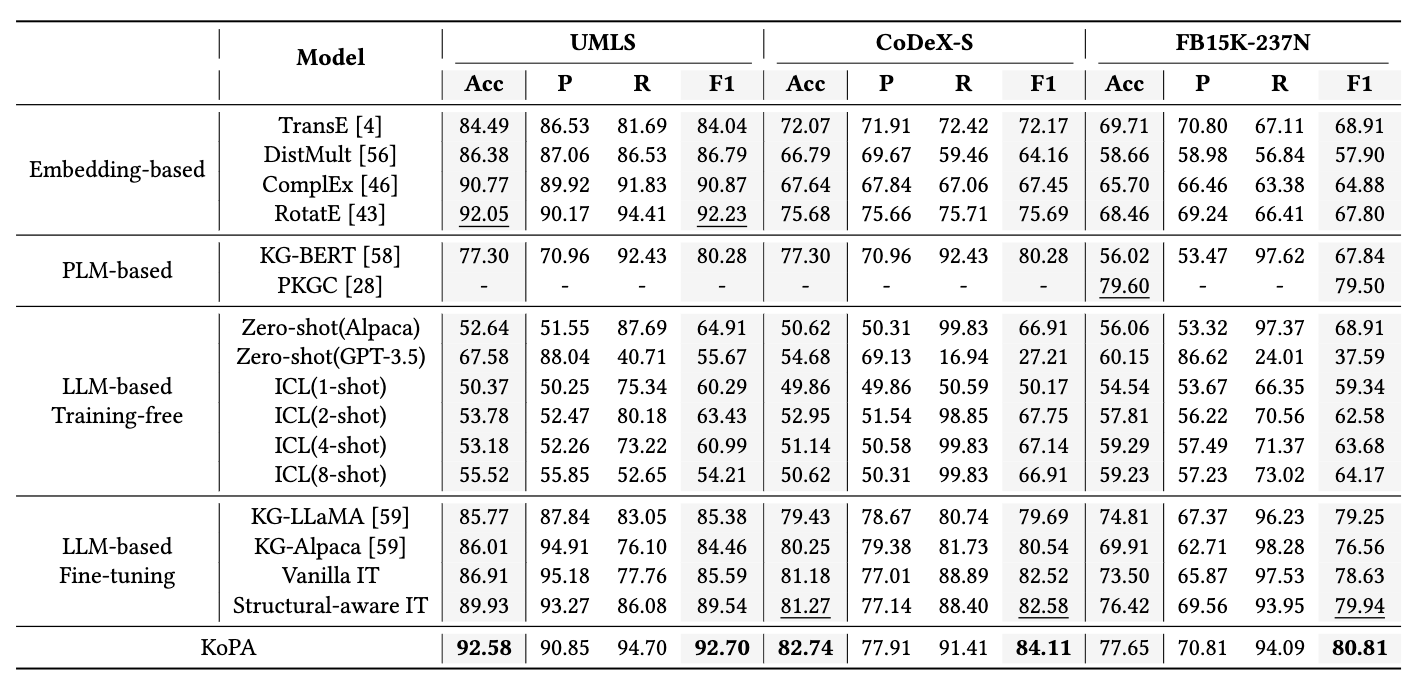
如何让大模型更好地完成知识图谱推理?
论文标题: Making Large Language Models Perform Better in Knowledge Graph Completion 论文链接: https://arxiv.org/abs/2310.06671 代码链接:GitHub - zjukg/KoPA: [Paper][Preprint 2023] Making Large Language Models Perform Be…

大模型推理加速框架vllm部署的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
国内20个大模型中文场景测评及体验
中文场景能力测评 SuperCLUE排行榜 大模型及网站 公司(大模型) 智能程度 借鉴点 体验网站 备注 1 百度文心一言 高 文心一言 2 百川智能 高 百川大模型-汇聚世界知识 创作妙笔生花-百川智能 3 商汤商量SenseChatÿ…
Prompt Engineering | 文本转换prompt
LLM非常擅长将输入转换成不同的格式,例如多语种文本翻译、拼写及语法纠正、语气调整、格式转换等。 文章目录 1、文本翻译1.1、中文转西班牙语1.2、识别语种1.3、多语种翻译1.4、翻译正式语气1.4、通用翻译器 2、语气 / 风格调整3、格式转换4、拼写及语法纠正5、一个…
本地部署清华大模型 ChatGLM3
ChatGLM 是一个开源的、支持中英双语的对话语言模型,由智谱 AI 和清华大学 KEG 实验室联合发布,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM3-6B 更是在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上增加…
极智AI | 有趣的羊驼系列大模型
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来介绍一下 有趣的羊驼系列大模型。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq "羊驼模型" 在大模型的介绍中应…
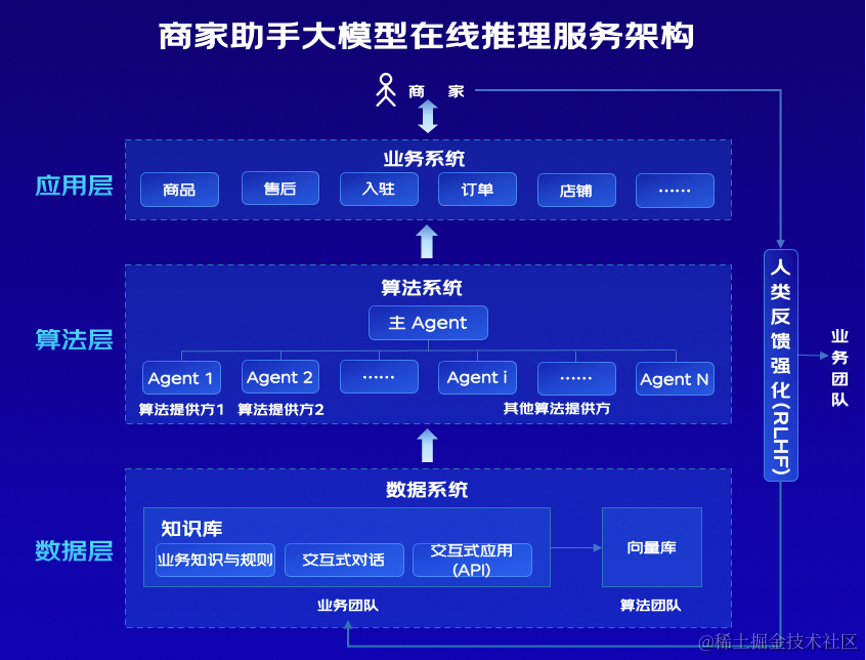
大模型基础应用框架(ReACT\SFT\RAG)创新及零售业务落地
如何将大语言模型的强大能力融入实际业务、产生业务价值,是现在很多公司关注的焦点。在零售场,大模型应用也面临很多挑战。本文分享了京东零售技数中心推出融合Agent、SFT与RAG的大模型基础应用框架,帮助业务完成大模型微调、部署和应用&…
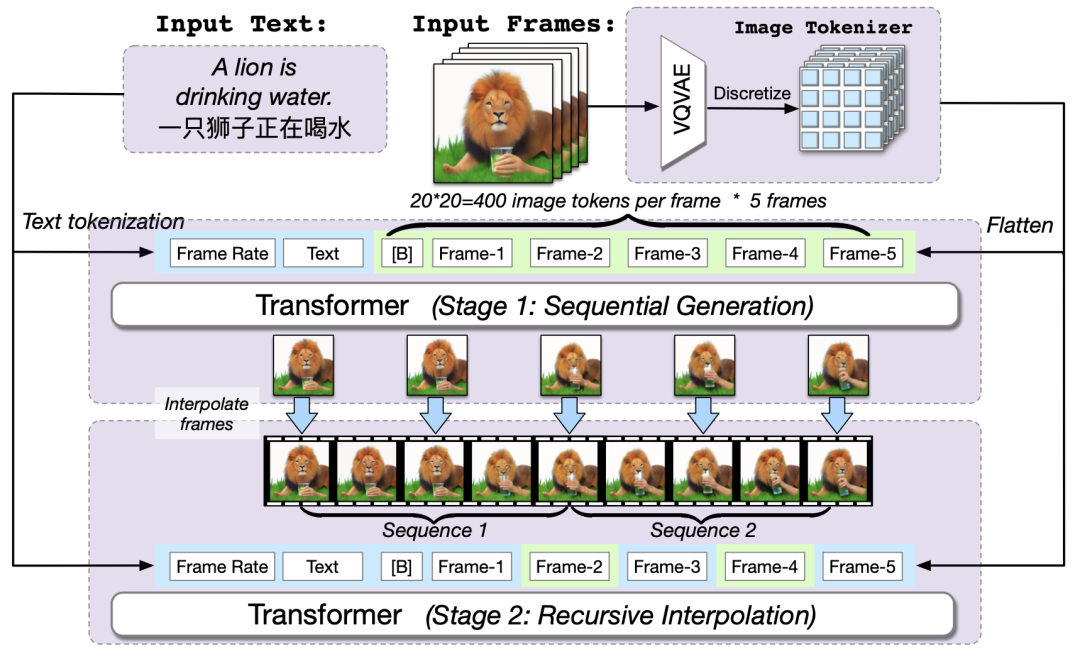
【LLM多模态】Cogview3、DALL-E3、CogVLM、CogVideo模型
note 文章目录 noteVisualGLM-6B模型图生文:CogVLM-17B模型1. 模型架构2. 模型效果 文生图:CogView3模型DALL-E3模型CogVideo模型网易伏羲-丹青模型Reference VisualGLM-6B模型
VisualGLM 是一个依赖于具体语言模型的多模态模型,而CogVLM则是…
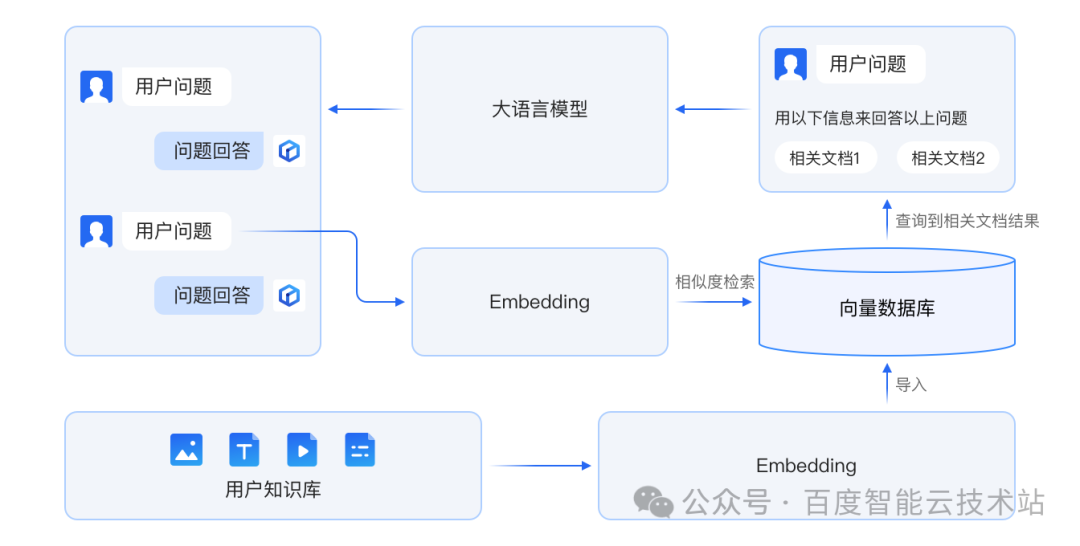
百度智能云发布专用向量数据库 VDB 1.0,全新设计内核开启性能狂飙
1 专用向量数据库应对未来业务挑战 向量数据库 向量检索 数据库 向量数据库大致可以分为 2 部分:向量数据的检索,以及向量数据的存储和管理。
向量数据库的性能,比如高 QPS、低延时等,使得业务能够更快的响应用户的查询请求…
RAG 新路径!提升开发效率、用户体验拉满
RAG(Retrieval-Augmented Generation)框架结合了强大的信息检索能力和生成模型的能力,允许系统从海量数据中检索相关信息,并基于这些信息生成准确、丰富的回答。随着大语言模型和智能问答技术的崛起,RAG 凭借其独特的结…
推荐收藏!九大最热门的开源大模型 Agent 框架来了
在人工智能领域,AI Agent 扮演着关键角色,能够模拟人类的智能行为。
近年来,开源社区涌现出多个优秀的 AI Agent 框架,本文将介绍九种备受关注的开源AI Agent框架,包括AutoGPT、AutoGen、Langfuse、ChatDev、BabyAGI、…
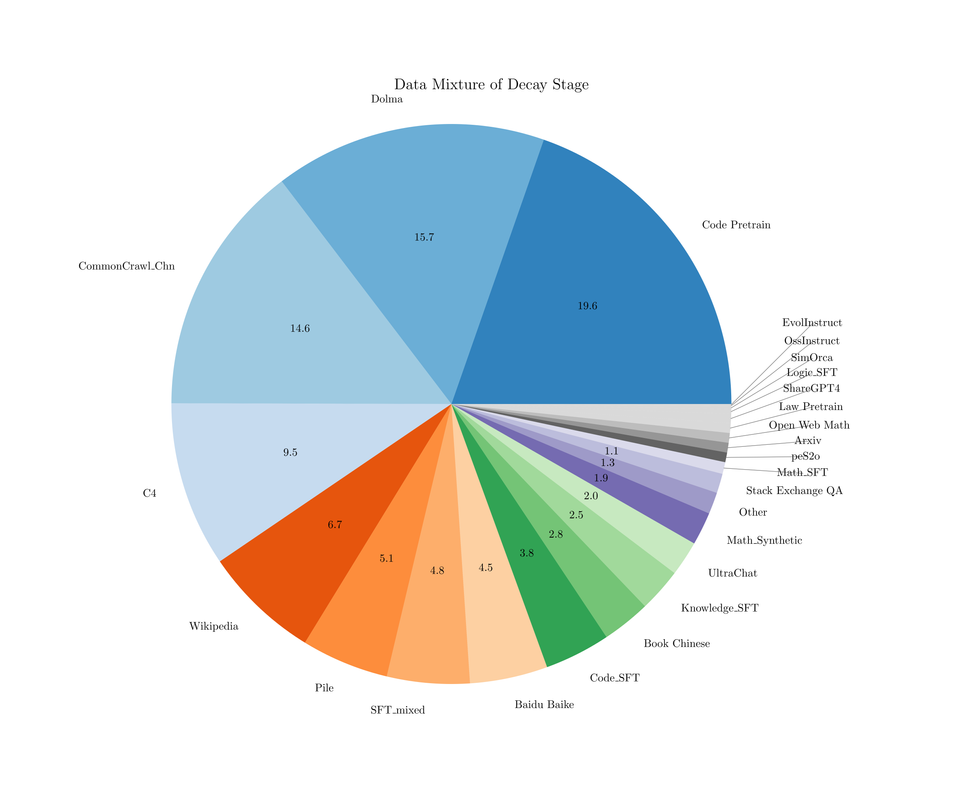
清华系2B模型杀出,性能吊打LLaMA-13B
2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B 仅有 24 亿(2.4B)的非词嵌入参数量。
在综合性榜单上与 Mistral-7B 相近,在中文、数学、代码能力表现…

大模型2024规模化场景涌现,加速云计算走出第二增长曲线
导读:2024,大模型第一批规模化应用场景已出现。 如果说“百模大战”是2023年国内AI产业的关键词,那么2024年我们将正式迈进“应用为王”的新阶段。 不少业内观点认为,2024年“百模大战”将逐渐收敛甚至洗牌,而大模型在…
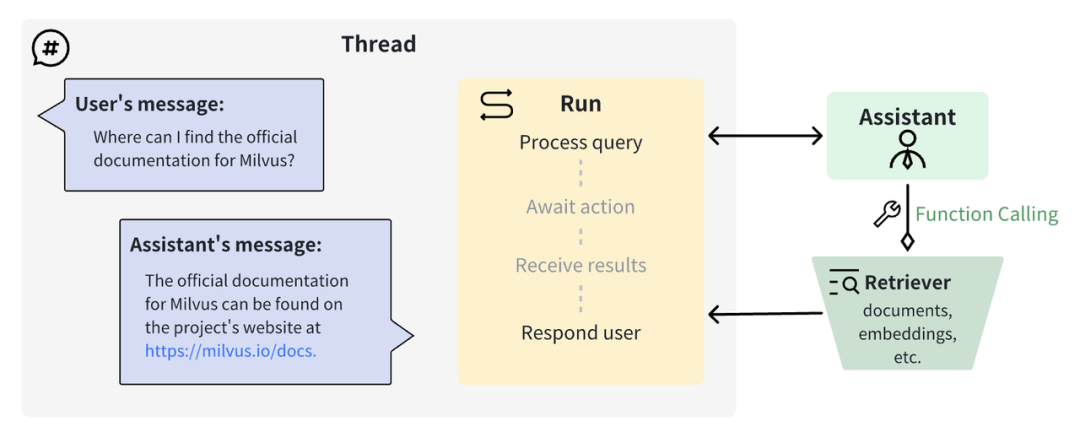
为什么大模型需要向量数据库?
AIGC 时代万物都可以向量化,向量化是 LLM 大模型以及 Agent 应用的基础。
比如:爆火的 Google 大模型 Gemini 1.0 原生支持的多模态,在预训练的时候就是把文本、图片、音频、视频等多模态先进行 token 化,然后构建一维的“语言”…
![[晓理紫]AI专属会议截稿时间订阅](https://img-blog.csdnimg.cn/direct/ffc767e11d5b42d08cb645a2f7321daa.jpeg#pic_center)
[晓理紫]AI专属会议截稿时间订阅
AI专属会议截稿时间订阅 关注{VX 晓理紫},每日更新最新AI专属会议信息,如感兴趣,请转发给有需要的同学,谢谢支持!! 如果你感觉对你有所帮助,请关注我,每日准时为你推送最新AI专属会议…

七天入门大模型 :提示词工程 Prompt Engineering,最全的总结来了!
文章目录 技术交流群用通俗易懂方式讲解系列引 言LLM 的超参配置Prompt Engineering指令主要内容少样本学习更加明确的提示善用分隔符思维链提示对输出格式的明确要求 最佳实践案例1. Agent场景:使用prompt实现agent create2. Agent场景:使用system mess…
OpenAI发布首个视频生成模型Sora:输文字即可出视频现实还存在吗?
就在刚刚,openai发布了全新的视频生成人工智能模型Sora。用户只要通过文字输入一些提示语,就可以得到一个高清视频。同时Sora还可以根据静态图像生成相关的视频剪辑,效果相当炸裂。
这下又要干倒一大片创业公司了
Sora官方网址
Sora
目前…
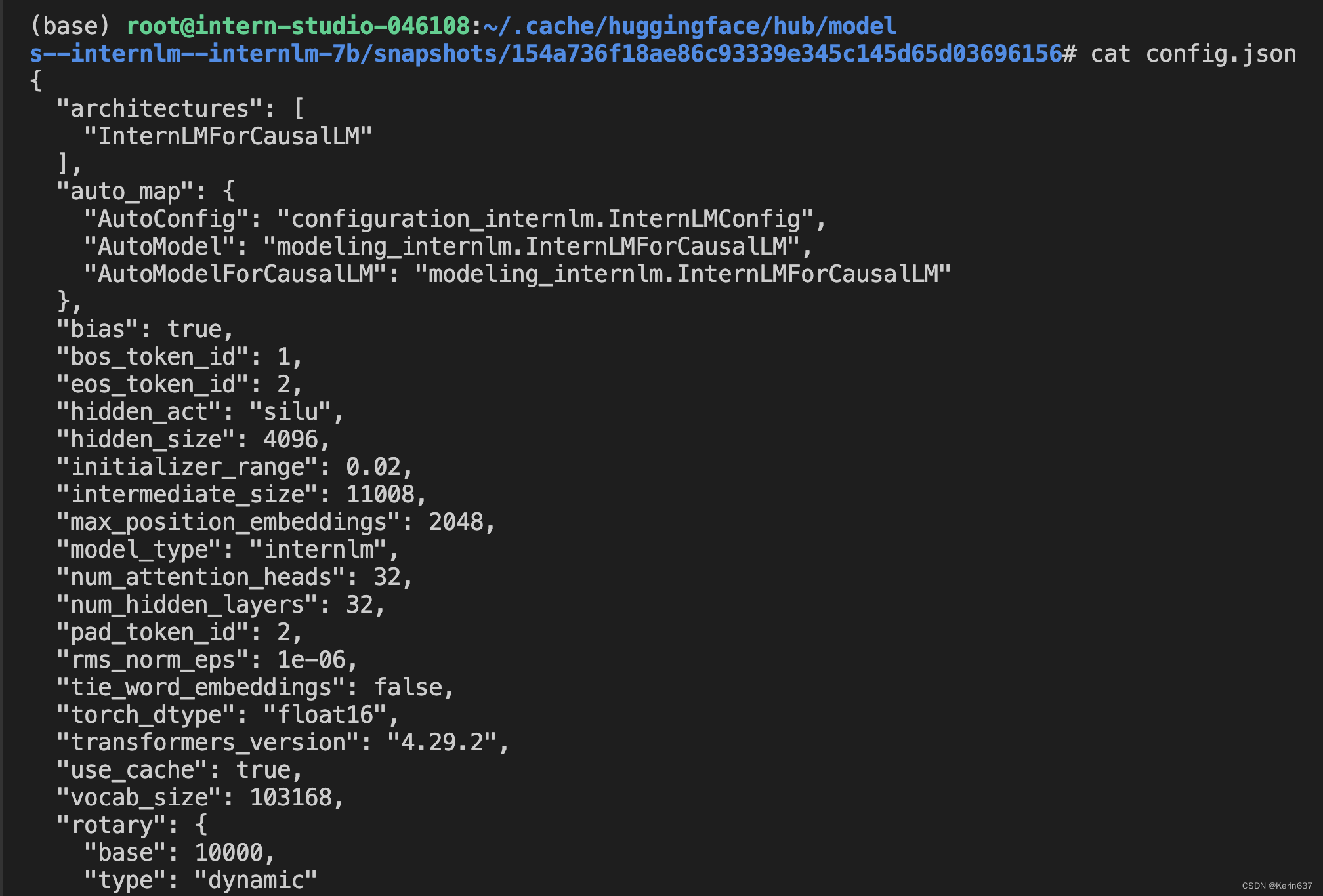
第二节:轻松玩转书生·浦语大模型趣味Demo
参考教程:https://github.com/InternLM/tutorial/blob/main/helloworld/hello_world.md
InternLM-Chat-7B 智能对话 Demo
终端运行 web demo 运行
1.首先启动服务:
cd /root/code/InternLM
streamlit run web_demo.py --server.address 127.0.0.1 --…
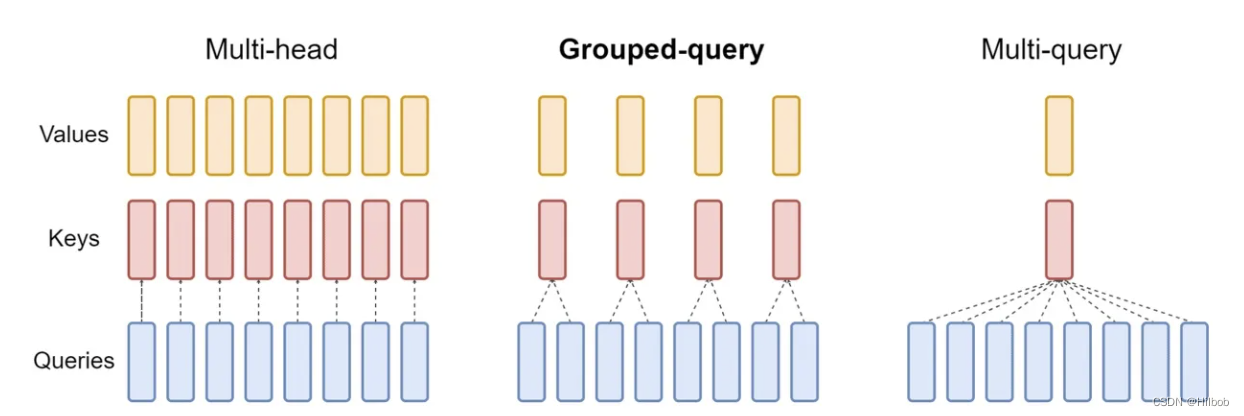
【NLP】MHA、MQA、GQA机制的区别
Note
LLama2的注意力机制使用了GQA。三种机制的图如下:
MHA机制(Multi-head Attention)
MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 V…

七天入门大模型 :大模型自动评估理论和实战
文章目录 背景技术交流群LLM评估的方法论1.2.1 模型效果评估1.2.2 模型性能评估 LLM评估实战 背景
大语言模型(LLM)评测是LLM开发和应用中的关键环节。目前评测方法可以分为人工评测和自动评测,其中,自动评测技术相比人工评测来讲…

深入浅出熟悉OpenAI最新大作Sora文生视频大模型
蠢蠢欲动,惴惴不安,朋友们我又来了,这个春节真的过的是像过山车,Gemini1.5 PRO还没过劲,OpenAI又放大招,人类真的要认输了吗,让我忍不住想要再探究竟,到底是什么让文生视频发生了质的…

跟无神学AI之一文读尽Sora
openAI发布视频生成模型Sora,意味着人类距离AI模拟世界又近了一步,流浪地球2中数字人女儿也是对未来科技发展的一个缩影。
作为最具有代表性的大模型公司,openAI的任何一个产品都具有一定的价值,代表着AI的前沿发展方向。
博主今…

Microsoft Copilot 好像能把论文配图看明白了
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ Microsoft Copilot 好像能把论文配图看明白了,下面是两个案例。
请用学术风格详细描述您的研究论文中的这幅配图。在描述时,请尽可能准确地阐述图片的主要元素、颜色、形状、大…
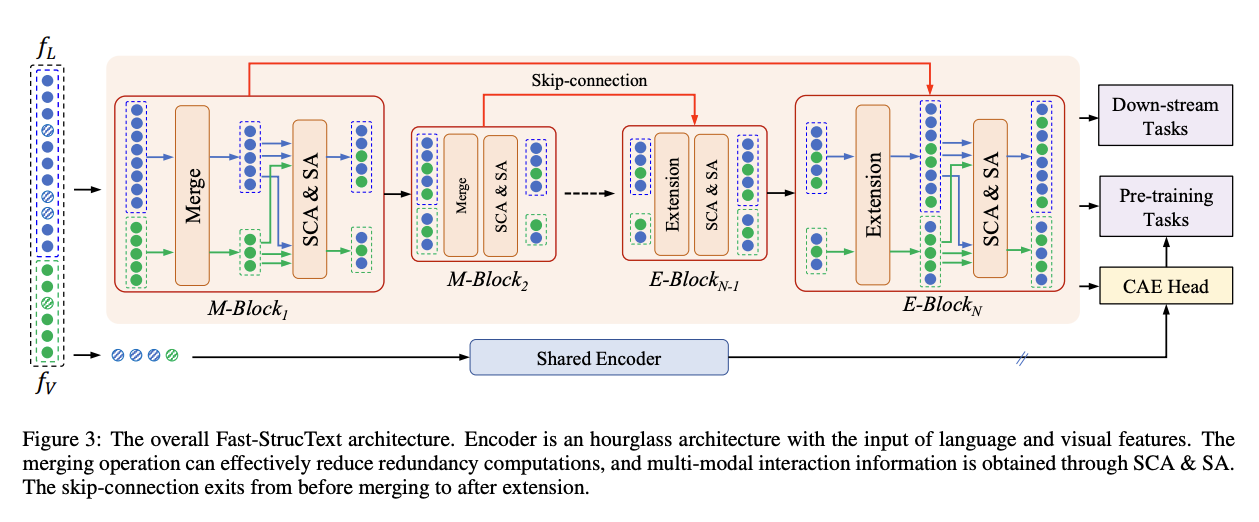
【文档智能】再谈基于Transformer架构的文档智能理解方法论和相关数据集
前言
文档的智能解析与理解成为为知识管理的关键环节。特别是在处理扫描文档时,如何有效地理解和提取表单信息,成为了一个具有挑战性的问题。扫描文档的复杂性,包括其结构的多样性、非文本元素的融合以及手写与印刷内容的混合,都…

文献阅读:Mistral 7B
文献阅读:Mistral 7B 1. 文章简介2. 模型结构说明 1. SWA (Sliding Window Attention)2. Rolling Buffer Cache3. Pre-fill and Chunking 3. 实验考察 & 结论 1. 基础实验2. Instruction Tuning3. 安全性分析 4. 总结 & 思考 文献链接:https://…
如何用GPT高效地处理文本、文献查阅、PPT编辑、编程、绘图和论文写作?
原文链接:如何用GPT高效地处理文本、文献查阅、PPT编辑、编程、绘图和论文写作?https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247594986&idx4&sn970f9ba75998f2dd9fa5707d1611a6cc&chksmfa82320dcdf5bb1bdf58c20686d4eb209770e68253ed90d…
![[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--强化学习等](https://img-blog.csdnimg.cn/direct/9ff77f6538a2423e95085feefea5b82c.jpeg#pic_center)
[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--强化学习等
专属领域论文订阅 关注{晓理紫|小李子},每日更新论文,如感兴趣,请转发给有需要的同学,谢谢支持 如果你感觉对你有所帮助,请关注我,每日准时为你推送最新论文。 分类: 大语言模型LLM视觉模型VLM扩散模型视觉…

Gemma谷歌(google)开源大模型微调实战(fintune gemma-2b)
Gemma-SFT
Gemma-SFT(谷歌, Google), gemma-2b/gemma-7b微调(transformers)/LORA(peft)/推理
项目地址
https://github.com/yongzhuo/gemma-sft全部weights要用fp32/tf32, 使用fp16微调十几或几十的步数后大概率lossnan;(即便layer-norm是fp32也不行, LLaMA就没有这个问题, …
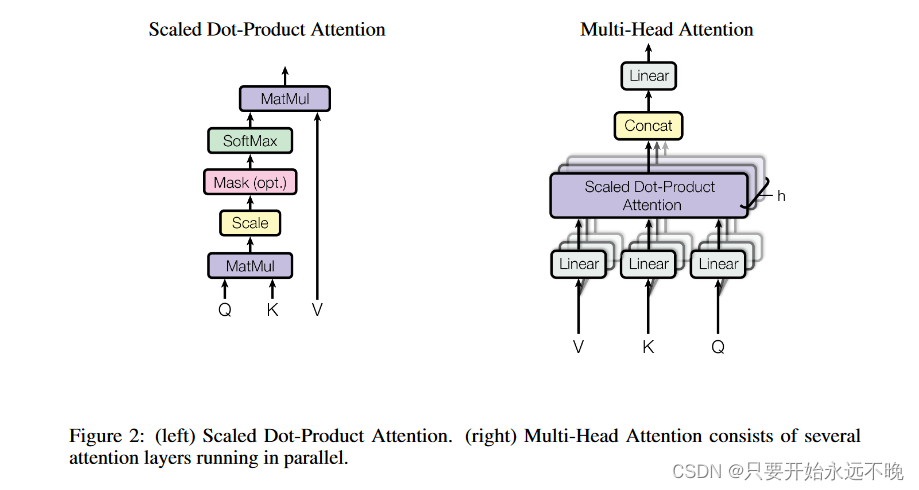
大模型基础之注意力机制和Transformer
【注意力机制】
核心思想:在decoder的每一步,把encoder端所有的向量提供给decoder,这样decoder根据当前自身状态,来自动选择需要使用的向量和信息.
【注意力带来的可解释性】
decoder在每次生成时可以关注到encoder端所有位置的…

Prompt进阶3:LangGPT(构建高性能质量Prompt策略和技巧2)--稳定高质量文案生成器
Prompt进阶3:LangGPT(构建高性能质量Prompt策略和技巧2)–稳定高质量文案生成器
1.LangGPT介绍
现有 Prompt 创建方法有如下缺点:
缺乏系统性:大多是细碎的规则,技巧,严重依赖个人经验缺乏灵活性:对他人分享的优质 …

【他山之石】BlueLM蓝心大模型的落地
note
预训练:我们采用了混合精度训练以及梯度缩放策略,因为这可以减少训练周期,训练周期较少会节省模型训练所需的时间和资源。选择回放训练能够让模型定向学会一类知识信息。Loss 预测确保在训练过程前对损失进行估计,以保证训练…
Prompt进阶2:LangGPT(构建高性能Prompt策略和技巧)--最佳实践指南
Prompt进阶2:LangGPT(构建高性能Prompt策略和技巧)–最佳实践指南
0.前言 左图右图 prompt 基本是一样的,差别只在提示工程这个词是否用中英文表达。我们看到,一词之差,回答质量天壤之别。为了获得理想的模型结果,我们需要调整设…

全网公开的大模型评测数据集整理
全网公开的大模型评测数据集整理。 开源大模型评测排行榜
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
其数据是由其后端lm-evaluation-harness平台提供。
数据集 英文测试 MMLU https://paperswithcode.com/dataset/mmlu
MMLU(大规模多…

谷歌AI发展史:从阿尔法围棋到Gemini与Gemma的开源创新
谷歌一直是人工智能领域的重要推动者。本文将回顾谷歌AI的发展历程,从阿尔法围棋到现如今的Gemini和Gemma,探讨谷歌在人工智能领域的重大突破和创新。 1. 引言 在计算机科学领域,谷歌一直是人工智能(AI࿰…

常见的开源人脸检测模型有哪些
阅读本文之前可以先参阅----神经网络中的重要概念
如何快速入门深度学习
人工智能模型与人脸检测模型详解 一、人工智能模型概述 人工智能(Artificial Intelligence, AI)模型,是指通过计算机算法和数学统计方法,模拟人类智能行为…

什么是大模型微调?微调的分类、方法、和步骤
2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据…
ubuntu22.04安装cuda11.5+cudnn8.8.0
因为pytorch1.11.0与cuda版本的关系 需要用到cuda11.5
否则报错
"addmm_sparse_cuda" not implemented for Half
cuda11.5.0及以前的版本不会出现这个问题
因此重新安装,步骤如下:
安装CUDA-11.5.0
wget https://developer.download.nvi…
书生·浦语大模型图文对话Demo搭建
前言
本节我们先来搭建几个Demo来感受一下书生浦语大模型
InternLM-Chat-7B 智能对话 Demo
我们将使用 InternStudio 中的 A100(1/4) 机器和 InternLM-Chat-7B 模型部署一个智能对话 Demo
环境准备
在 InternStudio 平台中选择 A100(1/4) 的配置,如下图所示镜像…
开源大模型LLM大爆发,数据竞赛已开启!如何使用FuseLLM实现大语言模型的知识融合?
开源大模型LLM大爆发,数据竞赛已开启!如何使用FuseLLM实现大语言模型的知识融合? 现在大多数人都知道LLM是什么,以及可以做什么。
人们讨论着它的优缺点,畅想着它的未来,
向往着真正的AGI,又有…
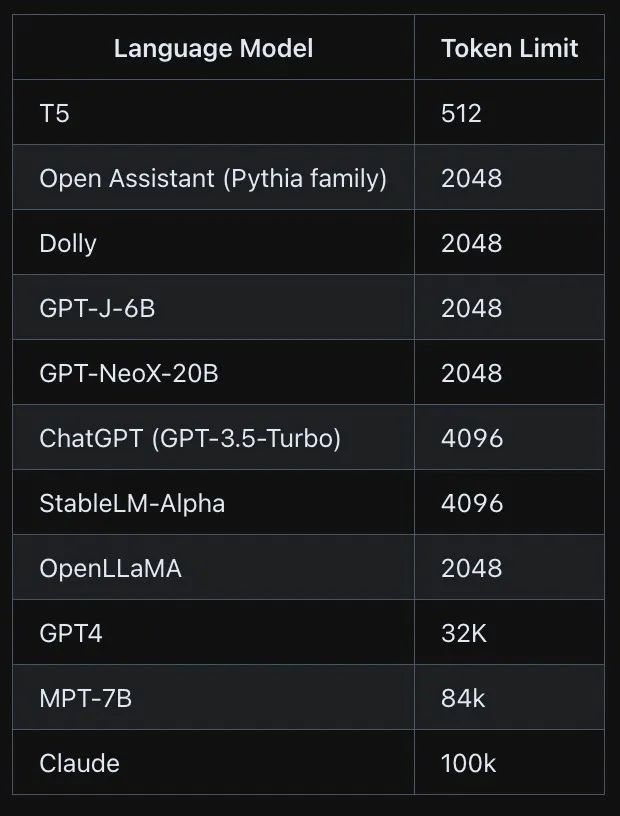
大模型(LLM)的token学习记录-I
文章目录 基本概念什么是token?如何理解token的长度?使用openai tokenizer 观察token的相关信息open ai的模型 token的特点token如何映射到数值?token级操作:精确地操作文本token 设计的局限性 tokenizationtoken 数量对LLM 的影响训练模型参…
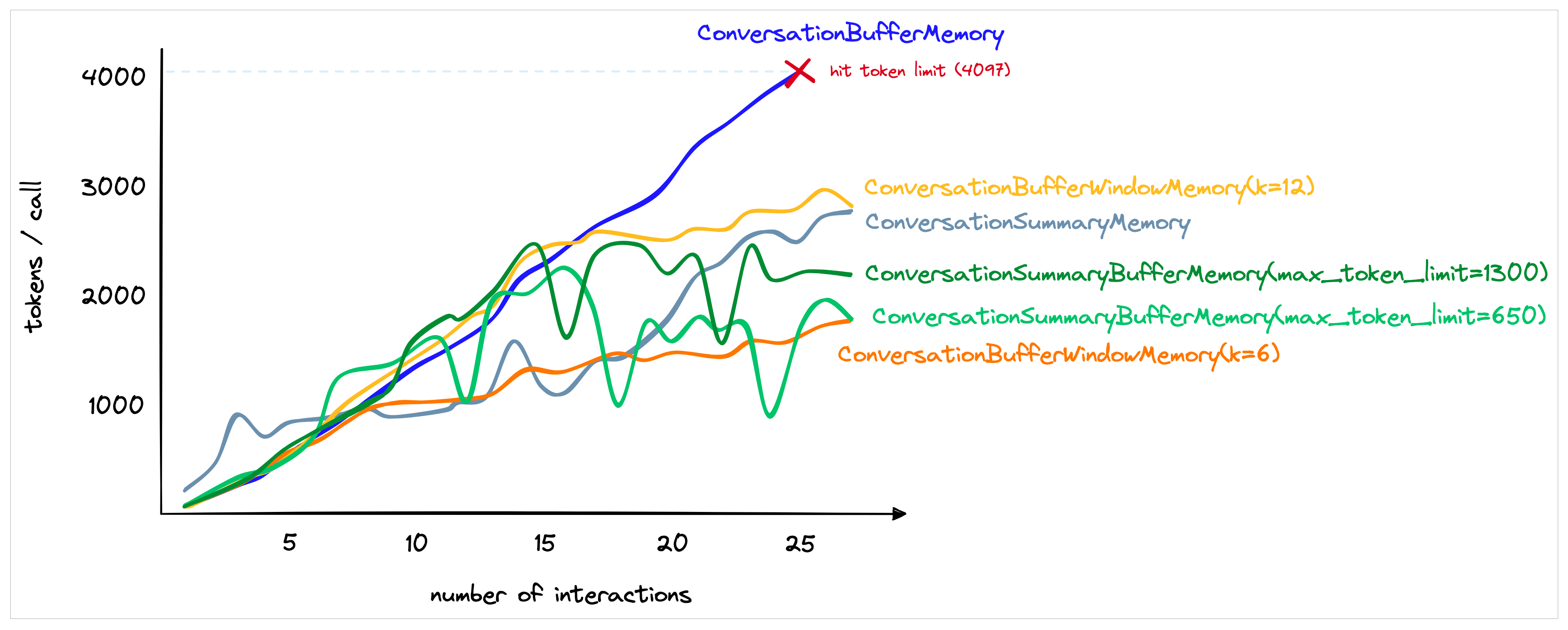
【LangChain学习之旅】—(11) 记忆:通过Memory记住用户上次的对话细节
【LangChain学习之旅】—(11) 记忆:通过Memory记住客户上次买花时的对话细节 使用 ConversationChain使用 ConversationBufferMemory使用 ConversationBufferWindowMemory使用 ConversationSummaryMemory使用 ConversationSummaryBufferMemor…
我常用的大模型和Prompt有哪些?
常用的大模型及其对比
以前提到过,我们公司鼓励大家多使用GPT这样的大模型,一方面能够提高工作效率,一方面使用的越多,越了解,越有可能发现应该怎么将其跟我们公司的产品结合起来。
但是出于安全考虑,如果…
基于OpenCompass的大模型评测实践
大模型评测教程
随着人工智能技术的快速发展, 大规模预训练自然语言模型成为了研究热点和关注焦点。OpenAI于2018年提出了第一代GPT模型,开辟了自然语言模型生成式预训练的路线。沿着这条路线,随后又陆续发布了GPT-2和GPT-3模型。与此同时&a…
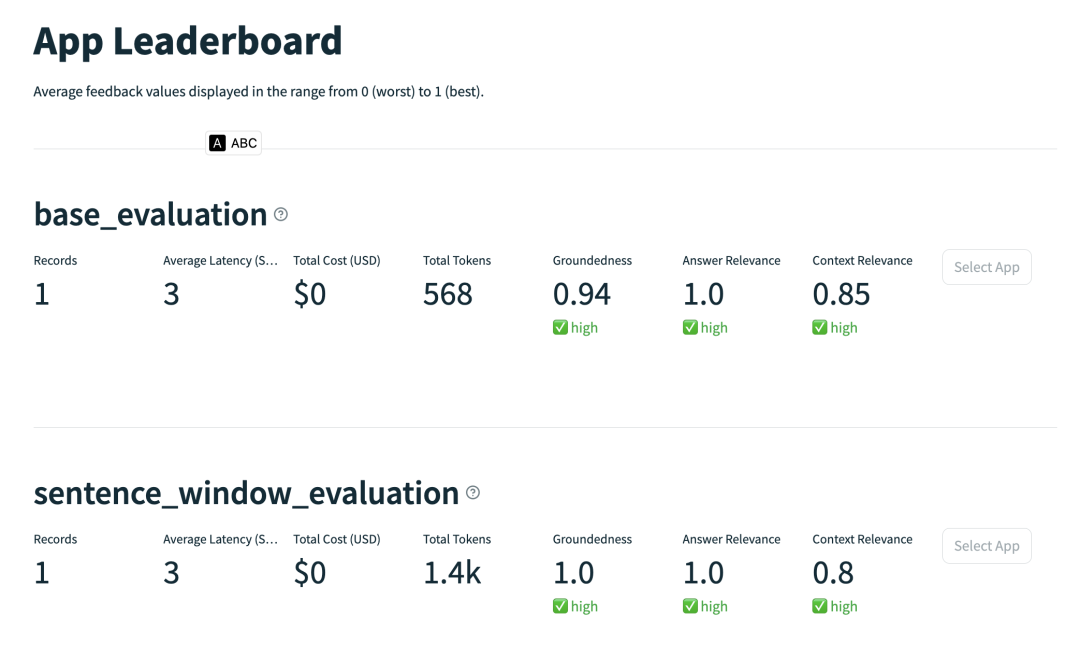
大模型高级 RAG 检索策略之句子窗口检索
之前介绍过大语言模型(LLM)相关技术 RAG(Retrieval Augmented Generation)的内容,但随着 LLM 技术的发展,越来越多的高级 RAG 检索方法也随之被人发现,相对于普通的 RAG 检索,高级 R…
大模型的实践应用19-基于pytorch框架下LayoutLM模型的搭建以及原理介绍
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用19-基于pytorch框架下LayoutLM模型的搭建以及原理介绍。LayoutLM是一个基于 Transformer 的预训练模型,它专门为处理布局丰富的文档信息而设计,例如扫描的文档、PDF 文件等。这个模型由微软亚洲研究院的研究团队开发,…
解决离线运行vLLM 启动报dns.google错
现象
vLLM版本0.3.3离线运行时,报类似下面形式的错误:
File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/llm.py", line 109, in init self.llm_engine LLMEngine.from_engine_args(engine_args) File "/usr/local/li…
CPU服务器安装运行智谱大模型ChatGLM-6B
CPU运行智谱大模型ChatGLM-6B
说明
我的服务器配置是16C32G,跑大模型最好内存要大一些才行,不然跑不起来。
下载
git clone https://github.com/THUDM/ChatGLM-6B.git
安装依赖包
pip install -r requirements.txt
下载模型文件
在huggingface上…
ollama 本地部署大模型
在当今的科技时代,AI 已经成为许多领域的关键技术。AI 的应用范围广泛,从自动驾驶汽车到语音助手,再到智能家居系统,都有着 AI 的身影,而随着Facebook 开源 LLama2 更让越来越多的人接触到了开源大模型。
今天我们推荐的是一条命令快速在本地运行大模型,在GitHub超过22K…

基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
Reinforcement Learning from Human Feedback
基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
课程地址:https://www.deeplearning.ai/short-courses/reinforcement-learning-from-human-feedback/
Topic:
Get a conceptual understanding of Reinforcemen…

GPT实战系列-智谱GLM-4的模型调用
GPT实战系列-智谱GLM-4的模型调用
GPT专栏文章:
GPT实战系列-实战Qwen通义千问在Cuda 1224G部署方案_通义千问 ptuning-CSDN博客
GPT实战系列-ChatGLM3本地部署CUDA111080Ti显卡24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
GPT实战系列-让CodeGeeX2帮…
小米 AIGC 大模型实习面试题4道|含解析
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂同学、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这…
2024淘天阿里妈妈算法工程师一面&二面 面试题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
今天我们…

Python 自己训练chatGPT,实例代码如下;简单易懂的训练chatGPT,模板实例;自己训练chatGPT
代码实例:
比较简单的示例,其它gpt架构相关知识和代码移步专栏其它文章。
from torchtext.datasets import WikiText2 # 导入WikiText2
from torchtext.data.utils import get_tokenizer # 导入Tokenizer分词工具
from torchtext.vocab import build_…
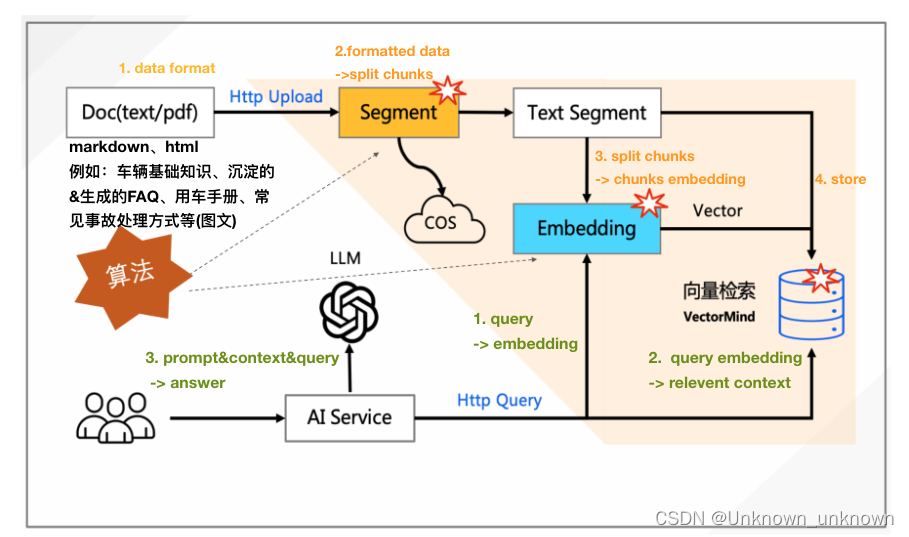
基于RAG的大模型知识库搭建
什么是RAG
RAG(Retrieval Augmented Generation),即检索增强生成技术。
RAG优势
部分解决了幻觉问题。由于我们可以控制检索内容的可靠性,也算是部分解决了幻觉问题。可以更实时。同理,可以控制输入给大模型上下文内容的时效性,…

ChatGPT 结合实际地图实现问答式地图检索功能基于Function calling
ChatGPT 结合实际地图实现问答式地图检索功能基于Function calling
ChatGPT结合实际业务,主要是研发多函数调用(Function Calling)功能模块,将自定义函数通过ChatGPT 问答结果,实现对应函数执行,再次将结果…

智引未来:2024年科技革新引领工业界变革与机遇
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…

大模型多模态Chatgpt+自动驾驶控制器设计方案
/导读/
最近的科技圈,大家都被微软推出的ChatGPT刷屏,作为工智能公司OpenAI于2022年11月推出的聊天机器人,其能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,甚至能完成撰写邮件、视频脚本、文…
Prompt 共享网站
好用的提示词网站链接:
PromptBase | Prompt Marketplace: Midjourney, ChatGPT, DALLE, Stable Diffusion & more.Search 100,000 quality AI prompts from top prompt engineers. Produce better outputs, save on time & API costs, sell your own prom…
极智芯 | 解读近存计算AI芯势力Groq LPU
欢迎关注我的公众号「极智视界」,获取我的更多技术分享
大家好,我是极智视界,本文分享一下 解读近存计算AI芯势力Groq LPU。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 当然,标题用了 "一语…
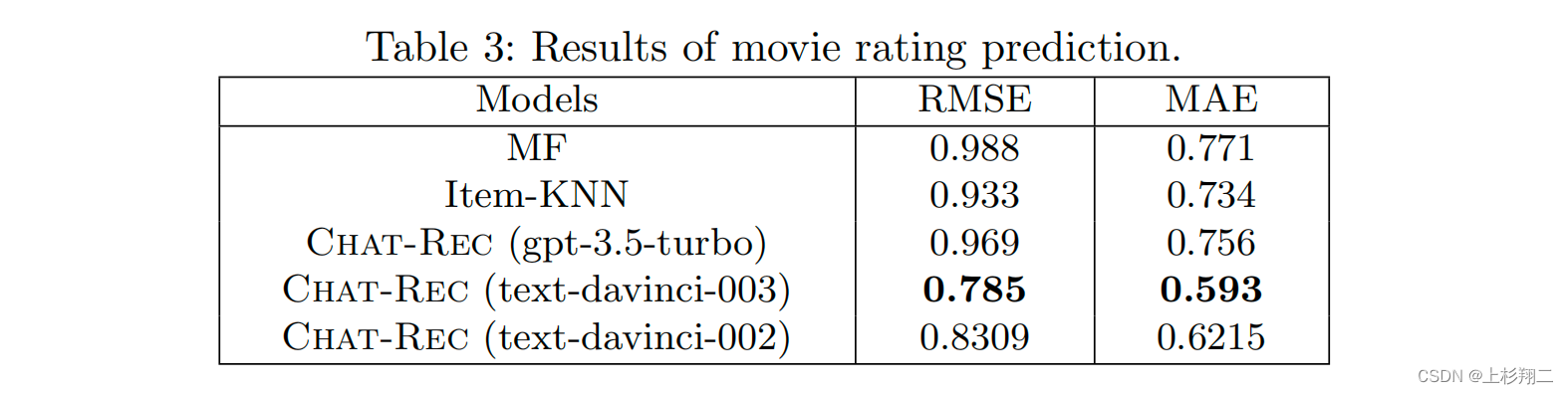
Chat-REC(LLM大模型用于推荐系统)
当众多chat-xxx和xxxGPT喷涌而出的时候,博主就在等它被做到推荐系统的这一天。本篇博文将简要看看一些文章的具体做法。
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System 先上地址,
https://arxiv.org/abs/2303.145…
Prompt Engineering | 推断prompt(一句prompt解锁多个nlp任务)
😄 大模型大一统的时代来临了,各nlp任务不需要单独准备一份带标签的数据进行有监督训练,而是只需要一句prompt便可以解决各类nlp任务,如情感分类、情感类型识别、实体抽取等,极大地减轻了工作量!
⭐ 比如&…
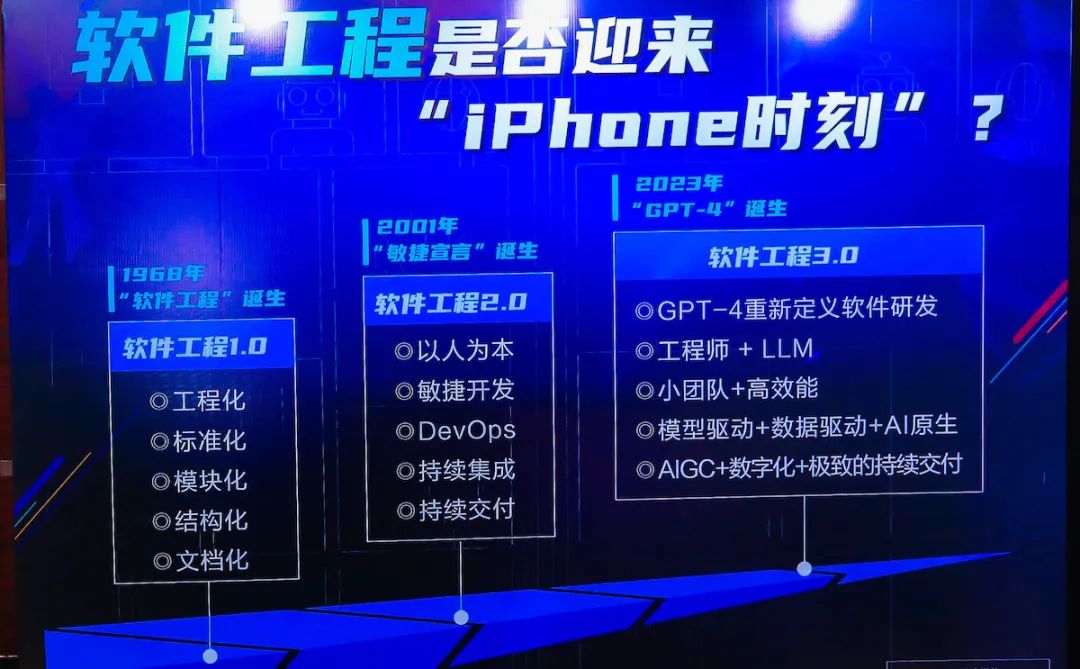
软件工程是否迎来iPhone时刻?
“软件工程是否迎来iPhone时刻?” 是2023K全球软件研发行业创新峰会上海站主会场的Panel discussion的主题,出场的几位嘉宾给出了不同的答案,其中有两位嘉宾给出了“No”,一位给出了“塞班时刻”(后来给我朋友圈投票是…
2023年6月第3周大模型荟萃
2023年6月第3周大模型荟萃
2023.6.20版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、Meta 开源 AI 语言模型 MusicGen
6月12日讯,Meta 近日在 Github 上开源了其 AI 语言模型 MusicGen,该模型基于 Transformer…
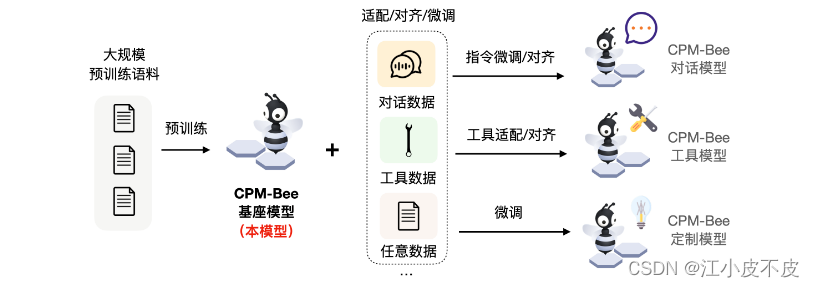
CPM-Bee大模型微调
CPM-Bee大模型微调 CPM-Bee简介:环境配置:应用场景:模型训练参数训练命令:推理:评估:结论: CPM-Bee 简介:
CPM-Bee是一个完全开源、允许商用的百亿参数中英文基座模型,也…
大模型时代商业终局沉思
最近整个IT圈子被大模型浪潮席卷,身边的朋友们纷纷都加入到这场混战,看似是技术变革的竞争,本质上是对AI加持下新的商业模式的探索。有点像我最开始做点事情的时候,当时正值移动互联网兴起,各种公司或者创业团体都在探…
FastAPI 构建 API 高性能的 web 框架(二)
上一篇 FastAPI 构建 API 高性能的 web 框架(一)是把LLM模型使用Fastapi的一些例子,本篇简单来看一下FastAPI的一些细节。 有中文官方文档:fastapi中文文档
假如你想将应用程序部署到生产环境,你可能要执行以下操作&a…

星星之火:国产讯飞星火大模型的实际使用体验(与GPT对比)
#AIGC技术内容创作征文|全网寻找AI创作者,快来释放你的创作潜能吧!# 文章目录 1 前言2 测试详情2.1 文案写作2.2 知识写作2.3 阅读理解2.4 语意测试(重点关注)2.5 常识性测试(重点关注)2.6 代码…

孤注一掷——基于文心Ernie-3.0大模型的影评情感分析
孤注一掷——基于文心Ernie-3.0大模型的影评情感分析 文章目录 孤注一掷——基于文心Ernie-3.0大模型的影评情感分析写在前面一、数据直观可视化1.1 各评价所占人数1.2 词云可视化 二、数据处理2.1 清洗数据2.2 划分数据集2.3 加载数据2.4 展示数据 三、RNIE 3.0文心大模型3.1 …

文心一言向全社会开放
大家好,我是洋子
今天和大家宣传一件令人激动的事情
8月31日,文心一言率先向全社会全面开放。广大用户可以在应用商店下载“文心一言APP”或登陆“文心一言官网(https://yiyan.baidu.com)体验。同时,企业用户可以直接登陆百度智能云千帆大模…
python基础操作笔记
一,pickle读写json格式文件pkl
k
Out[15]: {k1: 2, k3: 4}with open("test822.pkl","wb") as f:pickle.dump(k,f,) with open("test822.pkl","rb") as f:kk=pickle.load(f)kk==k
Out[20]: True
二、docker删除image
docker rmi …
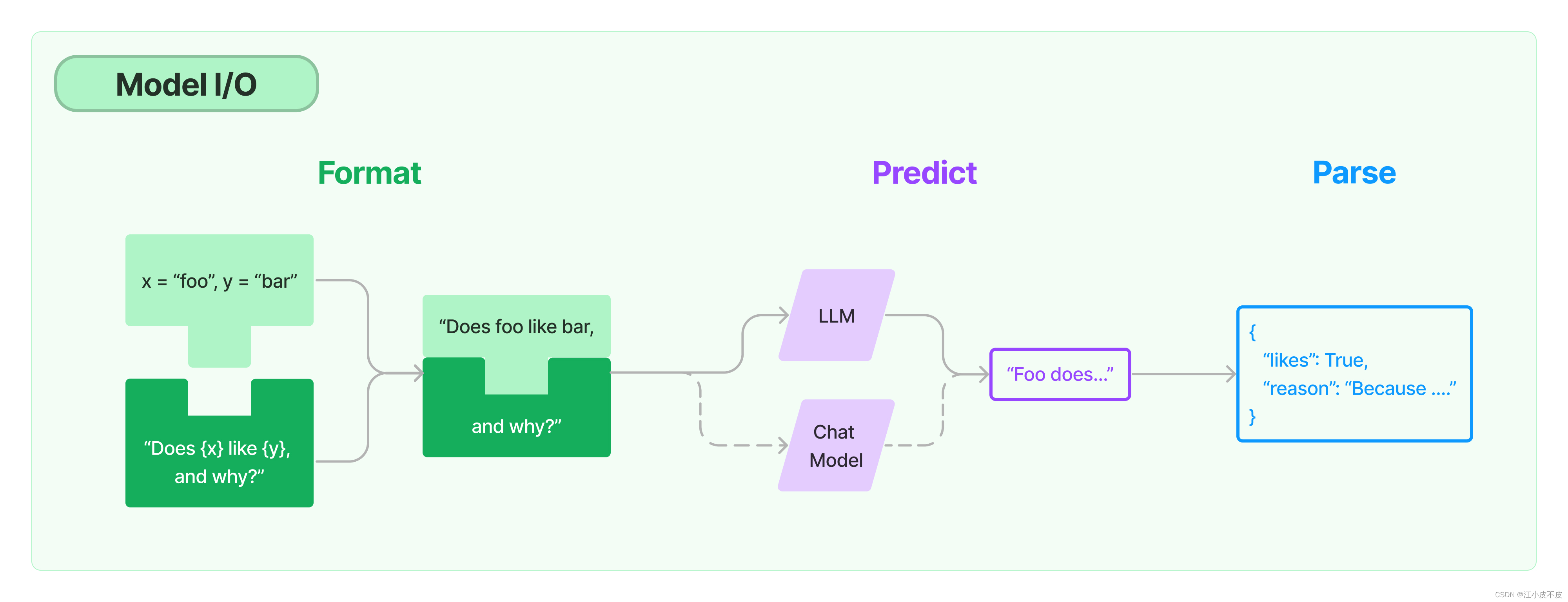
langchain主要模块(一):模型输入输出
langchain2之模型输入输出 langchain1.概念2.主要模块模型输入/输出 (Model I/O)数据连接 (Data connection)链式组装 (Chains)代理 (Agents)内存 (Memory)回调 (Callbacks) 3.模型输入/输出 (Model I/O)提示提示模板示例选择器 模型LLMsChatModels 输出解释器 langchain
1.概…
大模型从入门到应用——LangChain:回调函数(Callbacks)]
分类目录:《大模型从入门到应用》总目录 LangChain提供了一个回调函数系统,允许我们在LLM应用的各个阶段进行钩子处理。这对于日志记录、监控、流处理和其他任务非常有用。我们可以通过使用API中提供的callbacks参数来订阅这些事件。该参数是一个处理程序…
大模型对外提供应用的三种服务方式及示例
最近在研究Llama大模型的本地化部署和应用测试过程中,为了给大家提供更多的应用方式,研究了如何利用python快速搭建各种应用访问服务,一般来说,我们开发完成的软件模块为了体现价值,都需要对外提供服务,最原…
论文精读ResNet: Deep Residual Learning for Image Recognition
1 基础背景
论文链接:https://arxiv.org/abs/1512.03385 Github链接:https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py 知乎讲解:ResNet论文笔记及代码剖析
2 Motivation
对于深度神经网络来说,深…

从技术创新到应用实践,百度智能云发起大模型平台应用开发挑战赛!
大模型已经成为未来技术发展方向的重大变革,热度之下更需去虚向实,让技术走进产业场景。在这样的背景下,百度智能云于近期发起了“百度智能云千帆大模型平台应用开发挑战赛”。 挖掘大模型落地应用 千帆大模型平台应用开发挑战赛启动 在不久前…
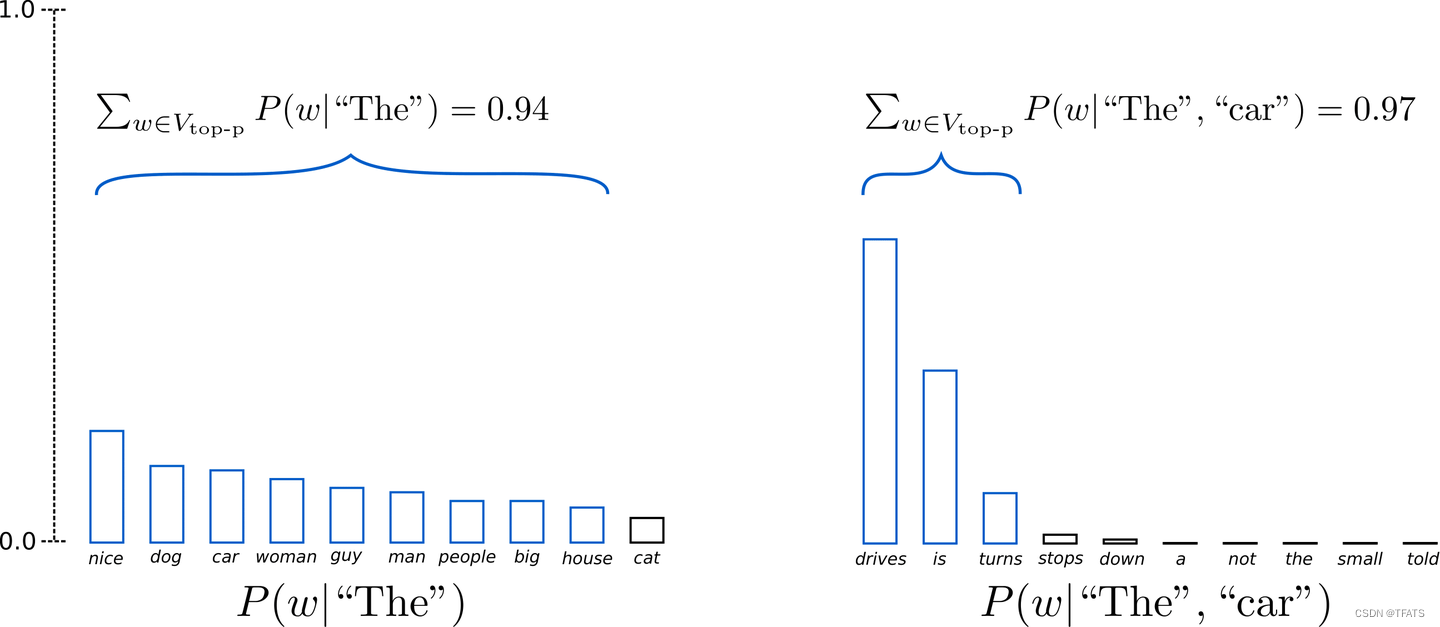
大模型 Decoder 的生成策略
本文将介绍以下内容:
IntroductionGreedy Searchbeam searchSamplingTop-K SamplingTop-p (nucleus) sampling总结
一、Introduction
1、简介
近年来,由于在数百万个网页数据上训练的大型基于 Transformer 的语言模型的兴起,开放式语言生…
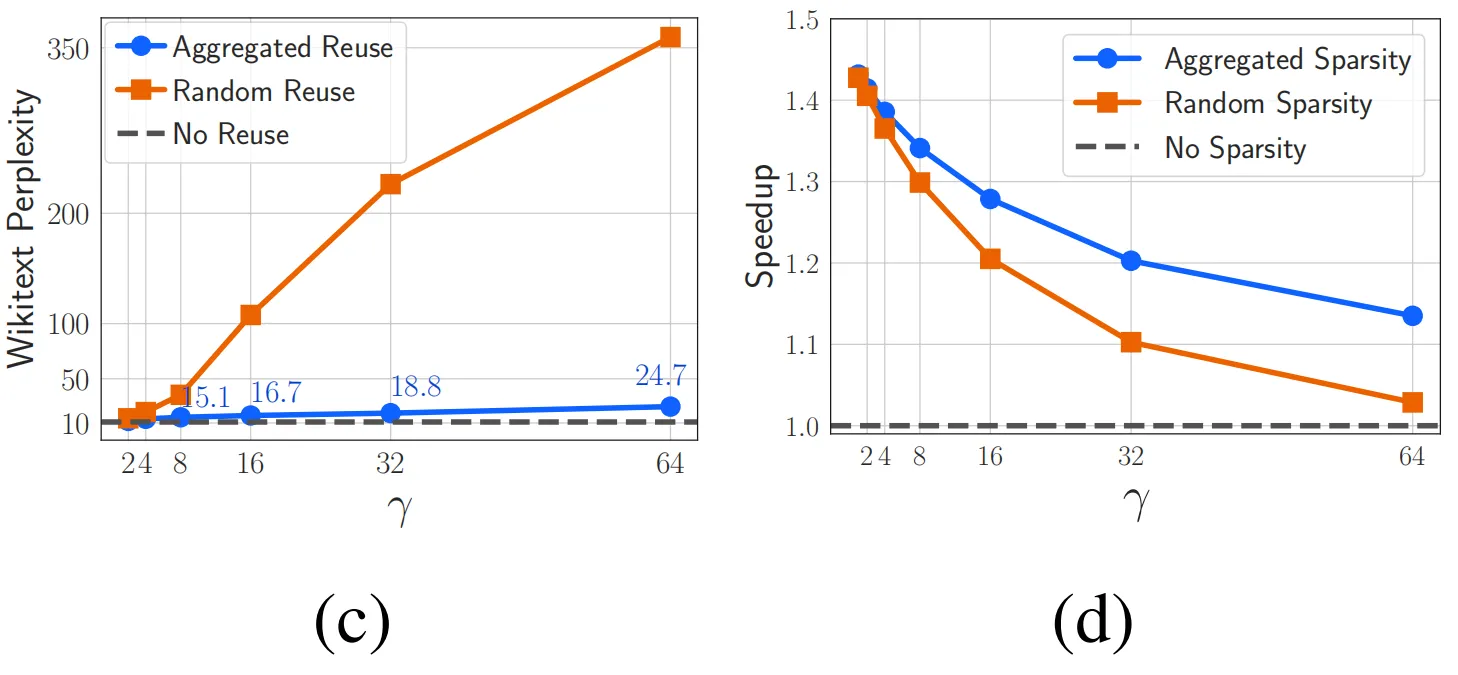
ICLR 2024|ReLU激活函数的反击,稀疏性仍然是提升LLM效率的利器
论文题目: ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models 论文链接: https://arxiv.org/abs/2310.04564 参数规模超过十亿(1B)的大型语言模型(LLM)已经彻底改变了现阶段人工…

大模型之SORA技术学习
文章目录 sora的技术原理文字生成视频过程sora的技术优势量大质优的视频预训练库算力多,采样步骤多,更精细。GPT解释力更强,提示词(Prompt)表现更好 使用场景参考 Sora改变AI认知方式,开启走向【世界模拟器】的史诗级的…

【RAG实践】基于 LlamaIndex 和Qwen1.5搭建基于本地知识库的问答机器人
什么是RAG
LLM会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
正是在这样的背景下,检索增强生成技术(Retrieval-Augmented G…
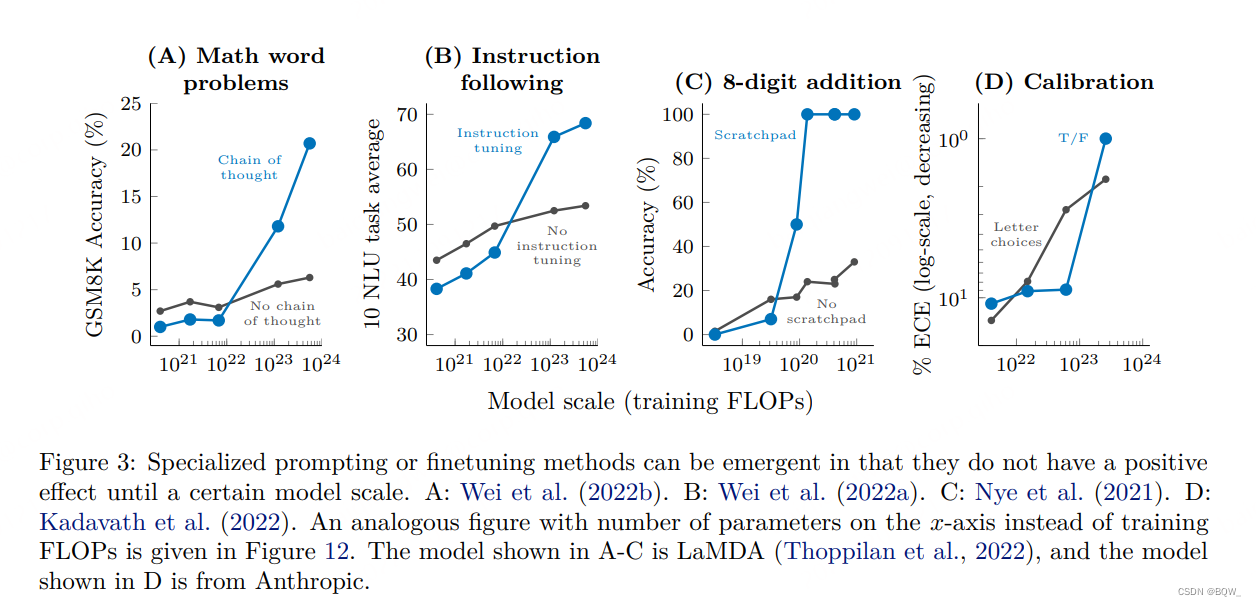
【自然语言处理】【ChatGPT系列】大模型的涌现能力
大语言模型的涌现能力《Emergent Abilities of Large Language Models》论文地址:https://arxiv.org/pdf/2206.07682.pdf 相关博客 【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里? 【自然语言处理】【ChatGPT系列】Chain of Thought:…
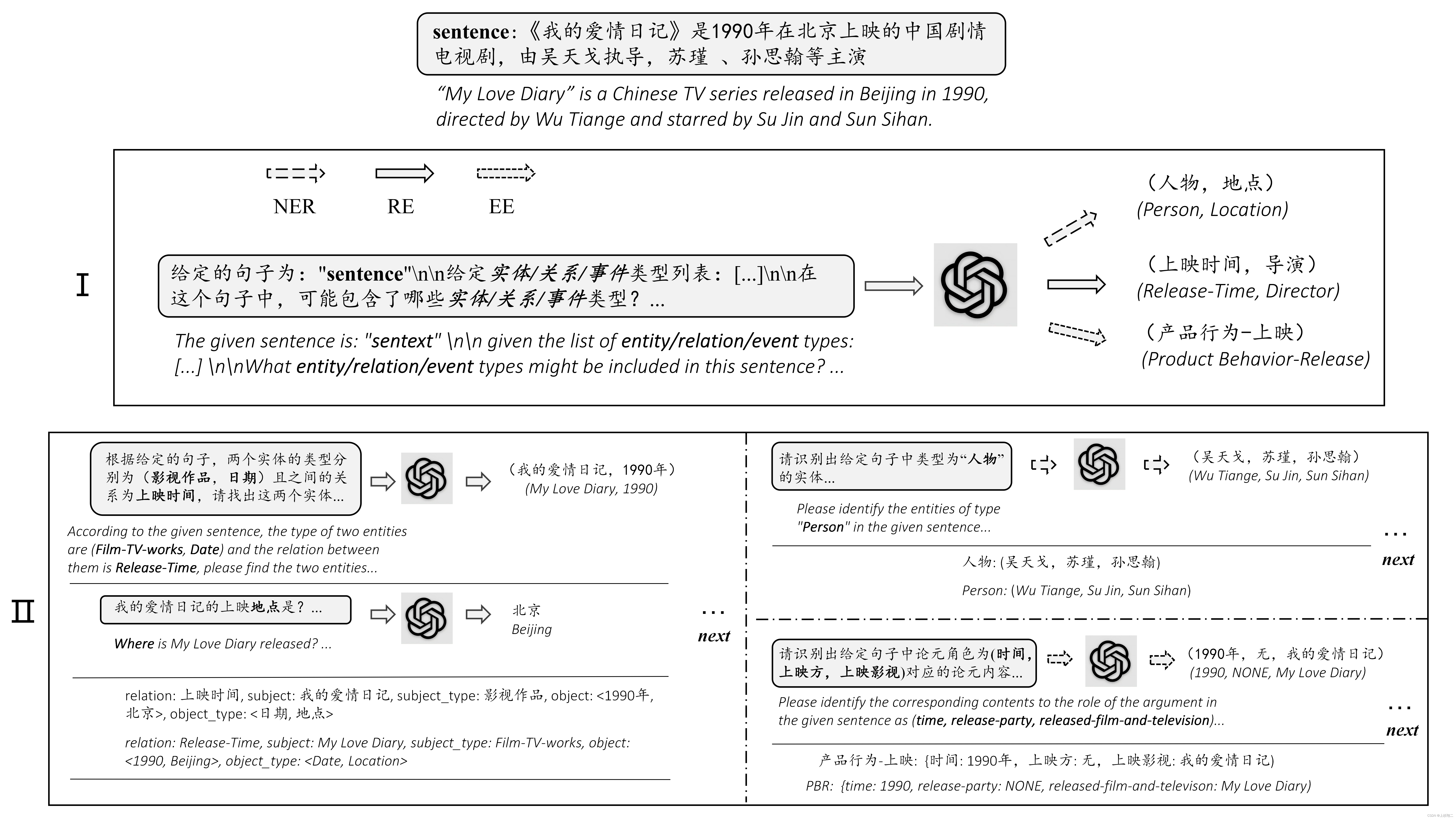
ChatIE(LLM大模型用于信息抽取)
Zero-Shot Information Extraction via Chatting with ChatGPT
paper:https://arxiv.org/abs/2302.10205
利用ChatGPT实现零样本信息抽取(Information Extraction,IE),看到零样本就能大概明白这篇文章将以ChatGPT作为…
Prompt提示词工程构建指南
在大模型中获取高质量的内容,关键是学会有效地沟通和布置任务。就像人际交流中使用的金字塔原理和结构化思维一样,这些技巧在与大模型交流时也非常有效。通过掌握这些技巧就可以轻松构建出高质量的提示(prompt),而不需…

又壕又实惠的 AI 训练来了,Hugging Face 第一的 LLM 大模型 Falcon 40B 纳入亚马逊云科技服务
出品 | CSDN 云计算 2023 年,几乎是 AI 爆炸式发展的一年。各类大模型接踵而至,全行业都将 AIGC 融入生产流程,以提升效率。最近,阿联酋首都阿布扎比的科研中心 TII(Technology Innovation Institute)拥有 …

【大模型系列】图文对齐(CLIP/TinyCLIP/GLIP)
文章目录 1 CLIP(ICML2021,OpenAI)1.1 预训练阶段1.2 推理阶段1.3 CLIP的下游应用1.3.1 ViLD:zero-shot目标检测(2022, Google)1.3.2 图像检索Image Retrival1.3.3 HairCLIP:图像编辑Image Editing(2022,中科大) 2 TinyCLIP(2023,…

【AI实战】开源可商用的中英文大语言模型baichuan-7B,从零开始搭建
【AI实战】开源可商用的中英文大语言模型baichuan-7B,从零开始搭建 baichuan-7B 简介baichuan-7B 中文评测baichuan-7B 搭建参考 baichuan-7B 简介
baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约…

免费试用PK市面上所有知名大模型 openai,微软azure, 百度文心,讯飞星火,阿里通义千问,腾讯混元,清华智谱
市面上的大模型层出不穷,每个都得单独注册非常麻烦,今天小编给大家提供一个一站式解决方案,登录我们网站pc端,所有大模型一网打尽。
www.promptspower.comhttp://www.promptspower.com 也可用电脑微信访问公众号菜单登录
目前已…

大模型冷思考:企业“可控”价值创造空间还有多少?
文 | 智能相对论
作者 | 叶远风
毫无疑问,大模型热潮正一浪高过一浪。
在发展进程上,从最开始的技术比拼到现在已开始全面强调商业价值变现,百度、科大讯飞等厂商都喊出类似“不能落地的大模型没有意义”等口号。
在模型类型上࿰…

LLM相关的一些调研
Prompt Engine
可以参考该项目,该项目提供关于提示词书写的规则。由openai以及吴恩达完成。 https://github.com/datawhalechina/prompt-engineering-for-developers由于目前chatgpt 无法直接在国内访问,推荐在claude on slack上尝试。关于claude api h…
ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Driv…

比ChatGPT更强的星火大模型V2版本发布!
初体验
测试PPT生成 结果: 达到了我的预期,只需要微调就可以直接交付,这点比ChatGPT要强很多.
测试文档问答 结果: 这点很新颖,现在类似这种文档问答的AI平台收费都贵的离谱,星火不但免费支持而且效果也…
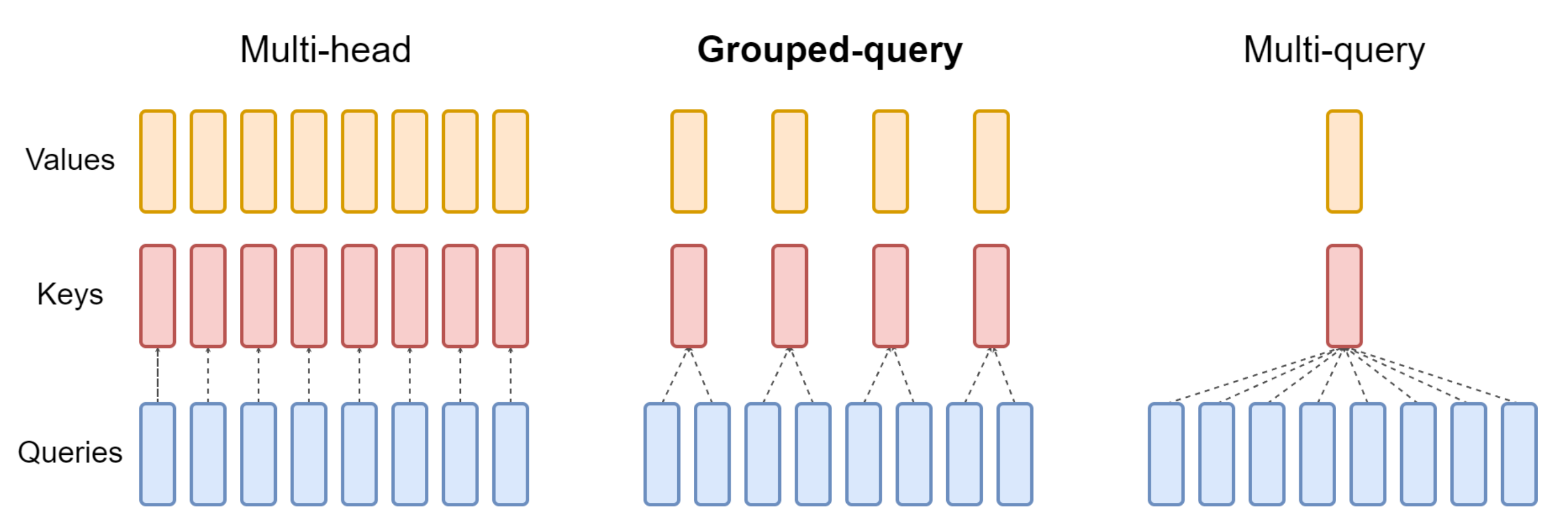
一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA
第一部分 多头注意力
// 待更 第二部分 LLaMA2之分组查询注意力——Grouped-Query Attention
自回归解码的标准做法是缓存序列中先前标记的键 (K) 和值 (V) 对,从而加快注意力计算速度 然而,随着上下文窗口或批量大小的增加,多头注意力 (MH…
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
目录
一、ChatGLM3 模型
二、资源需求
三、部署安装
配置环境
安装过程
低成本配置部署方案
四、启动 ChatGLM3
五、功能测试 新鲜出炉,国产 GPT 版本迭代更新啦~清华团队刚刚发布ChatGLM3,恰逢云栖大会前百川也发布Baichuan2-192K,一…

AI大模型低成本快速定制秘诀:RAG和向量数据库
文章目录 1. 前言2. RAG和向量数据库3. 论坛日程4. 购票方式 1. 前言 当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。 这种背景下,向量数据库凭借其独特…

DALL·E 2 文生图模型实践指南
前言:本篇博客记录使用dalle2模型进行推断时借鉴的相关资料和DEBUG流程。 相关博客:超详细!DALL E 文生图模型实践指南 目录 1. 环境搭建和预训练模型准备环境搭建预训练模型下载 2. 代码3. BUG&DEBUGURLErrorCUDA errorRuntimeErrorPyd…
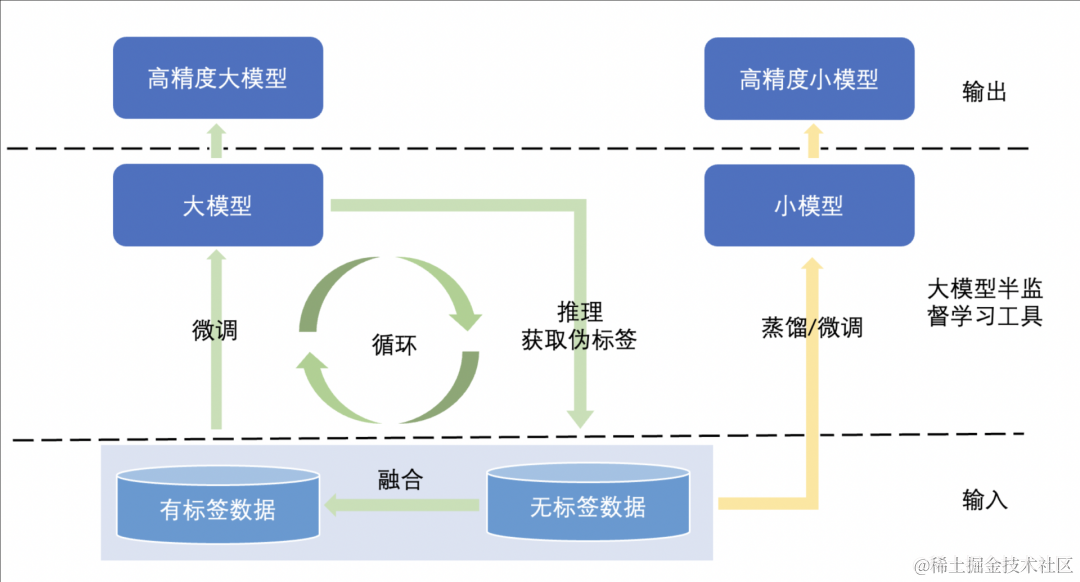
提效神器!10%标注数据,比肩全量标注的模型效果!
不知道大家有没有遇到过数据标注成本高、周期长的困扰,有没有那么一种可能,精心标注少量的数据,配合大量的无标注数据,就能达到比肩全量标注的模型精度呢?是的,PaddleX就带来了这样一款提效神器——大模型半…
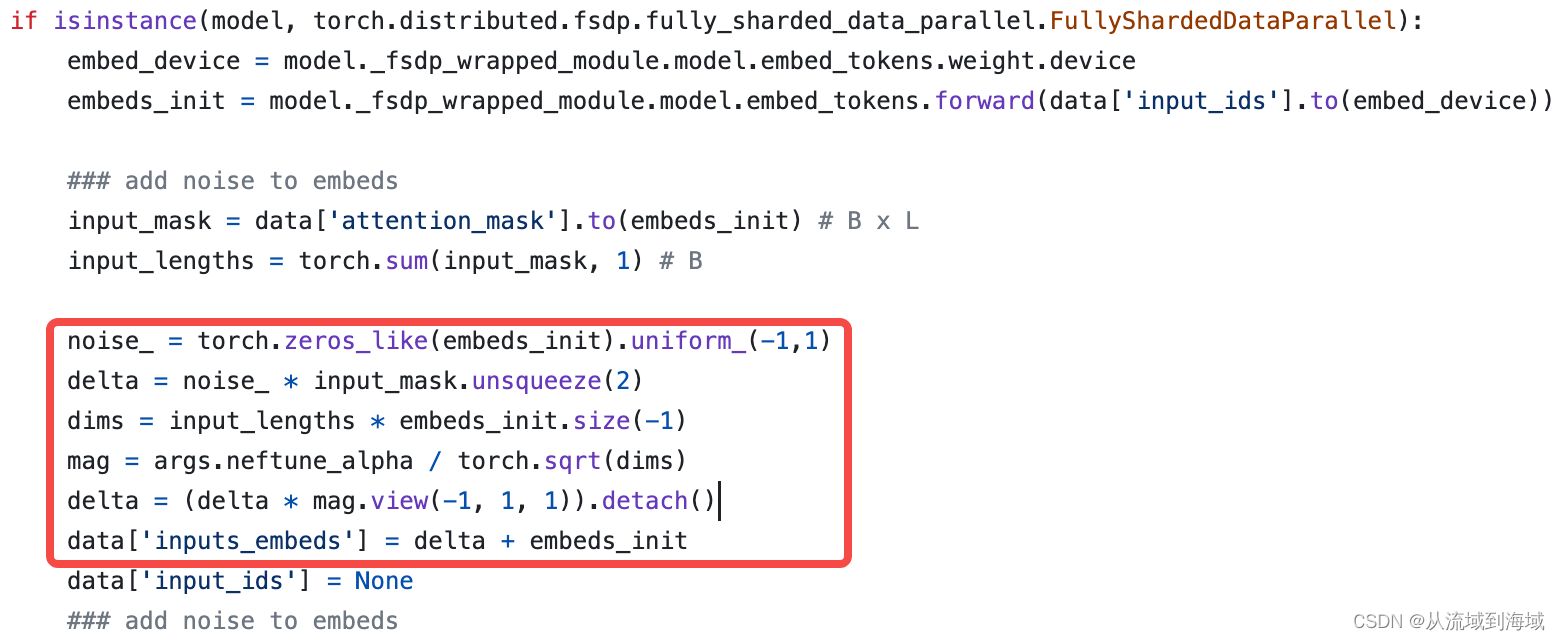
NEFTune: 通过简单的噪声提升指令精调效果
NEFTune指的是Noise Embedding Finetuning(噪声嵌入精调),提出自论文:NEFTune: NOISY EMBEDDINGS IMPROVE INSTRUCTION FINETUNING。
NEFTune方法的原理仅使用一句话就可以描述清楚:在finetune过程的词向量中引入一些…
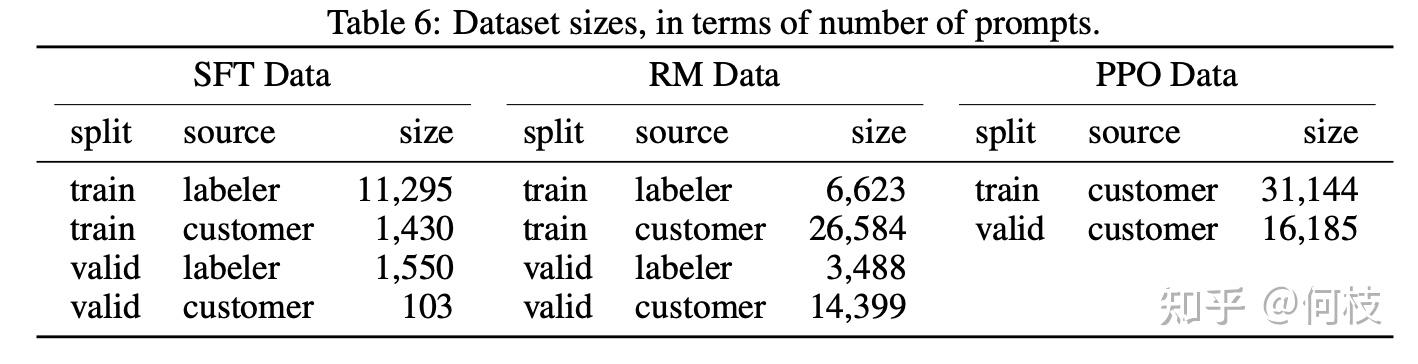

中科创达:坚定看好未来十五年的大模型机遇
中科创达是一家成立于2008年的智能操作系统产品和技术提供商,15年前公司成立的时候正赶上了安卓操作系统将功能手机推向了智能手机,截至目前,已赋能超过近9亿台手机走向市场。2014年中科创达开始拓展智能汽车方向,2015年拓展物联网…
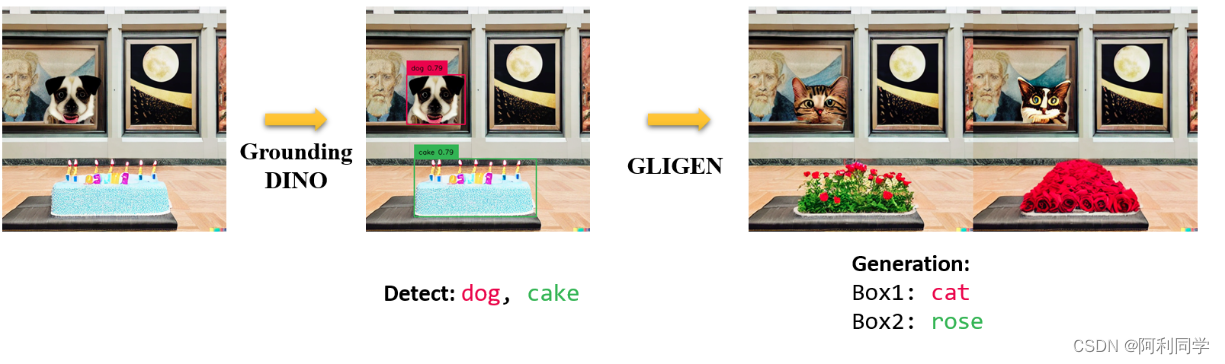
python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
省流建议 本文针对以下需求:
想自动化标注一些目标不再想使用yolo想在目标检测/语意分割有所建树计算机视觉项目想玩一玩大模型了解自动化工具了解最前沿模型自定义目标P图替换…
确定好需求,那么我们发车!
实现功能与结果
该模型将首先…
聊一聊国内大模型公司,大模型面试心得、经验、感受
有着过硬的技术却无处可用是不是很苦恼呢,大家在面试时是不是也积累了一些经验呢,本文详细总结了大佬在大模型面试时的一些经验及感悟,希望对大家面试找工作有所帮助。
2023年,大模型突然国内火了起来,笔者就面了一些…
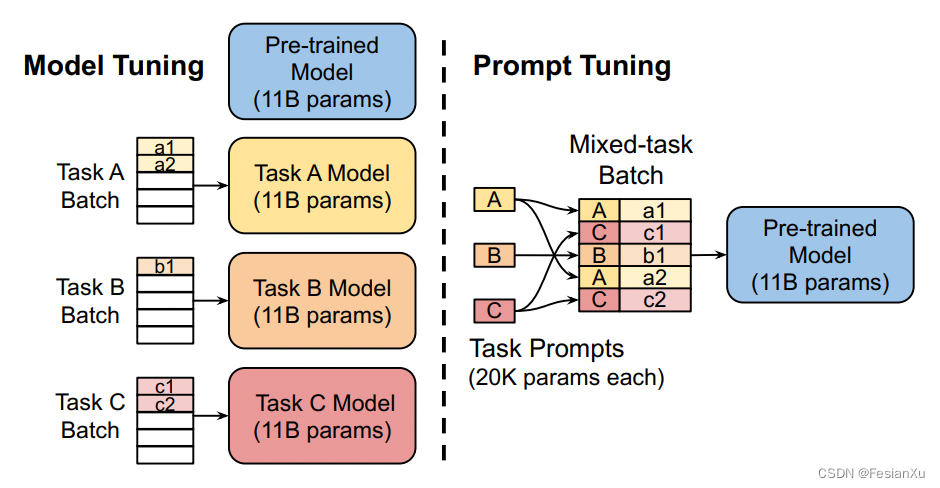
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式 FesianXu 20230928 at Baidu Search Team 前言
Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本…
大模型LLM 在线量化;GPTQ\AWQ量化
1、大模型LLM 在线量化
参考:https://www.cnblogs.com/bruceleely/p/17348782.html
##8bit
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half(
生成式 AI 落地制造业的关键是什么?亚马逊云科技给出答案
编辑 | 宋慧
出品 | CSDN 云计算 作为实体经济的重要组成部分,制造业一直以来都是国家发展的根本和基础。近年制造业的数字化转型如火如荼,今年爆火的生成式 AI 也正在进入制造业的各类场景。全球的云巨头亚马逊云科技从收购芯片公司自研开始࿰…

图解大模型微调系列之:大模型低秩适配器LoRA(原理篇)
关于LORA部分的讲解,我们将分为**“原理篇”和“源码篇”**。
在原理篇中,我们将通过图解的方式,详细分析LoRA怎么用、为什么能奏效、存在哪些优劣势等核心问题。特别是当你在学习LoRA时,如果对“秩”的定义和作用方式感到迷惑&a…

限时开发、码力全开、2w奖金!AGI Hackathon等你挑战!
AGI时代,我们已不再满足于简单的产品开发,与大模型结合的无限想象力,成为开发者们新的追求。
你有能力将想法转化为现实吗?你有勇气接受挑战,创造全新的AI应用吗?
如果你有热情,有信心&#x…
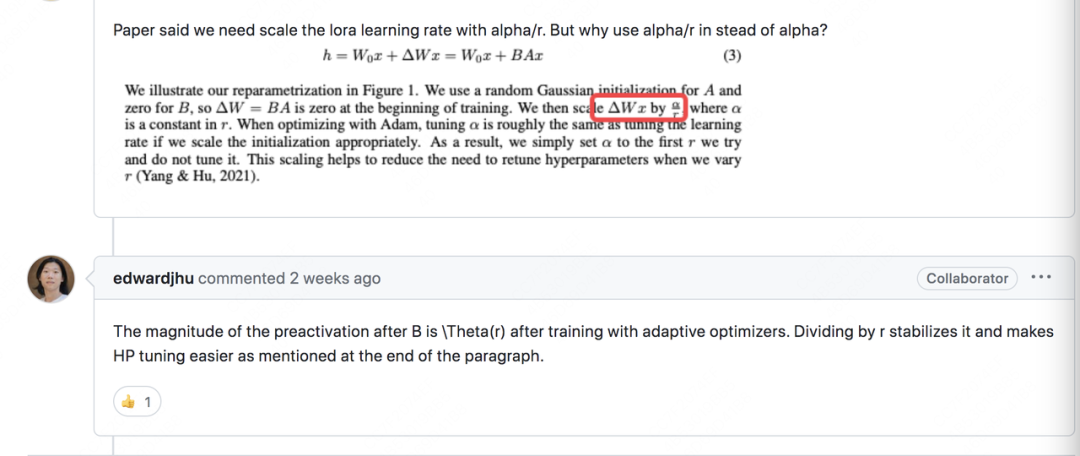
深入浅出剖析 LoRA 源码及实践
在上一篇中,我们详细阐述了LoRA的原理。在本篇中,我们将一起学习LoRA源码(微软原版)。
许多朋友在使用LoRA的过程中,都会用到HuggingFace Peft库封装好的LoRA接口,这个接口是对微软版LoRA代码的改写和封装…
XrayGLM - 医学大模型
文章目录 关于 XrayGLM研究背景VisualGLM-6B 关于 XrayGLM
XrayGLM: 首个会看胸部X光片的中文多模态医学大模型 | The first Chinese Medical Multimodal Model that Chest Radiographs Summarization. 基于VisualGLM-6B 微调
github : https://github.com/WangRongsheng/Xra…

ChatGPT启蒙之旅:弟弟妹妹的关键概念入门
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

【AI视野·今日NLP 自然语言处理论文速览 第四十七期】Wed, 4 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 4 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Contrastive Post-training Large Language Models on Data Curriculum Authors Canwen Xu, Corby Rosset, Luc…

AIGC重塑教育:AI大模型驱动的教育变革与实践
这次,狼真的来了。 AI正迅猛地改变着我们的生活。 根据高盛发布的一份报告,AI有可能取代3亿个全职工作岗位,影响全球18%的工作岗位。在欧美,或许四分之一的工作可以用AI完成。另一份Statista的报告预测,仅2023年&#…
使用DeepSpeed/P-Tuning v2对ChatGLM-6B进行微调
link 之前尝试了基于ChatGLM-6B使用LoRA进行参数高效微调,本文给大家分享使用DeepSpeed和P-Tuning v2对ChatGLM-6B进行微调,相关代码放置在GitHub上面:llm-action。 ChatGLM-6B简介 ChatGLM-6B相关的简介请查看之前的文章,这里不再…
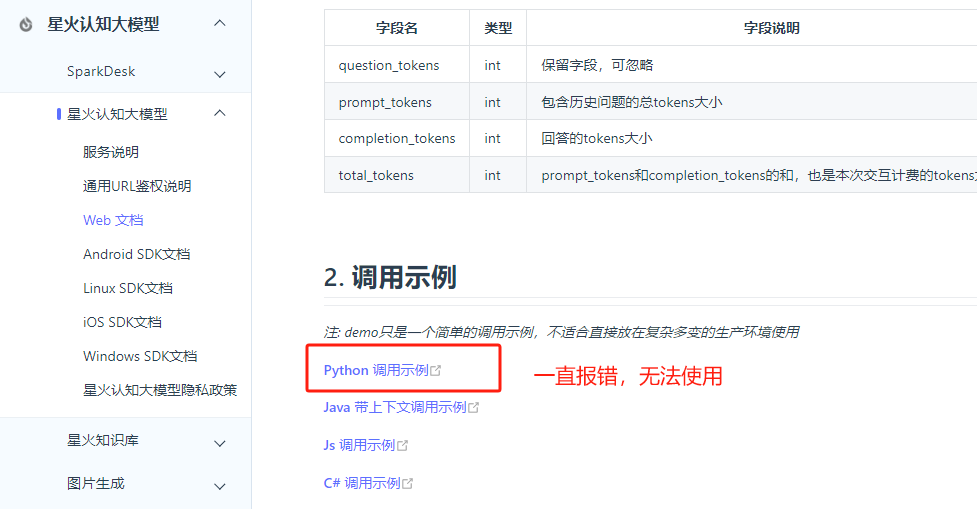
给ChuanhuChatGPT 配上讯飞星火spark大模型V2.0(一)
ChuanhuChatGPT 拥有多端、比较好看的Gradio界面,开发比较完整; 刚好讯飞星火非常大气,免费可以领取大概20w(!!!)的token,这波必须不亏,整上。
重要参考&am…

【AI视野·今日NLP 自然语言处理论文速览 第五十三期】Thu, 12 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 12 Oct 2023 Totally 69 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Proces…
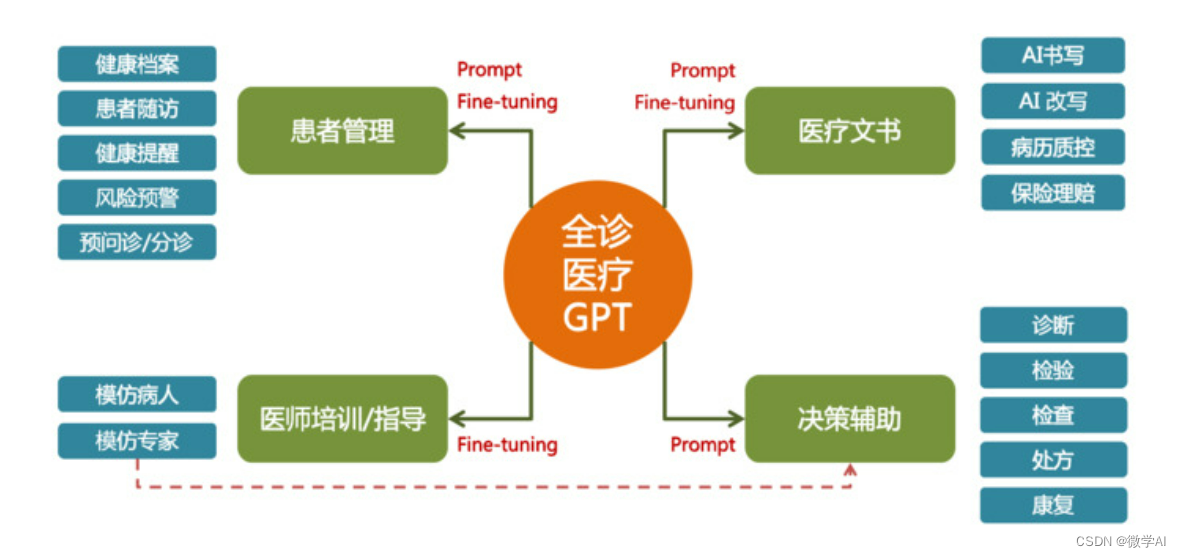
深度学习实战52-基于医疗大模型与医疗智能诊断问答的运用简单介绍,辅助医生进行疾病诊断
大家好,我是微学AI,今天给大家介绍一下深度学习实战52-基于医疗大模型与医疗智能诊断问答的运用简单介绍,辅助医生进行疾病诊断。医疗大模型通过收集和分析大量的医学数据和临床信息,可以辅助医生进行疾病诊断、治疗方案制定和预后评估等工作。利用医疗大模型,可以帮助医生…

首篇大模型压缩论文综述
首篇大模型压缩综述来啦!!!
来自中国科学院和人民大学的研究者们深入探讨了基于LLM的模型压缩研究进展并发表了该领域的首篇综述《A Survey on Model Compression for Large Language Models》。
Abstract
大型语言模型(LLMs&a…

太良心了!微软面向初学者,开源机器学习、数据科学、AI、LLM
大家好,推荐几个质量上乘且完全免费的微软开源课程,由粉丝小伙伴梳理,分享给大家。
文末可以加我们粉丝群
面向初学者的机器学习课程 ML for beginners banner
地址:https://microsoft.github.io/ML-For-Beginners/#/
学习经典…

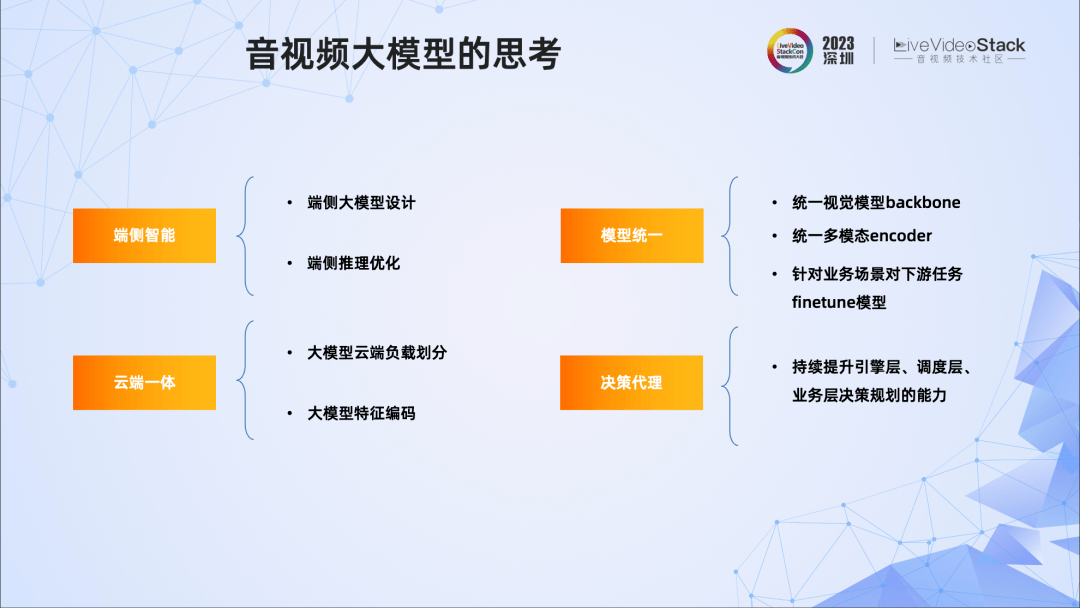
AI浪潮下,大模型如何在音视频领域运用与实践?
视频云大模型算法「方法论」。 刘国栋|演讲者
在AI技术发展如火如荼的当下,大模型的运用与实践在各行各业以千姿百态的形式展开。音视频技术在多场景、多行业的应用中,对于智能化和效果性能的体验优化有较为极致的要求。如何运用好人工智能提…

浪潮信息“拓荒”:一场面向大模型时代的性能“压榨”
文 | 智能相对论
作者 | 沈浪
全球人工智能产业正被限制在了名为“算力”的瓶颈中,一侧是供不应求的高端芯片,另一侧则是激战正酣的“百模大战”,市场的供求两端已然失衡。
然而,大多数人的关注点仍旧还是在以英伟达为主导的高…

用通俗易懂的方式讲解大模型:Prompt 提示词在开发中的使用
OpenAI 的 ChatGPT 是一种领先的人工智能模型,它以其出色的语言理解和生成能力,为我们提供了一种全新的与机器交流的方式。但不是每个问题都可以得到令人满意的答案,如果想得到你所要的回答就要构建好你的提示词 Prompt。本文将探讨 Prompt 提…
2024-01-04 用llama.cpp部署本地llama2-7b大模型
点击 <C 语言编程核心突破> 快速C语言入门 用llama.cpp部署本地llama2-7b大模型 前言一、下载llama.cpp以及llama2-7B模型文件二、具体调用总结 使用协议: License to use Creative Commons Zero - CC0 该图片个人及商用免费,无需显示归属,但如果…
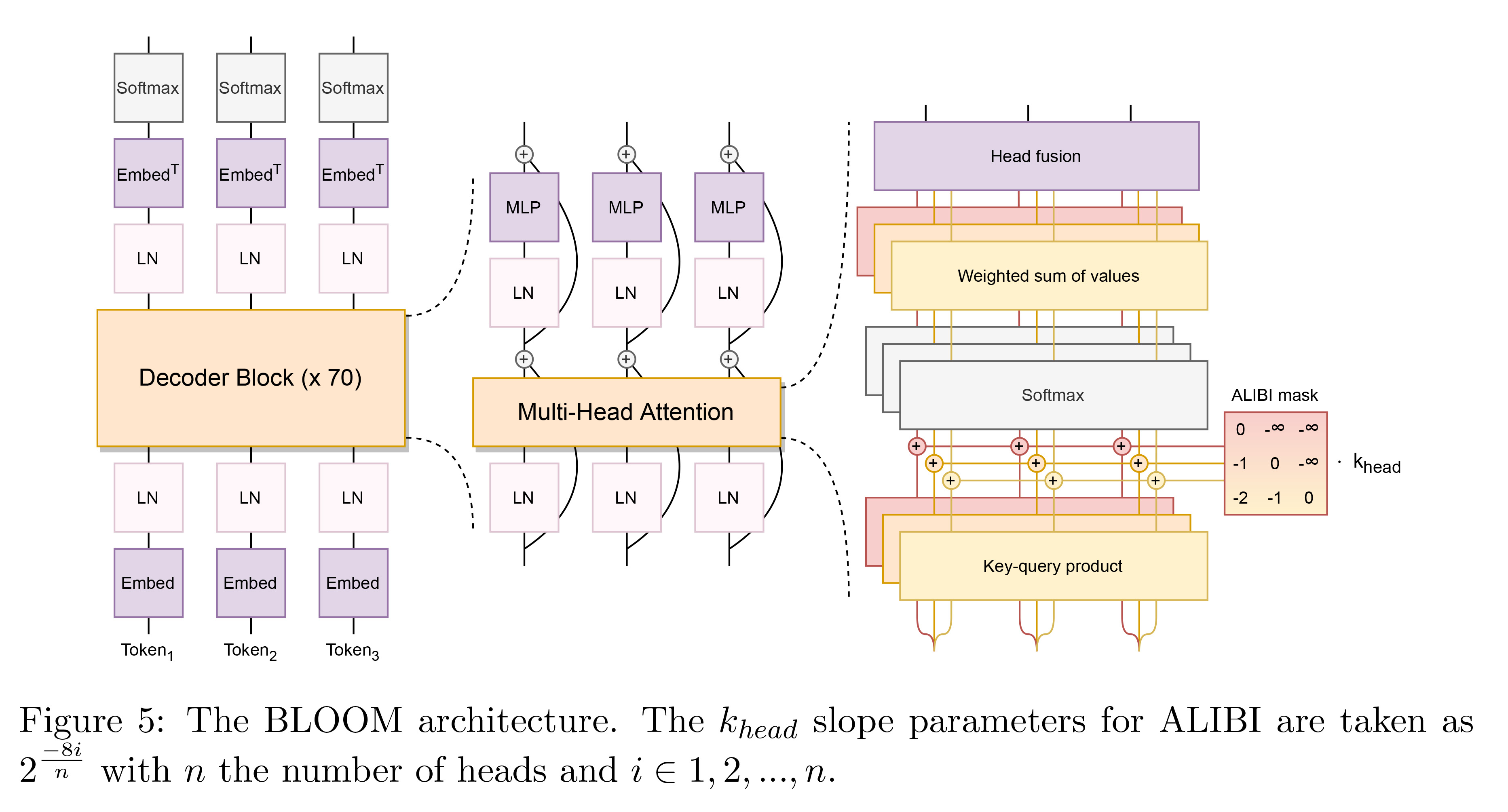
乘骐骥以驰骋兮,来吾道夫先路——2023年大模型技术基础架构盘点与开源工作速览
目录 一、模型基本架构1.1、自回归(Autoregressive)模型架构1.2、自编码(Autoencoder)模型架构1.3、完整的编码-解码模型架构 二、典型开源工作速览2.1、LLaMA-22.2、baichuan-22.3、Falcon2.4、BLOOM 最后 在过去的一年里&#x…

【AI视野·今日Robot 机器人论文速览 第六十七期】Mon, 1 Jan 2024
AI视野今日CS.Robotics 机器人学论文速览 Mon, 1 Jan 2024 Totally 16 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers
MURP: Multi-Agent Ultra-Wideband Relative Pose Estimation with Constrained Communications in 3D Environments Authors A…
GPT实战系列-大模型为我所用之借用ChatGLM3构建查询助手
GPT实战系列-https://blog.csdn.net/alex_starsky/category_12467518.html
如何使用大模型查询助手功能?例如调用工具实现网络查询助手功能。目前只有 ChatGLM3-6B 模型支持工具调用,而 ChatGLM3-6B-Base 和 ChatGLM3-6B-32K 模型不支持。
定义好工具的…
通过cpolar在公网访问本地网站
通过cpolar可以轻松将本地网址映射到公网进行访问,下面简要介绍一下实现步骤。
目录
一、cpolar下载
二、安装
三、使用
3.1 登录
3.2 创建隧道 一、cpolar下载
cpolar官网地址:cpolar - secure introspectable tunnels to localhost 通过QQ邮箱…

大模型LLM训练的数据集
引言
2021年以来,大预言模型的开发和生产使用呈现出爆炸式增长。除了李开复、王慧文、王小川等“退休”再创业的互联网老兵,在阿里巴巴、腾讯、快手等互联网大厂的中高层也大胆辞职,加入这波创业浪潮。
通用大模型初创企业MiniMax完成了新一…

用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
Retrieval-Augmented Generation(RAG)是一种强大的技术,能够提高大型语言模型(LLM)的性能,使其能够从外部知识源中检索信息以生成更准确、具有上下文的回答。
本文将详细介绍 RAG 在 LangChain 中的应用&a…

GPT(Generative Pre-Training)论文解读及源码实现(二)
本篇为gpt2的pytorch实现,参考 nanoGPT
nanoGPT如何使用见后面第5节
1 数据准备及预处理
data/shakespeare/prepare.py 文件源码分析
1.1 数据划分
下载数据后90%作为训练集,10%作为验证集
with open(input_file_path, r) as f:data f.read()
n …
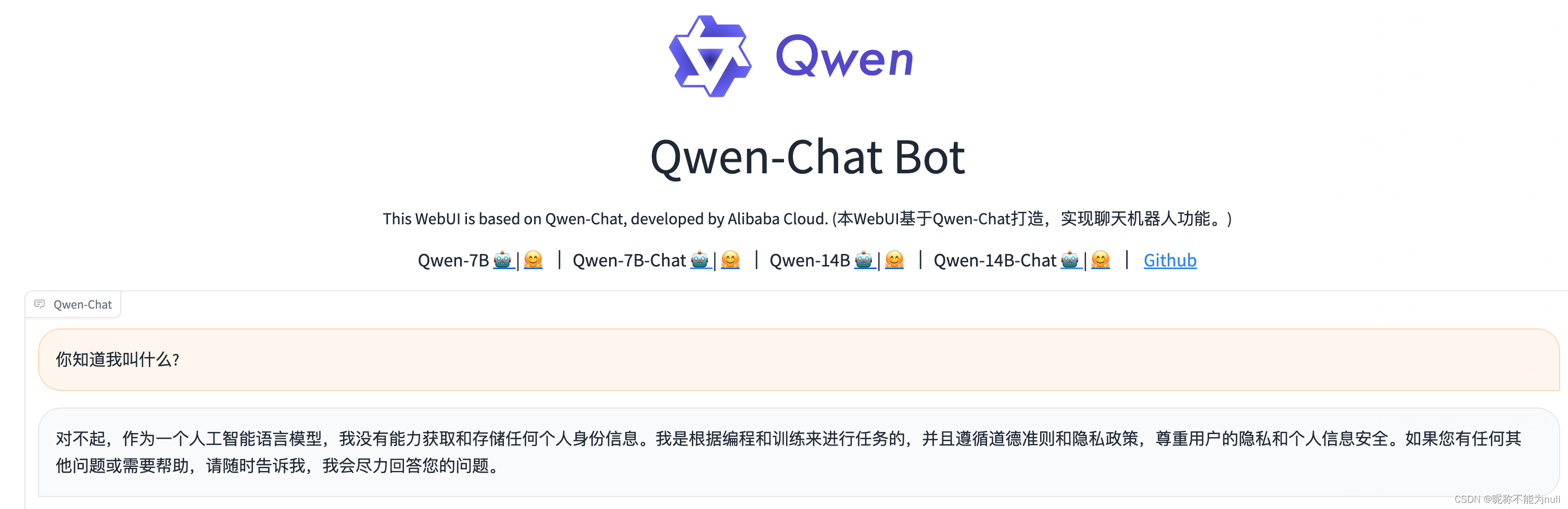
使用开源通义千问模型(Qwen)搭建自己的大模型服务
目标
1、使用开源的大模型服务搭建属于自己的模型服务;
2、调优自己的大模型;
选型
采用通义千问模型,https://github.com/QwenLM/Qwen
步骤
1、下载模型文件 开源模型库:https://www.modelscope.cn/models mkdir -p /data/…
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
QA对话目前是大语言模型的一大应用场景,在QA对话中,由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。
在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回…

用通俗易懂的方式讲解:使用 LangChain 和 LlamaIndex 从零构建PDF聊天机器人
随着大型语言模型(LLM)(如ChatGPT和GPT-4)的兴起,现在比以往任何时候都更容易搭建智能聊天机器人,并且可以堆积如山的文档,为你的输入提供更准确的响应。 无论你是想构建个人助理、定制聊天机器…

精细微调技术在大型预训练模型优化中的应用
目录 前言1 Delta微调简介2 参数微调的有效性2.1 通用知识的激发2.2 高效的优化手段3 Delta微调的类别3.1 增量式微调3.2 指定式微调3.3 重参数化方法 4 统一不同微调方法4.1 整合多种微调方法4.2 动态调整微调策略4.3 超参数搜索和优化 结语 前言
随着大型预训练模型在自然语…
【LangChain学习之旅】—(8) 输出解析:用OutputParser生成鲜花推荐列表
【LangChain学习之旅】—(8) 输出解析:用OutputParser生成鲜花推荐列表 LangChain 中的输出解析器Pydantic(JSON)解析器实战第一步:创建模型实例第二步:定义输出数据的格式第三步:创…

大模型分布式训练并行技术(四)-张量并行
linkj 近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。 而利用AI集…
人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用
大家好,我是微学AI ,今天给大家介绍一下人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用,随着人工智能(AI)和深度学习技术的发展,大模型已经开始渗透到各个领域,包括数学教育。本文将详细介绍基于大模型在数学…

如何在 Keras 中开发具有注意力的编码器-解码器模型
link 【翻译自 : How to Develop an Encoder-Decoder Model with Attention in Keras 】 【说明:Jason Brownlee PhD大神的文章个人很喜欢,所以闲暇时间里会做一点翻译和学习实践的工作,这里是相应工作的实践记录,…

一起乐「FUN」天!大模型趣味赛等你来挑战!
是不是厌倦了枯燥的开发生活,想来点新鲜刺激的事情?赶紧加入「大模型摇摇乐」活动吧!释放你的创意,一起摇摇乐!
摇出创意,摇出喜爱,摇出礼品!
在这个充满创意火花的活动中…
人工智能三要数之算法Transformer
1. 人工智能三要数之算法Transformer
人工智能的三个要素是算法、数据和计算资源。Transformer 模型作为一种机器学习算法,可以应用于人工智能系统中的数据处理和建模任务。 算法: Transformer 是一种基于自注意力机制的神经网络模型,用于处理序列数据的…
GPT实战系列-大模型训练和预测,如何加速、降低显存
GPT实战系列-大模型训练和预测,如何加速、降低显存
不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,…
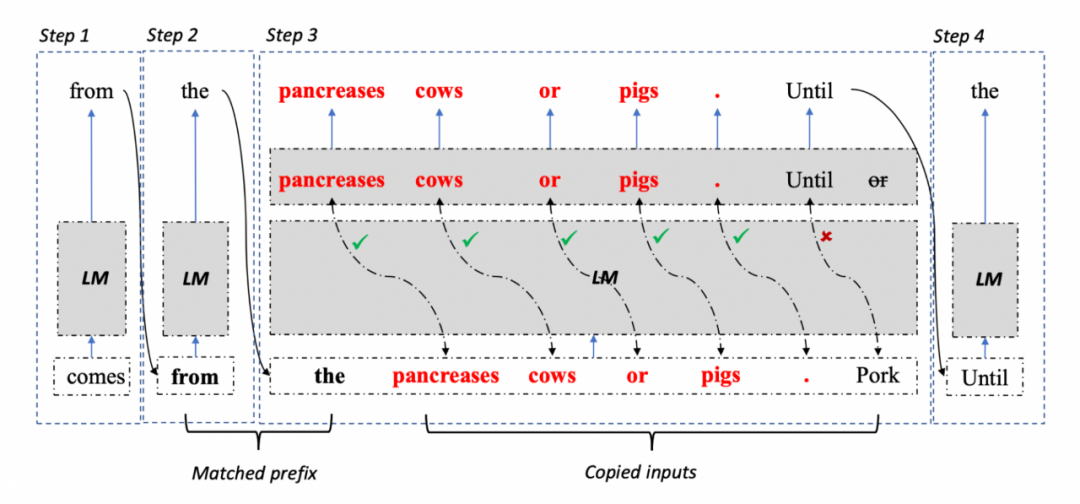
大模型在百度智能问答、搜索中的应用
本文主要介绍了智能问答技术在百度搜索中的应用。包括机器问答的发展历程、生成式问答、百度搜索智能问答应用。欢迎大家加入百度搜索团队,共同探索智能问答技术的发展方向,文末有简历投递方式。
01
什么是机器问答
机器问答,就是让计算机…

Prompt Engineering | 编写prompt的原则与策略
😄 为了更好地与大模型(e.g. chatgpt)更好的交流,一起来学习如何写prompt吧!😄 文章目录 1、简介2、编写prompt的原则与策略2.1、编写清晰、具体的指令2.1.1、策略一:使用分隔符清晰地表示输入的…

缓解大模型幻觉问题的解决方案
本文记录大模型幻觉问题的相关内容。 参考:Mitigating LLM Hallucinations: a multifaceted approach 地址:https://amatriain.net/blog/hallucinations (图:解决大模型幻觉的不同方式)
什么是幻觉?
幻觉…
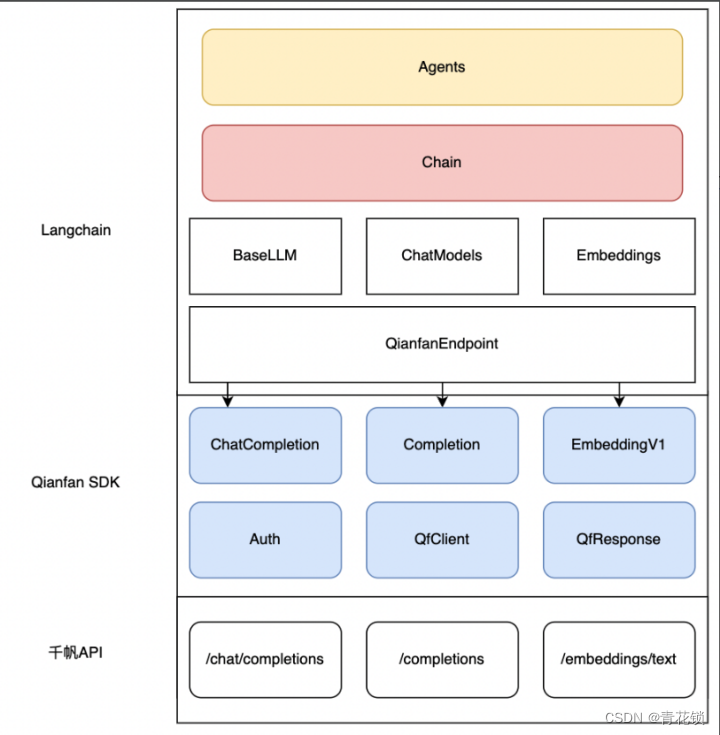
百度智能云正式上线Python SDK版本并全面开源
文章目录 前言一、SDK的优势二、千帆SDK:快速落地LLM应用三、如何快速上手千帆SDK3.1、SDK快速启动3.2. SDK进阶指引 3.3. 通过Langchain接入千帆SDK4、开源社区 前言
百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线…

mac M系列芯片安装chatGLM3-6b模型
1 环境安装
1.1 mac安装conda.
下载miniconda,并安装
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
sh Miniconda3-latest-MacOSX-arm64.sh1.2 创建虚拟环境并激活
创建名为chatglm3的虚拟环境,python版本为3.10…
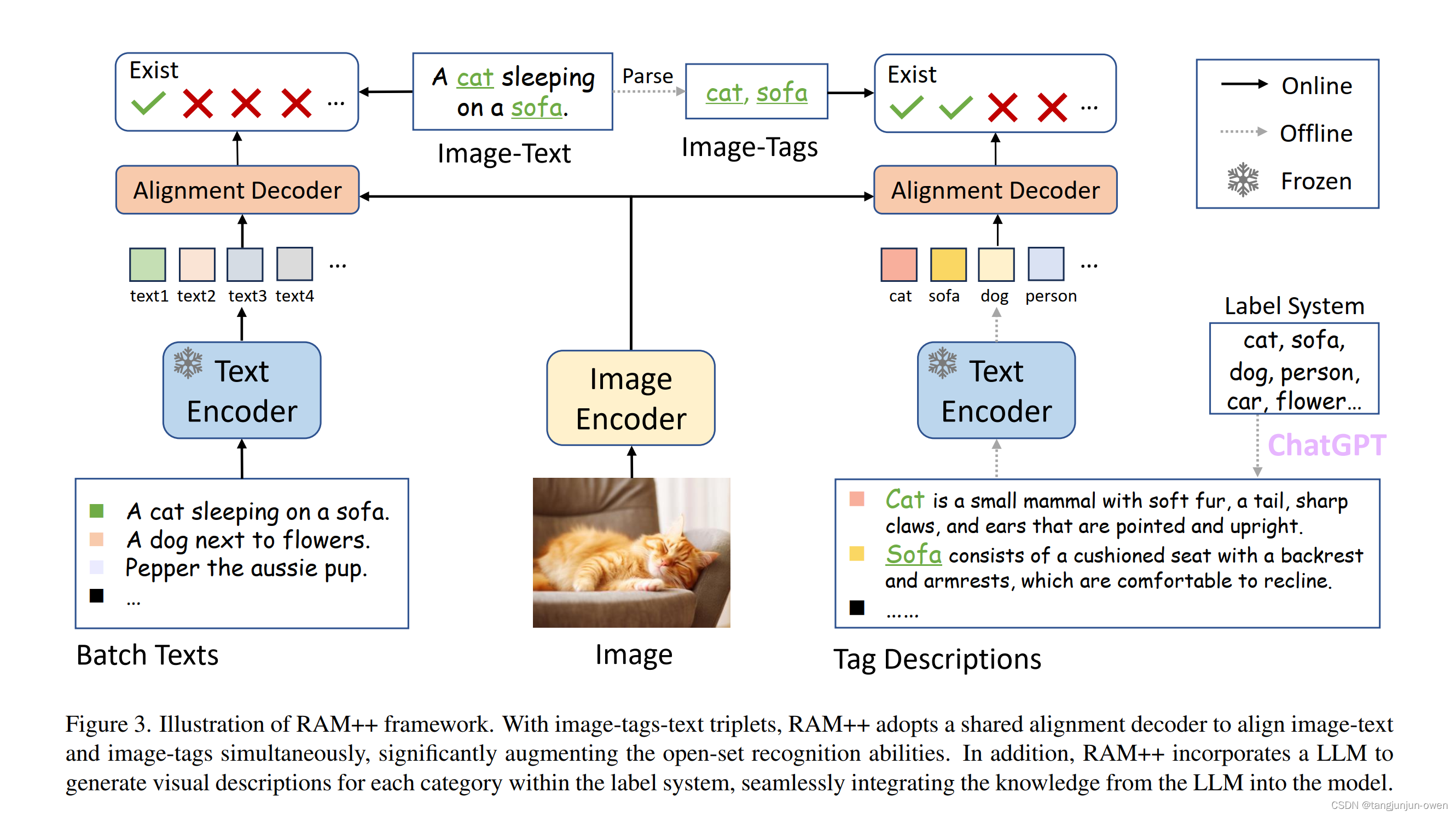
Grounding DINO、TAG2TEXT、RAM、RAM++论文解读
提示:Grounding DINO、TAG2TEXT、RAM、RAM论文解读 文章目录 前言一、Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection1、摘要2、背景3、部分文献翻译4、贡献5、模型结构解读a.模型整体结构b.特征增强结构c.解码结构 6、实…

技术实践|百度安全「大模型内容安全」高级攻击风险评测
1、引子
2023年10月16日,OWASP发布了《OWASP Top 10 for LLM Applications》,这对于新兴的大语言模型安全领域,可谓一份纲领性的重要报告。
OWASP是开放式Web应用程序安全项目(Open Web Application Security Project࿰…

云音乐大模型 Agent 探索实践
一. 前言
本篇文章介绍了大语言模型时代下的 AI Agent 概念,并以 LangChain 为例详细介绍了 AI Agent 背后的实现原理,随后展开介绍云音乐在实践 AI Agent 过程中的遇到的问题及优化手段。通过阅读本篇文章,读者将掌握业界主流的 AI Agent 实…
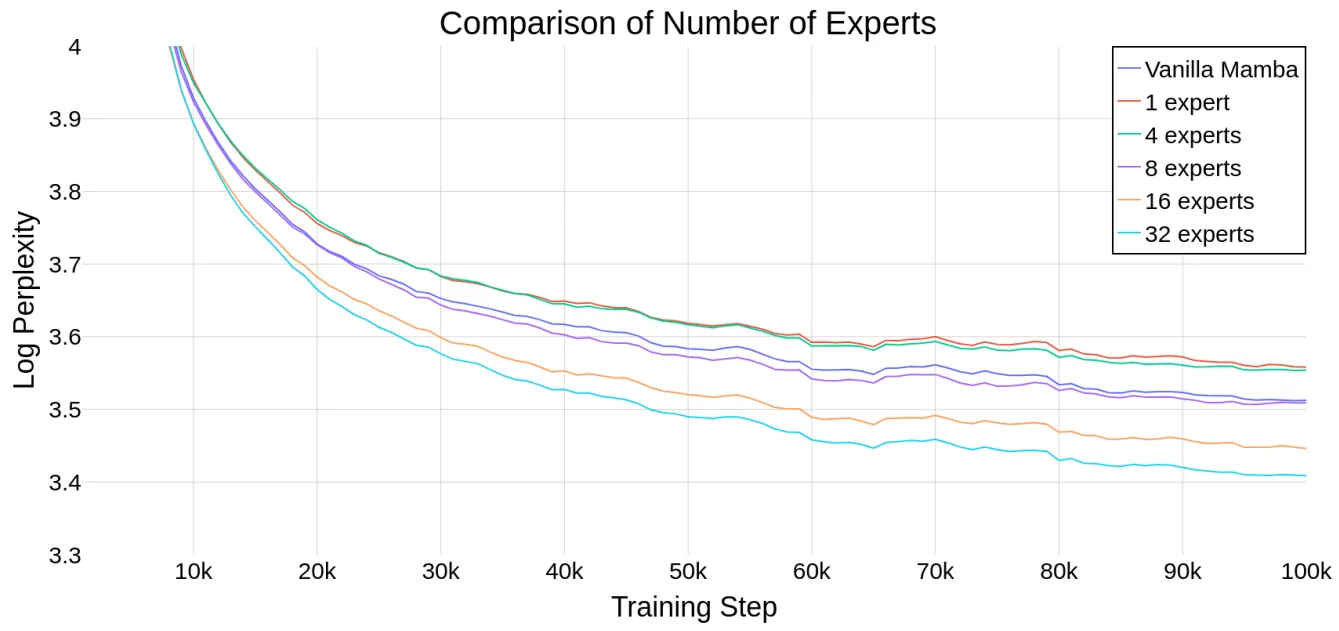
Mamba与MoE架构强强联合,Mamba-MoE高效提升LLM计算效率和可扩展性
论文题目: MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts 论文链接: https://arxiv.org/abs/2401.04081 代码仓库: GitHub - llm-random/llm-random 作为大型语言模型(LLM)基础架构的后…
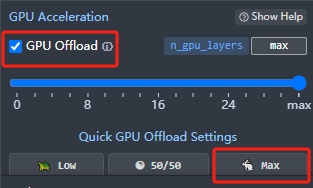
好用且简单的本地大模型聊天工具LM Studio
先看效果: LM Studio是我目前见到最好用,也是最简单的本地测试AI模型的工具,不需要安装python环境以及众多的组件,加载模型、启用GPU、聊天都非常简单。而且可以切换很多不同类型的大语言模型,同时支持在Windows和MA…
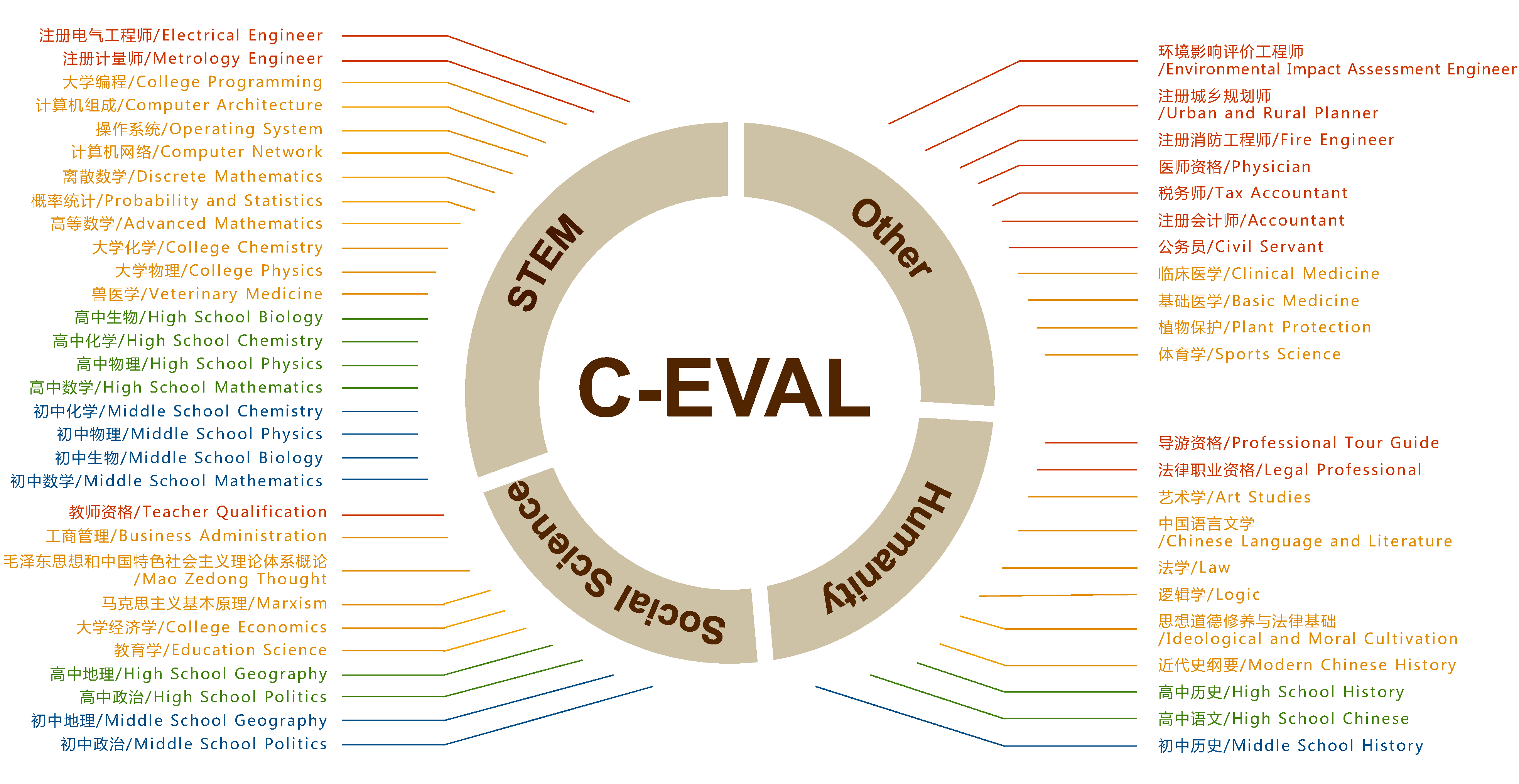
大模型(LLM)的量化技术Quantization原理学习
在自然语言处理领域,大型语言模型(LLM)在自然语言处理领域的应用越来越广泛。然而,随着模型规模的增大,计算和存储资源的需求也急剧增加。为了降低计算和存储开销,同时保持模型的性能,LLM大模型…

Midjourney入门:AI绘画真的能替代人类的丹青妙笔吗?
名人说:一花独放不是春,百花齐放花满园。——《增广贤文》 作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、简要介绍1、Midjourney2、使用方法 二、绘画1、动物类2、风景类3、动漫类4、艺…
基于Llama 2家族的提示词工程:Llama 2 Chat, Code Llama, Llama Guard
Prompt Engineering with Llama 2
本文是学习 https://www.deeplearning.ai/short-courses/prompt-engineering-with-llama-2/ 的学习笔记。 文章目录 Prompt Engineering with Llama 2What you’ll learn in this course [1] Overview of Llama Models[2] Getting Started wi…
大模型概念解析 | Prompt Engineering
注1:本文系"概念解析"系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:大模型中的Prompt Engineering 大模型概念解析 | Prompt Engineering
第一部分 通俗解释
在人工智能的世界里,有一群被称为大模型的巨无霸。它们就像是知识的海绵…
【C语言】C语言编程实战:Base64编解码算法从理论到实现(附完整代码)
🧑 作者简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向的学习指导…

快速部署本地知识库大模型(Langchain+ChatGLM3)
使用AutoDL AI算力云:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL,注册后充值后进入控制台 点击租用新实例,选择机器和社区镜像langchain-chatchat如下 创建成功后进去JupyterLab 打开终端运行如下命令
$ cd /root/Langchain-Chatch…
从大模型到Agentscope——Multi-Agent框架应用与开发
目录 大模型发展历程 大模型的缺陷 智能体 Agent的构建 模型计划内存工具
Agent到多Agent Multi-Agent 带来性能提升的同时也带来一些新的问题 流程设计鲁棒可靠多模态多系统提升运行效率
Multi-Agent框架 AgentScope Demo 三行代码实现聊天机器人 预告

用通俗易懂的方式讲解:大模型 Rerank 模型部署及使用技巧总结
Rerank 在 RAG(Retrieval-Augmented Generation)过程中扮演了一个非常重要的角色,普通的 RAG 可能会检索到大量的文档,但这些文档可能并不是所有的都跟问题相关,而 Rerank 可以对文档进行重新排序和筛选,让…

【大模型API调用初尝试二】星火认知大模型 百度千帆大模型
大模型API调用初尝试二 科大讯飞—星火认知大模型单轮会话调用多轮会话调用 百度—千帆大模型获取access_token单轮会话多轮会话 科大讯飞—星火认知大模型
星火认知大模型是科大讯飞开发的,直接使用可以点击星火认知大模型,要调用API的话在讯飞开发平台…
【Paper Reading】7.DiT(VAE+ViT+DDPM) Sora的base论文
VAE
DDPM 分类 内容 论文题目 Scalable Diffusion Models with Transformers 作者 William Peebles (UC Berkeley), Saining Xie (New York University) 发表年份 2023 摘要 介绍了一类新的扩散模型,这些模型利用Transformer架构,专注于图像生…

深入浅出落地应用分析:AI数字人「微软小冰」
hi,各位,今天要聊的是AI小冰,机缘巧合,投递了这家公司的产品,正好最近在看数字人相关的,就详细剖析下这款产品!
前言
小冰,全称为北京红棉小冰科技有限公司,前身为微软(亚洲)互联网工程院人工智能小冰团队,是微软全球最大的人工智能独立产品研发团队。作为微软全…

Monkey 和 TextMonkey ---- 论文阅读
文章目录 Monkey贡献方法增强输入分辨率多级描述生成多任务训练 实验局限结论 TextMonkey贡献方法移位窗口注意(Shifted Window Attention)图像重采样器(Image Resampler)Token Resampler位置相关任务(Position-Relate…
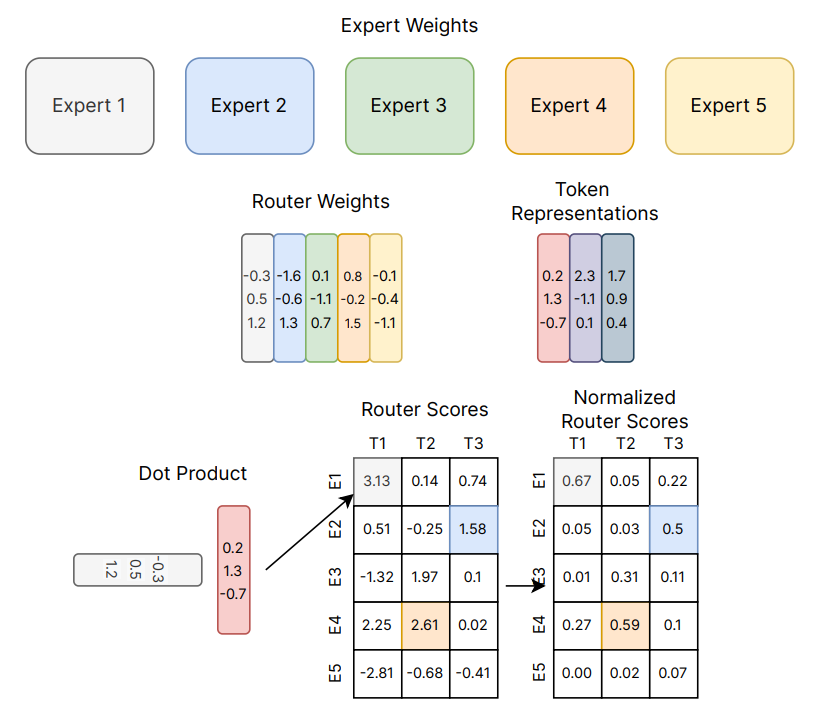
大模型面试准备(九):简单透彻理解MoE
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这…
大模型 智能体 智能玩具 智能音箱 构建教程 wukong-robot
视频演示 10:27
一、背景
继上文《ChatGPT+小爱音响能擦出什么火花?》可以看出大伙对AI+硬件的结合十分感兴趣,但上文是针对市场智能音响的AI植入,底层是通过轮询拦截,算是hack兼容,虽然官方有提供开发者接口,也免不了有许多局限性(比如得通过特定指令唤醒),不利于我…
大模型prompt提示词如何调优?
当使用大型模型(如GPT-3.5)时,可以通过优化提示(prompt)来引导模型生成更加符合预期的内容。以下是一些调优提示词的建议:
1、清晰的问题陈述:确保你的问题或提示清晰、简明,能够准…

AI大模型的预训练、迁移和中间件编程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…

大模型学习笔记(一):部署ChatGLM模型以及stable-diffusion模型
大模型学习笔记(一):部署ChatGLM模型以及stable-diffusion模型 注册算力平台(驱动云平台)1.平台注册2.查看算力3.进入平台中心 部署ChatGLM3-6B模型1.创建项目2.配置环境设置镜像源、克隆项目修改requirements 3.修改w…
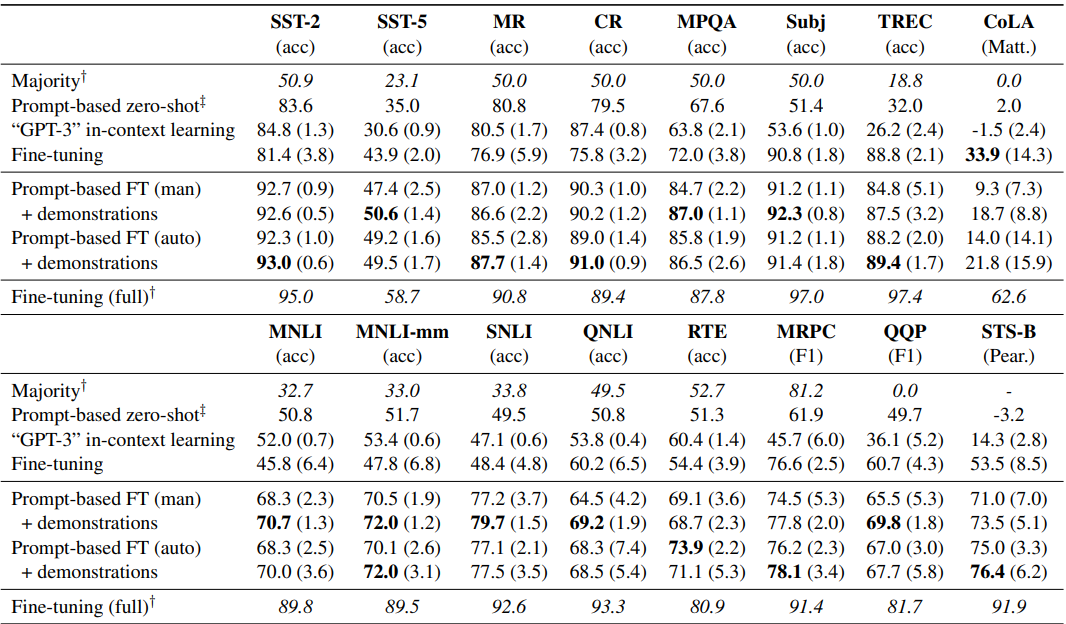
冻结Prompt微调LM: PET(b) LM-BFF
PET-TC(B) paper b: 2020.9 It’s not just size that matters: Small language models are also few-shot learners. Prompt: 多字完形填空式人工Prompt Task:Text Classification Model: Albert-xxlarge-v2 Take Away: 支持多字的完形填空Prompt&a…
qwen在vLLM下的长度外推简易方法
目的
在当前的版本vLLM中实现qwen的长度外推。
解决方法
在qwen的config.json中,增加如下内容: {"rope_scaling": { "type": "dynamic", "factor": 4.0}
}dynamic:动态NTK factor:缩放因子,外推长…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.25-2024.03.31
文章目录~ 1.Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models2.Are We on the Right Way for Evaluating Large Vision-Language Models?3.Learn "No" to Say "Yes" Better: Improving Vision-Language Models via …
BabyAGI源码解读(2)-核心agents部分
话不多说,我们直接进入babyAGI的核心部分,也就是task agent部分。
1. 创建任务agent
这一段代码的任务是创建一个任务,这个函数有四个参数
objective 目标result 结果,dict类型task_list 任务清单task_descritption 任务描述
…

生成式AI的情感实验——AI能否产生思想和情感?
机器人能感受到爱吗?这是一个很好的问题,也是困扰了科学家们很多年的科学未解之谜。虽然我们尚未准备好向智能机器赋予情感,但智能机器却已经可以借助生成式人工智能(AI)来帮助我们表达自己的情感。 自然情感表达
AI正…
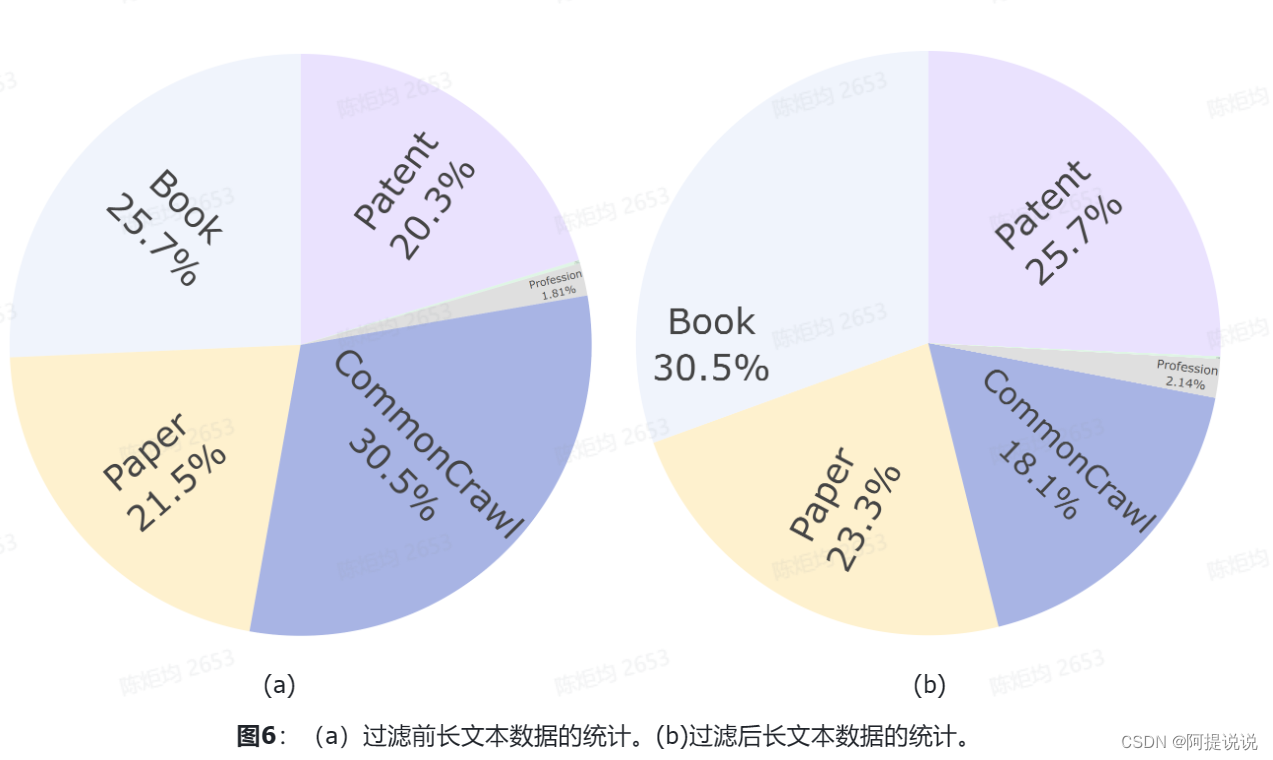
书生·浦语2.0体系技术报告
前言
本文是书生浦语二期实战营课程视频笔记,如果需要详细视频教程可自行搜索。
InternLM2 InternLM2-Base 高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点InternLM2 在Base基础上,在多个能力方向进行了强化&#x…
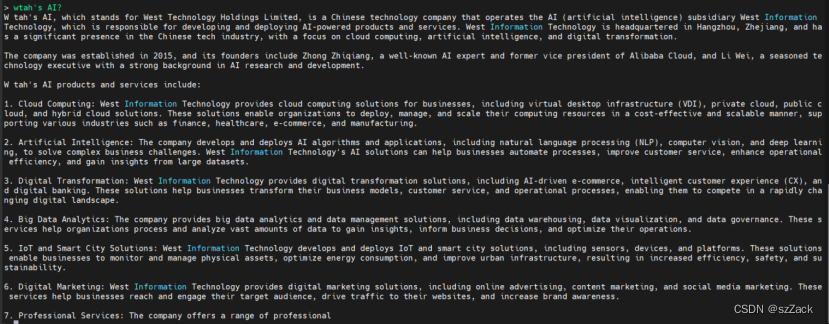
【大模型】大模型 CPU 推理之 llama.cpp
【大模型】大模型 CPU 推理之 llama.cpp llama.cpp安装llama.cppMemory/Disk RequirementsQuantization测试推理下载模型测试 参考 llama.cpp 描述 The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide var…
大模型面试准备(十一):怎样让英文大语言模型可以很好的支持中文?
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这…
面了美团大模型算法岗(实习),这次我要上岸了。。。
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总…
面了金山和 OPPO 的 NLP 算法岗,还热乎的面经分享给大家
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总…
SpringAI如何集成Ollama开发AI应用
文章目录 spring AI 介绍1. Spring ML2. Spring Data3. Spring Integration4. Spring Boot5. Spring Cloud如何开始使用 Spring AI注意事项 Spring AI集成Ollama1. 添加依赖2. 配置应用3. 注入和使用 AiClient4. 运行和测试注意事项 spring AI 介绍
Spring AI 是一个基于 Spri…
VUE3和SpringBoot实现ChatGPT页面打字效果SSE流式数据展示
在做这个功能之前,本人也是走了很多弯路(花了好几天才搞好),你能看到本篇博文,那你就是找对地方了。百度上很多都是使用SseEmitter这种方式,这种方式使用的是websocket,使用这种方式就搞复杂了&…
大模型接入外部在线信息提升应用性能
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。
大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模…
【LangChain学习之旅】—(18)回调函数:在AI应用中引入异步通信机制
【LangChain学习之旅】—(18)回调函数:在AI应用中引入异步通信机制 回调函数和异步编程LangChain 中的 Callback 处理器在组件中使用回调处理器自定义回调函数用 get_openai_callback 构造令牌计数器总结回调函数和异步编程
回调函数,你可能并不陌生。它是函数 A 作为参数…

国内20家公司大模型岗位面试经验汇总
面试情况:
投过的公司:淘天,字节,蚂蚁,商汤,美团,夸克,腾讯,minimax,零一万物,阿里控股,潞晨科技,阿里巴巴国际ÿ…
【LangChain学习之旅】—(19)CAMEL:通过角色扮演进行思考创作内容
【LangChain学习之旅】—(19)CAMEL:通过角色扮演进行思考创作内容 CAMEL 交流式代理框架股票交易场景设计场景和角色设置提示模板设计定义CAMELAgent类,用于管理与语言模型的交互预设角色和任务提示任务指定代理系统消息模板创建 Agent 实例头脑风暴开始总结大模型的成功,…
【LangChain学习之旅】—(16)检索增强生成:通过RAG助力大模型
【LangChain学习之旅】—(16)检索增强生成:通过RAG助力大模型 RAG 的工作原理文档加载文本转换文本分割器文本嵌入存储嵌入缓存存储向量数据库(向量存储)数据检索向量存储检索器各种类型的检索器索引总结什么是 RAG?其全称为 Retrieval-Augmented Generation,即检索增强…
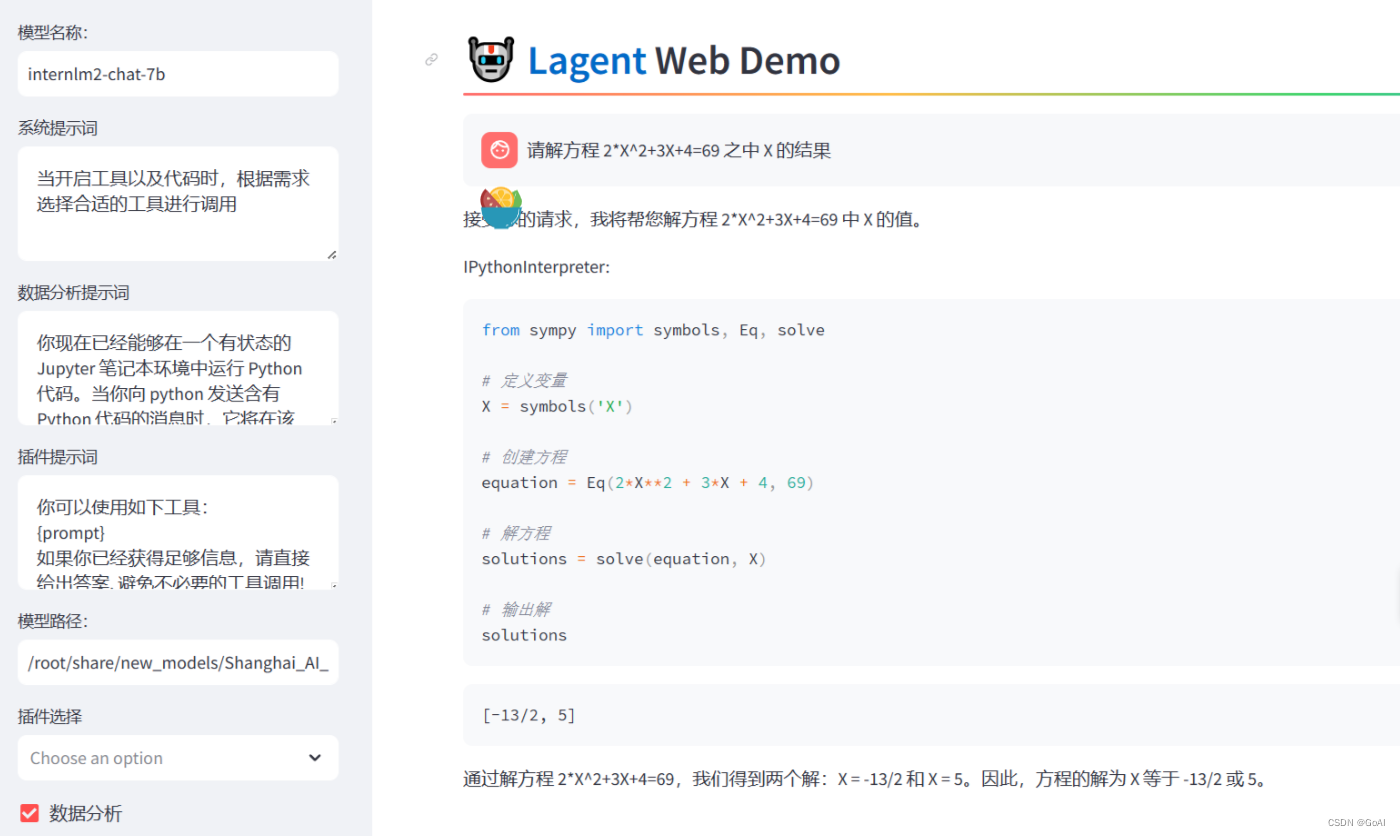
书生·浦语大模型实战营 第二课作业
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、…

科技云报道:卷完参数卷应用,大模型落地有眉目了?
科技云报道原创。
国内大模型战场的比拼正在进入新的阶段。 随着产业界对模型落地的态度逐渐回归理性,企业客户的认知从原来的“觉得大模型什么都能做”的阶段,已经收敛到“大模型能够给自身业务带来什么价值上了”。
2023 年下半年,不少企…

概念科普|大模型它到底是什么?
一、引言
ChatGPT、Open AI、大模型、提示词工程、Token、幻觉等人工智能的黑话,在2023年这个普通却又神奇的年份里,反复的冲刷着大家的认知。让一部分人彻底躺平的同时,让另外一部分人开始焦虑起来,生怕在这个人工智能的奇迹之年…

备忘,LangChain建立本地知识库的几个要点
本地知识库可以解决本地资源与AI结合的问题,为下一步应用管理已有资产奠定基础。 本地知识库的建立可参考LangChain结合通义千问的自建知识库 (二)、(三)、(四) 本文主要记录两个方面的问题 1 搭…
超级agent的端语言模型Octopus v2: On-device language model for super agent
大型语言模型(LLMs)在函数调用方面展现出卓越的应用潜力,特别是针对Android API的定制应用。与那些需要详尽描述潜在函数参数、有时甚至涉及数万个输入标记的检索增强生成(RAG)方法相比,Octopus-V2-2B在训练…

【RAG实践】Rerank,让大模型 RAG 更近一步
RAGRerank原理
上一篇【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人
我们介绍了什么是RAG,以及如何基于LLaMaIndex和Qwen1.5搭建基于本地知识库的问答机器人,原理图和步骤如下: 这里面主要包括包括三个基本步骤&#…
Anthropic Claude 3 加入亚马逊云科技 AI“全家桶”
编辑 | 宋慧
出品 | CSDN AIGC 每天都有新动态发生。最新的消息是亚马逊在 3 月底完成了对 Anthropic 的 40 亿美元投资(也是亚马逊 30 年来最大一笔外部投资),以及 GPT-4 最强对手的 Anthropic Claude 3 已经在亚马逊云科技 Amazon Bedrock…
【LocalAI】(3):LocalAI本地使用Model gallery,对qwen模型进行配置,使用modescope源下载,本地运行速度快。特别简单!
1,关于localai
LocalAI 是一个用于本地推理的,与 OpenAI API 规范兼容的 REST API。 它允许您在本地使用消费级硬件运行 LLM(不仅如此),支持与 ggml 格式兼容的多个模型系列。支持CPU硬件/GPU硬件。
模型启动方法&am…

自然语言处理(Natural Language Processing,NLP)解密
专栏集锦,大佬们可以收藏以备不时之需:
Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9
Python 专栏:http://t.csdnimg.cn/hMwPR
Redis 专栏:http://t.csdnimg.cn/Qq0Xc
TensorFlow 专栏:http://t.csdni…
datawhale 大模型学习 第四章-新模型架构
一、现状
GPT3 是一个通过96个Transformer block堆叠在一起的神经网络.即:
每一个TransformerBlock是一个多头注意力层的Block 目前大模型的规模已经到了极限(模型越大,需要训练资源和时间也就越长) 二、混合专家模型
混合专家…
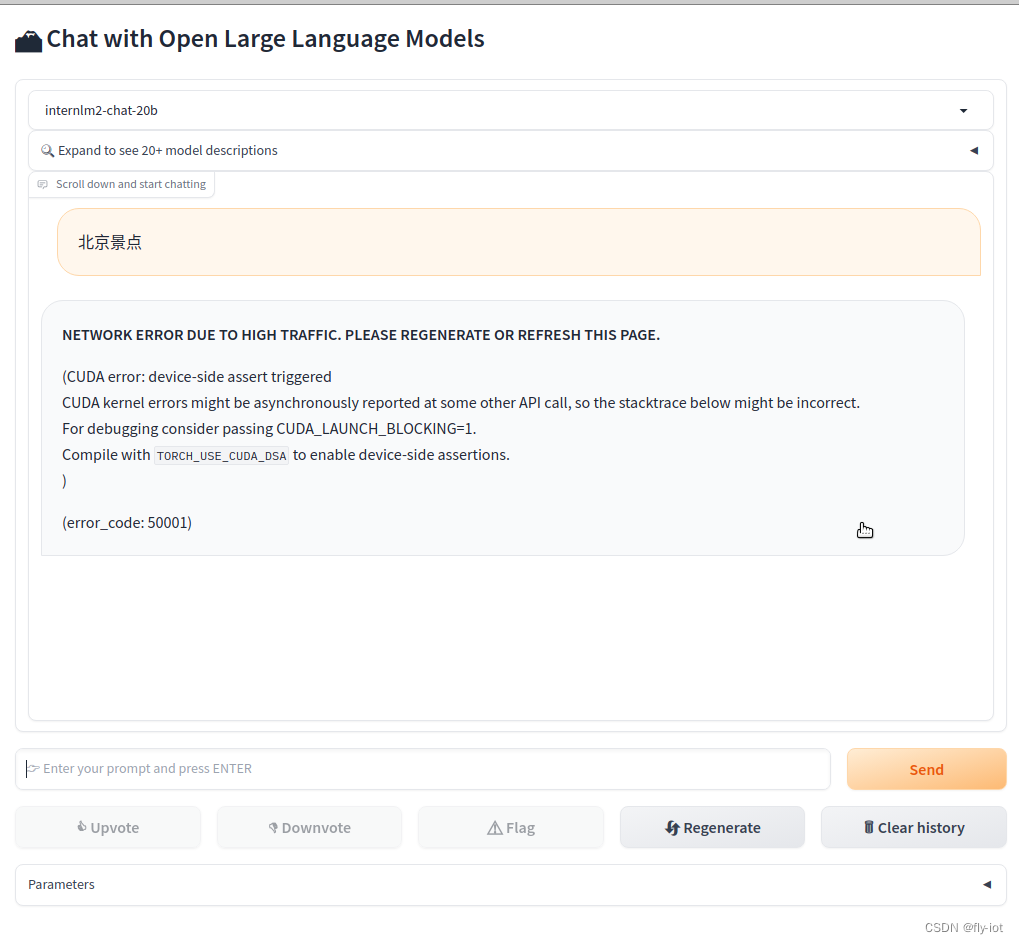
【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行
1,演示视频
https://www.bilibili.com/video/BV1pT4y1h7Af/ 【大模型研究】(1):从零开始部署书生浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行 2&…
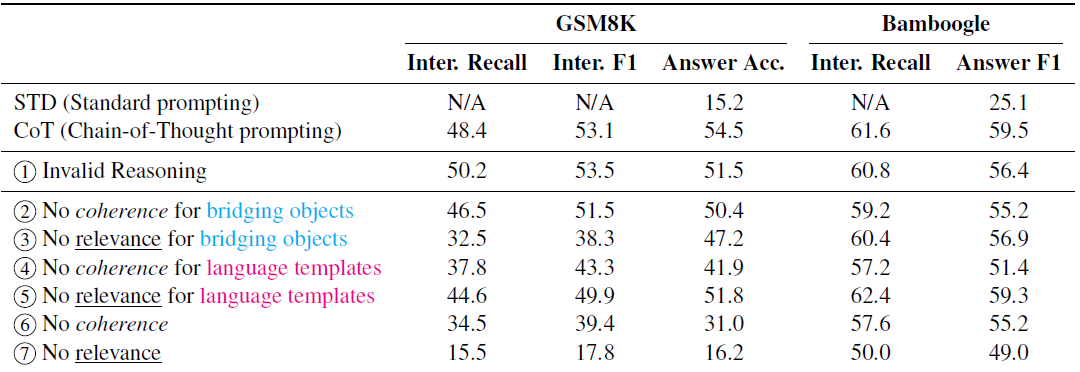
基于LLaMA Factory,单卡3小时训练专属大模型 Agent
大家好,今天给大家带来一篇 Agent 微调实战文章
Agent(智能体)是当今 LLM(大模型)应用的热门话题 [1],通过任务分解(task planning)、工具调用(tool using)和…
用react搞定一个大模型对话效果
怎么用react实现一个类似文心一言那样的对话效果呢?
最近AI盛行,关注几个大模型网站都能发现,跟AI对话的时候,返回的文本是逐字展示的,就给人一种AI边解析边返回的感觉(不知道是为了装X还是真的需要这样&a…

大模型——理论基础——常用的Norm
一、Layer Normalization
1.1 实现原理
Layer Normalization (LayerNorm) 是一种归一化技术,常用于深度学习模型中,特别是在 Transformer 模型中。
与 Batch normalization 不同,Layer normalization 是在特征维度上进行标准化的ÿ…
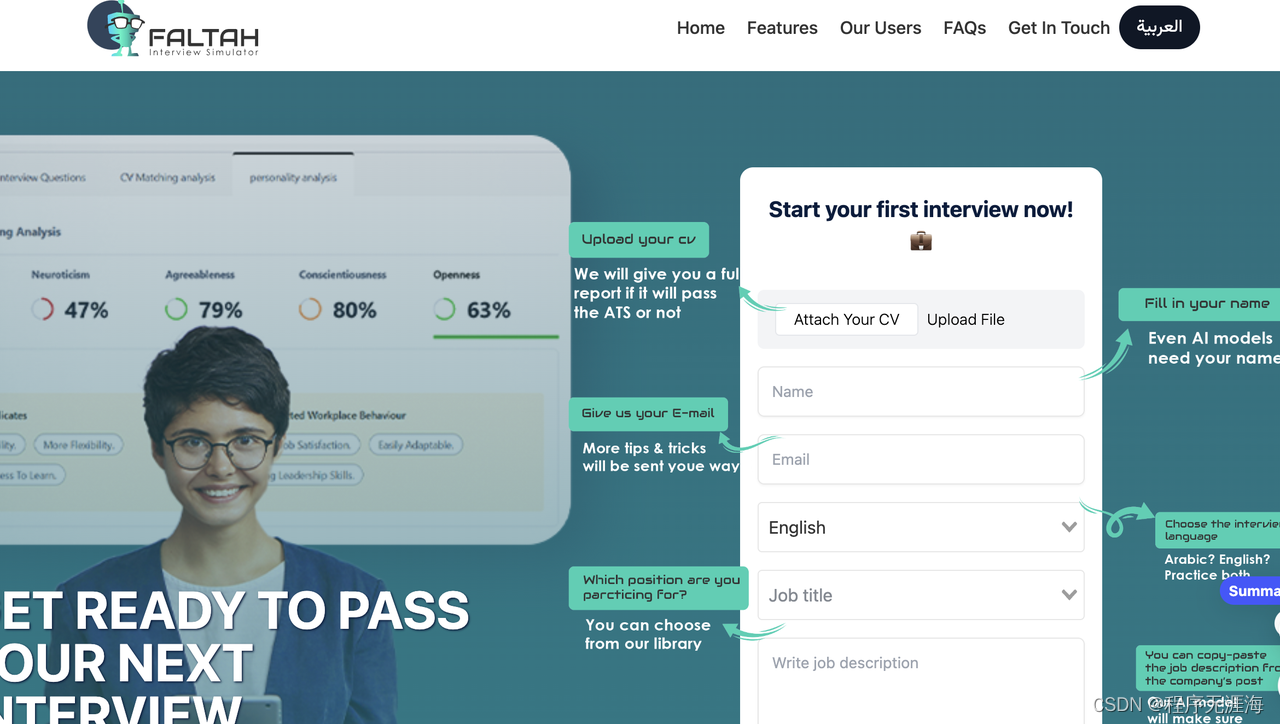
大模型日报-20240202
文章目录 企业如何使用开源LLM:16个案例多模态LLM多到看不过来?先看这26个SOTA模型吧伯克利开源高质量大型机器人操控基准,面对复杂自主操控任务不再犯难市值登顶全球!微软上财季营收创历史新高,AI需求驱动云业务增收E…
windows安装ChatGLM3
1.下载ChatGLM3代码
https://github.com/THUDM/ChatGLM3
2.下载ChatGLM3模型
web端下载可以进入主页点击下载https://huggingface.co/THUDM/chatglm3-6b/tree/main模型文件太大,vpn下载太慢了,本文使用git命令下载 需要先安装git再安装git lfs才能下…

【大模型系列】问答理解定位(Qwen-VL/Llama2/GPT)
文章目录 1 Qwen-VL(2023, Alibaba)1.1 网络结构1.2 模型训练 2 Llama2(2023, Meta)2.1 网络结构2.1.1 MHA/GQA/MQA2.1.2 RoPE(Rotary Position Embedding, 旋转式位置编码)2.1.3 RMSNorm 2.2 推理2.2.1 集束搜索(beam search)2.2.2 RoPE外推 3 GPT系列(OpenAI) 1 Qwen-VL(2023…
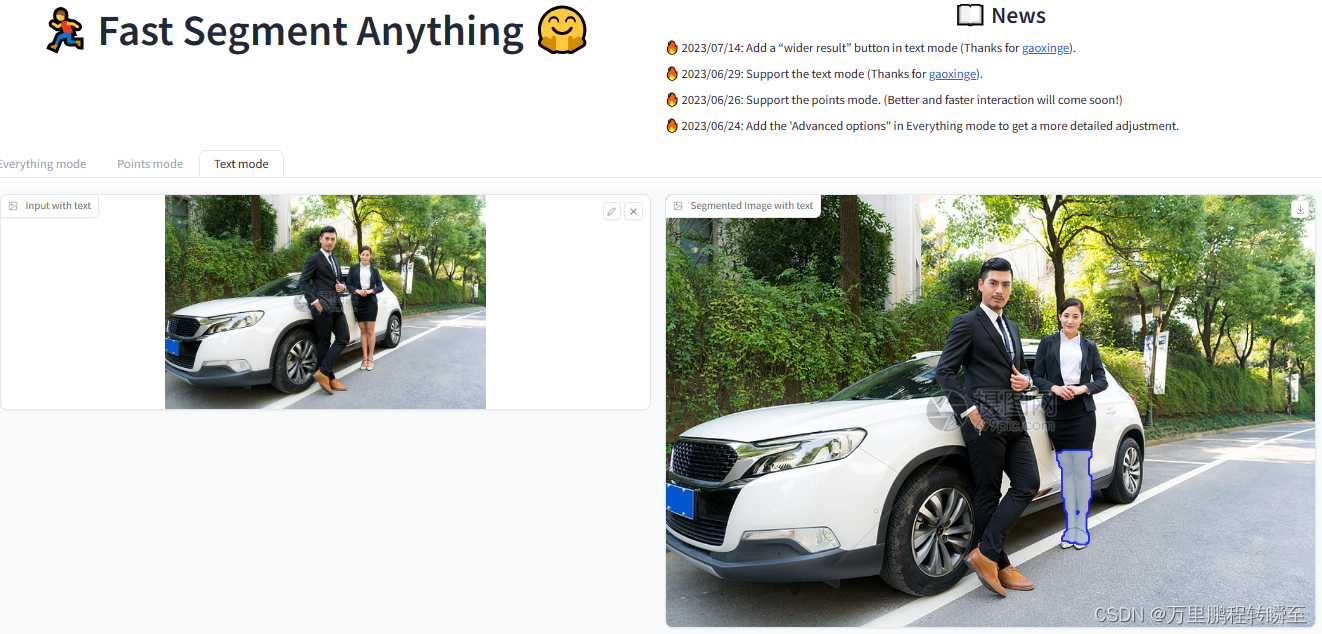
将FastSAM中的TextPrompt迁移到MobileSAM中
本博文简单介绍了SAM、FastSAM与MobileSAM,主要关注于TextPrompt功能的使用。从性能上看MobileSAM是最实用的,但其没有提供TextPrompt功能,故而参考FastSAM中的实现,在MobileSAM中嵌入TextPrompt类。并将TextPrompt能力嵌入到MobileSAM官方项目提供的gradio.py部署代码中,…

聊聊AI时代学习这件事本身应该发生什么样的变化
随着 AI 大模型 的爆发,我们身处这个时代,应该怎么样去学习去了解这些前言的技术?可能很多人会说我英文不好,我算法不行,无法深入去了解 AI 大模型相关的知识吧?
没关系,其实博主也跟大家一样&…
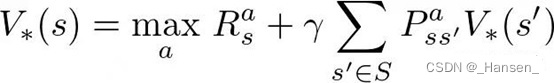
OpenAI Q-Star:AGI距离自我意识越来越近
最近硅谷曝出一份54页的内部文件,揭露了去年OpenAI宫斗,导致Altman(奥特曼)差点离职的神秘项目——Q-Star(神秘代号Q*)。 根据该文件显示,Q-Star多模态大模型拥有125万亿个参数,比现…

【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人
什么是RAG
LLM会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
正是在这样的背景下,检索增强生成技术(Retrieval-Augmented G…
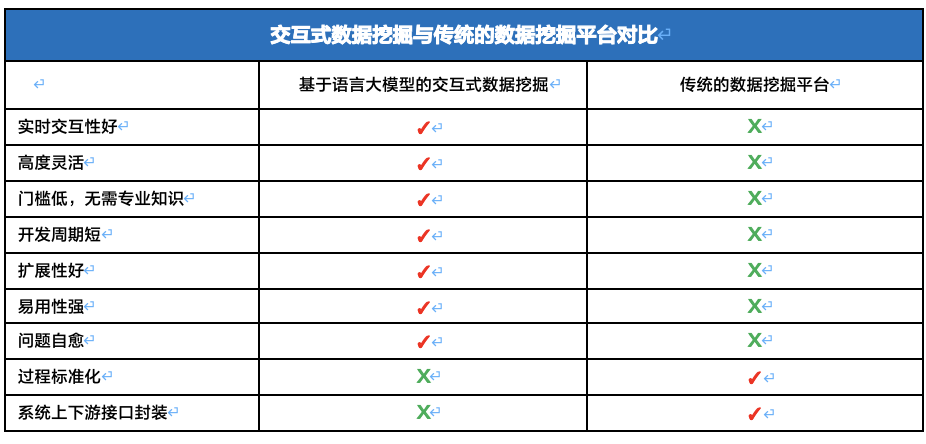
大模型下交互式数据挖掘的探索与发现
在这个数据驱动的时代,数据挖掘已成为解锁信息宝库的关键。过去,我们依赖传统的拖拉拽方式来建模,这种方式在早期的数据探索中起到了作用,但随着数据量的激增和需求的多样化,它的局限性逐渐显露。 >>>> 首…
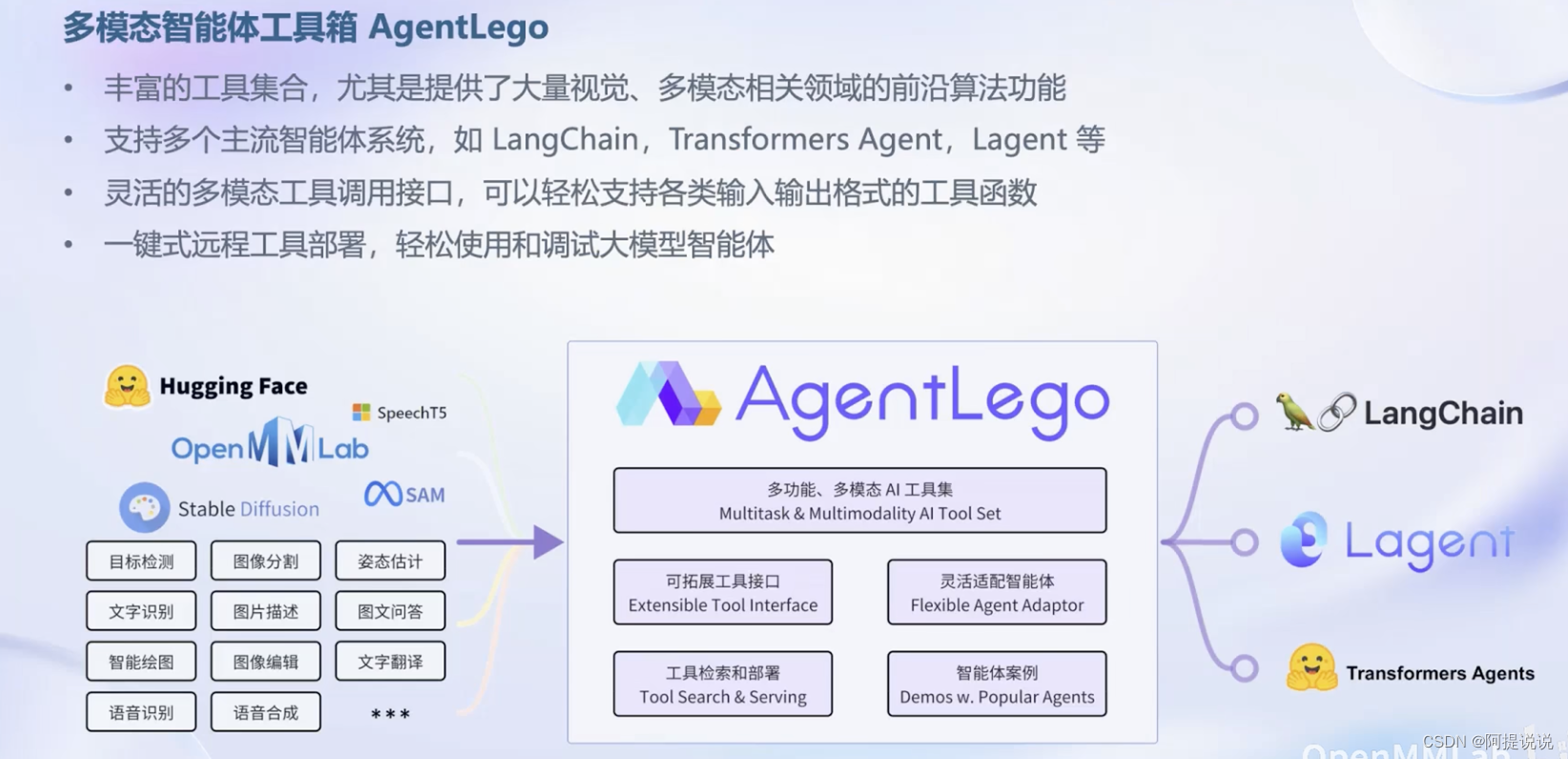
书生·浦语大模型全链路开源体系介绍
背景介绍
随着人工智能技术的迅猛发展,大模型技术已成为当今人工智能领域的热门话题。2022 年 11 月 30 日,美国 OpenAI 公司发布了 ChatGPT 通用型对话系统 并引发了全球 的极大关注,上线仅 60 天月活用户数便超过 1 亿,成为历史…
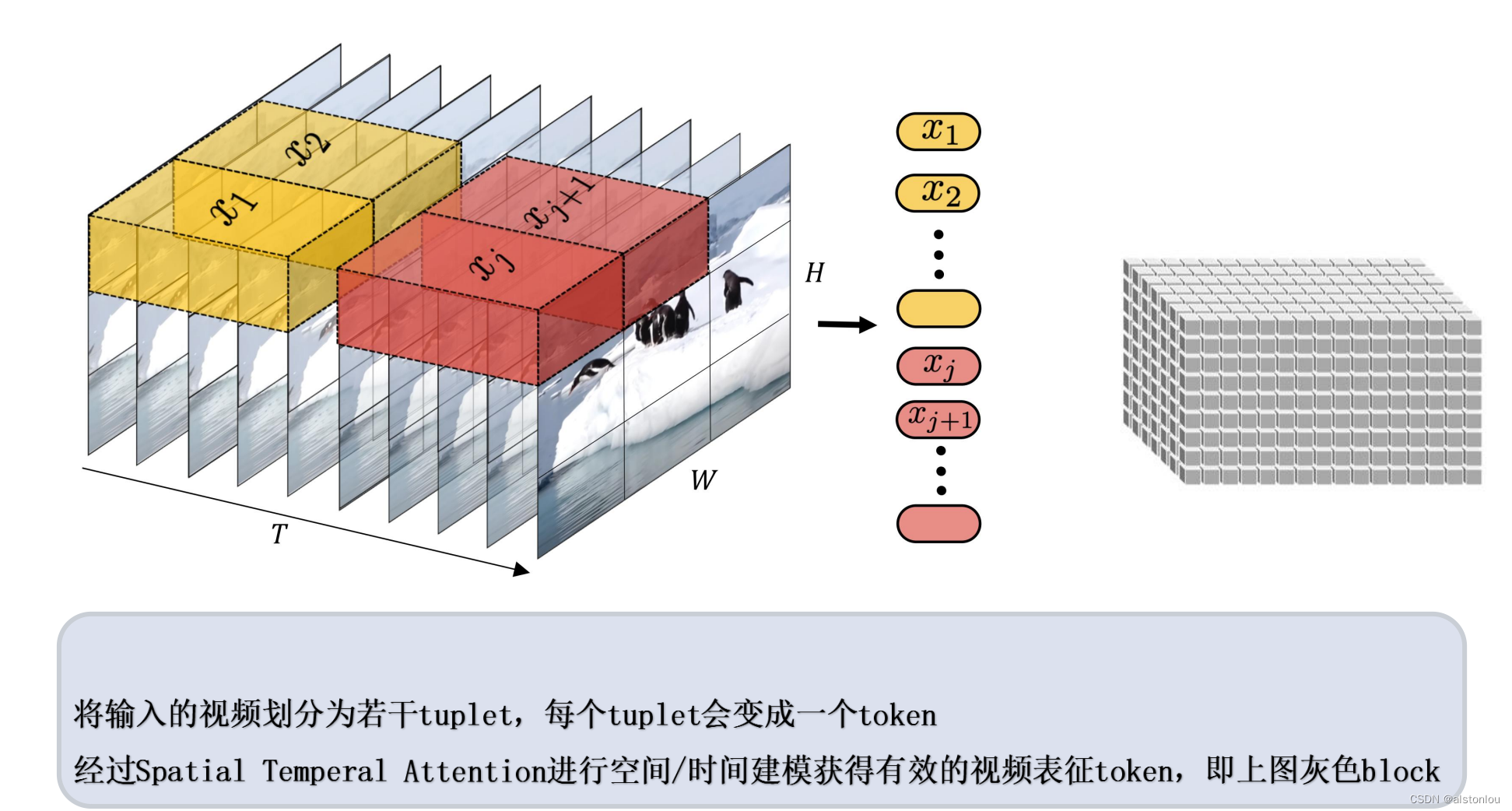
sora相关技术,看这一篇就够了
关于sora的技术,看这一篇就够了 文章目录 关于sora的技术,看这一篇就够了一、sora的横空出世二、sora的训练逻辑三、三大模块和patches3.1 VAE3.2 StableDiffusion3.3 Scaling Transformers3.4 patches模块 四、具体的工程难点参考 一、sora的横空出世
…

【文档智能 LLM】LayoutLLM:一种多模态文档布局模型和大模型结合的框架
前言
传统的文档理解任务,通常的做法是先经过预训练,然后微调相应的下游任务及数据集,如文档图像分类和信息提取等,通过结合图像、文本和布局结构的预训练知识来增强文档理解。LayoutLLM是一种结合了大模型和视觉文档理解技术的单…

2024年大模型面试准备(二):LLM容易被忽略的Tokenizer与Embedding
分词和嵌入一直是LM被忽略的一部分。随着各大框架如HF的不断完善,大家对tokenization和embedding的重视程度越来越低,到现在初学者大概只能停留在调用tokenizer.encode这样的程度了。
知其然不知其所以然是很危险的。比如你要调用ChatGPT的接口…
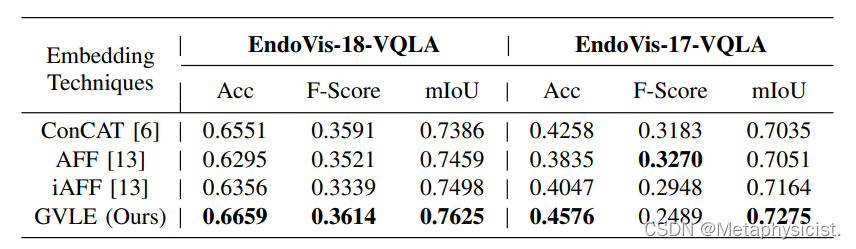
文献学习-22-Surgical-VQLA:具有门控视觉语言嵌入的转换器,用于机器人手术中的视觉问题本地化回答
Authors: Long Bai1† , Mobarakol Islam2† , Lalithkumar Seenivasan3 and Hongliang Ren1,3,4∗ , Senior Member, IEEE
Source: 2023 IEEE International Conference on Robotics and Automation (ICRA 2023) May 29 - June 2, 2023. London, UK Abstract:
尽管有计算机辅…

发展新质生产力,亚信科技切中产业痛点
管理学大师拉姆查兰认为,经营性不确定性通常在预知范围之内,不会对原有格局产生根本性影响;而结构性不确定性则源于外部环境的根本性变化,将彻底改变产业格局,带来根本性影响。
毫无疑问,一个充满结构性不…
![[医学分割大模型系列] (3) SAM-Med3D 分割大模型详解](https://img-blog.csdnimg.cn/direct/0c0f3f00b6de497390ec1ee4a2d8b1d2.png)
[医学分割大模型系列] (3) SAM-Med3D 分割大模型详解
[医学分割大模型系列] -3- SAM-Med3D 分割大模型解析 1. 特点2. 背景3. 训练数据集3.1 数据集收集3.2 数据清洗3.3 模型微调数据集 4. 模型结构4.1 3D Image Encoder4.2 3D Prompt Encoder4.3 3D mask Decoder4.4 模型权重 5. 评估5.1 评估数据集5.2 Quantitative Evaluation5.…

使用llamafile 构建本地大模型运用
安装
https://github.com/Mozilla-Ocho/llamafile
下载
大模型文件,选择列表中任意一个
wget https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llava-v1.5-7b-q4.llamafile?downloadtrue
https://github.com/Mozilla-Ocho/llamafile?tabre…
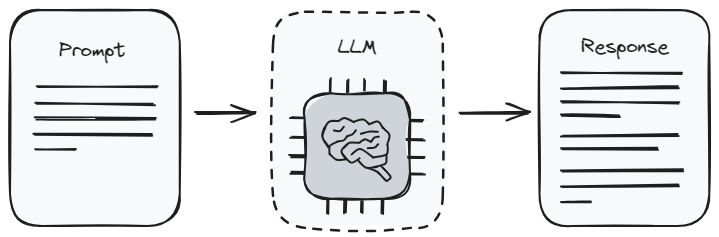
『大模型笔记』提示工程、微调和RAG之间对比
提示工程、微调和RAG之间对比 文章目录 一. 提示工程、微调和RAG之间对比二. 参考文章文章:Prompt Engineering vs Finetuning vs RAG一. 提示工程、微调和RAG之间对比 Prompt EngineeringFinetuning

『大模型笔记』Sora:探索大型视觉模型的前世今生、技术内核及未来趋势
Sora:探索大型视觉模型的前世今生、技术内核及未来趋势 文章目录 一. 摘要二. 引言杨立昆推荐的关于世界模型的真正含义(或应该是什么)的好文章。原文:Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models译文:Sora探索大型…

囊括所有大模型:高质量中文预训练模型大模型多模态模型大语言模型集合
在自然语言处理领域中,预训练语言模型(Pretrained Language Models)已成为非常重要的基础技术,本仓库主要收集目前网上公开的一些高质量中文预训练模型、中文多模态模型、中文大语言模型等内容(感谢分享资源的大佬),并…
文心一言、讯飞星火、GPT、通义千问等线上API调用示例
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。
大模型应用向开发路径及一点个人思考大模型应用开发实用开源项目汇总大模型问答项目…

多模态大模型:解析未来智能汽车的新引擎
多模态大模型:解析未来智能汽车的新引擎 1. 多模态大模型简介2. 多模态大模型在智能汽车中的应用2.1 感知与认知2.2 智能驾驶辅助2.3 智能交互 随着人工智能技术的不断进步,智能汽车已经从概念变成了现实,成为了当今科技领域的焦点之一。而在…
语音合成(TTS)开源调研与测评
2023年作为AI元年,各个领域的技术都有大规模的革新,语音领域的TTS(语音合成)也有很多新技术出现,比如Bert-Vits2、OpenVoice等等,都风靡一时。
笔者由于工作需要,近一个月在调研开源TTS,由于业务需要,主要看合成音频的效果(MOS)和合成速度(RTF)这两个指标,以及克…
使用1panel部署Ollama WebUI(dcoekr版)浅谈
文章目录 说明配置镜像加速Ollama WebUI容器部署Ollama WebUI使用问题解决:访问页面空白 说明
1Panel简化了docker的部署,提供了可视化的操作,但是我在尝试创建Ollama WebUI容器时,遇到了从github拉取镜像网速很慢的问题…
知乎:多云架构下大模型训练,如何保障存储稳定性?
知乎,中文互联网领域领先的问答社区和原创内容平台,2011 年 1 月正式上线,月活跃用户超过 1 亿。平台的搜索和推荐服务得益于先进的 AI 算法,数百名算法工程师基于数据平台和机器学习平台进行海量数据处理和算法训练任务。
为了提…
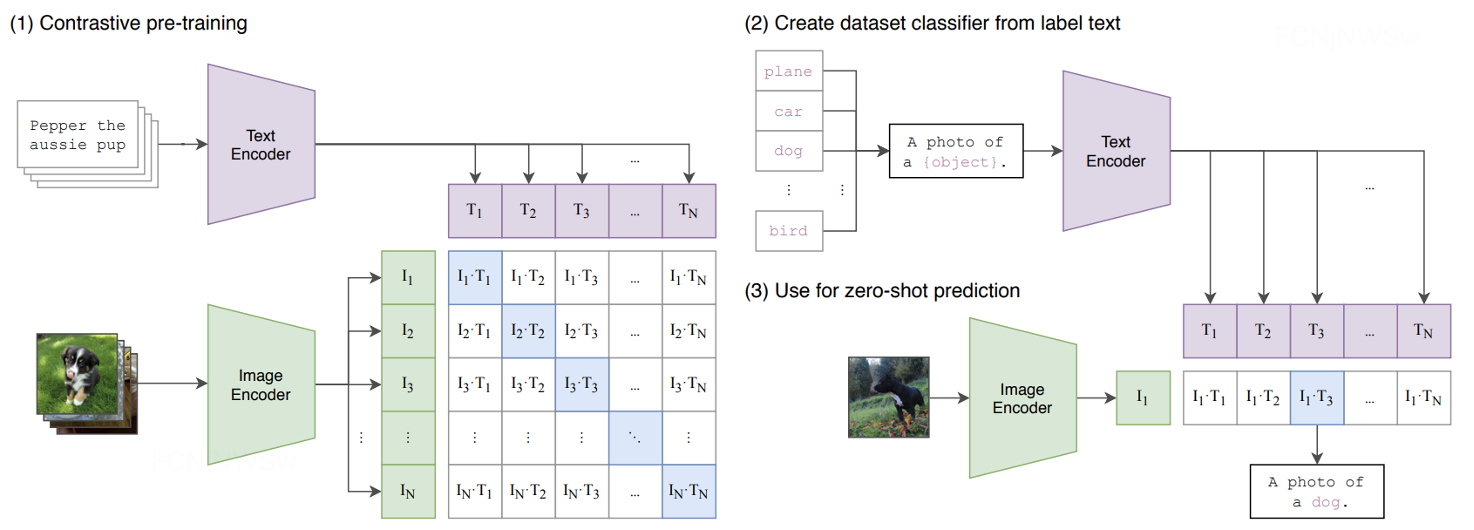
文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言
跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有: 文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等 图文匹配大模型:如CLIP、Chinese CLIP、…
240330-大模型资源-使用教程-部署方式-部分笔记
A. 大模型资源
Models - Hugging FaceHF-Mirror - Huggingface 镜像站模型库首页 魔搭社区 B. 使用教程
HuggingFace
HuggingFace 10分钟快速入门(一),利用Transformers,Pipeline探索AI。_哔哩哔哩_bilibiliHuggingFace快速入…

C#_事件_多线程(基础)
文章目录 事件通过事件使用委托 多线程(基础)进程:线程: 多线程线程生命周期主线程Thread 类中的属性和方法创建线程管理线程销毁线程 昨天习题答案 事件
事件(Event)本质上来讲是一种特殊的多播委托,只能从声明它的类中进行调用,基本上说是…

Sora:AI视频模型的无限可能与挑战
随着人工智能技术的突飞猛进,AI视频模型已成为科技领域的新焦点。OpenAI推出的AI视频模型Sora,凭借其卓越的技术性能和前瞻性,为AI视频领域的发展揭开了新的篇章。本文将从技术解析、应用场景、未来展望、伦理与创意以及用户体验与互动五个方…
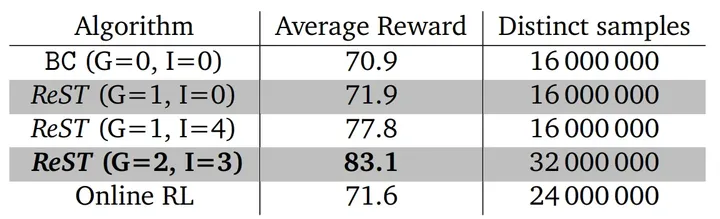
大模型RLHF算法更新换代,DeepMind提出自训练离线强化学习框架ReST
文章链接: https://arxiv.org/abs/2308.08998 大模型(LLMs)爆火的背后,离不开多种不同基础算法技术的支撑,例如基础语言架构Transformer、自回归语言建模、提示学习和指示学习等等。这些技术造就了像GPT-3、PaLM等基座…
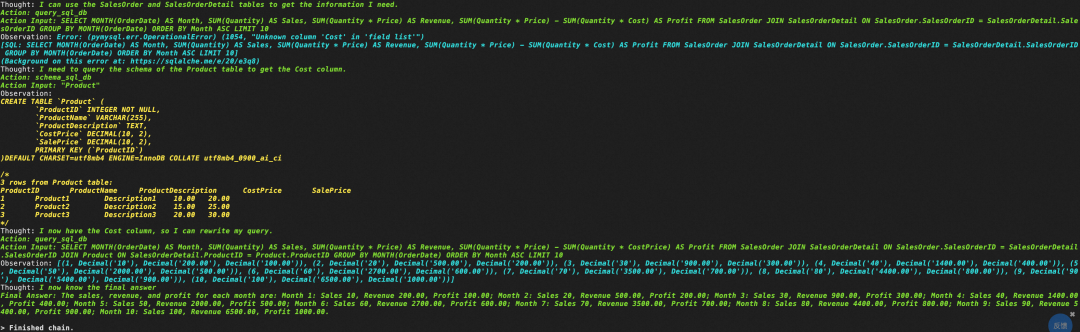
让老板成为数据分析师,我用 ChatGpt 链接本地数据源实战测试
本文探究 ChatGpt 等AI机器人能否帮助老板快速的做数据分析?用自然语言同老板进行沟通,满足老板的所有数据分析的诉求?
一、背景
设想这样一个场景:你是某贸易公司的老板,公司所有的日常运转数据都在私域的进销存系统…
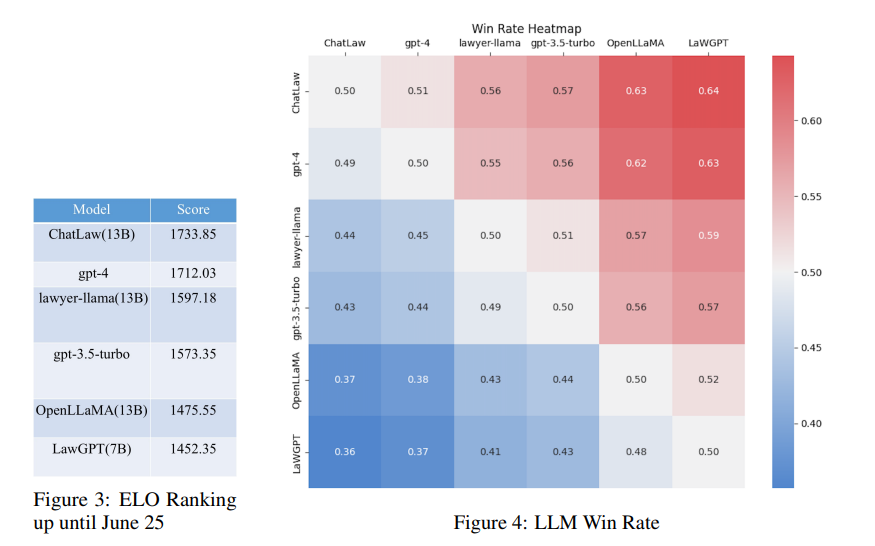
ChatLaw:基于LLaMA微调的法律大模型
文章目录 动机数据组成模型框架模型评估 北大团队发布首个的中文法律大模型落地产品ChatLaw,为大众提供普惠法律服务。模型支持文件、语音输出,同时支持法律文书写作、法律建议、法律援助推荐。 github地址:https://github.com/PKU-YuanGroup…
调用openai接口的正确打开方式
调用openai接口的正确打开方式:
1.安装anaconda
为更好使用openai的功能,技术专家建议用py3.10。我问chatgpt它说只要py3.6及以上就行。我个人建议尽可能用anaconda较新的,但用anaconda2022.10的版本即可,可适配python3.10或pyt…

大模型之PaLM2简介
1 缘起
大模型时代。 时刻关注大模型相关的研究与进展, 以及科技巨头的商业化大模型产品。 作为产品&技术普及类文章,本文将围绕PaLM2是什么、特点、如何使用展开。 想要了解更多信息的可以移步官方网站提供的参考文档,后文会给出相关链…
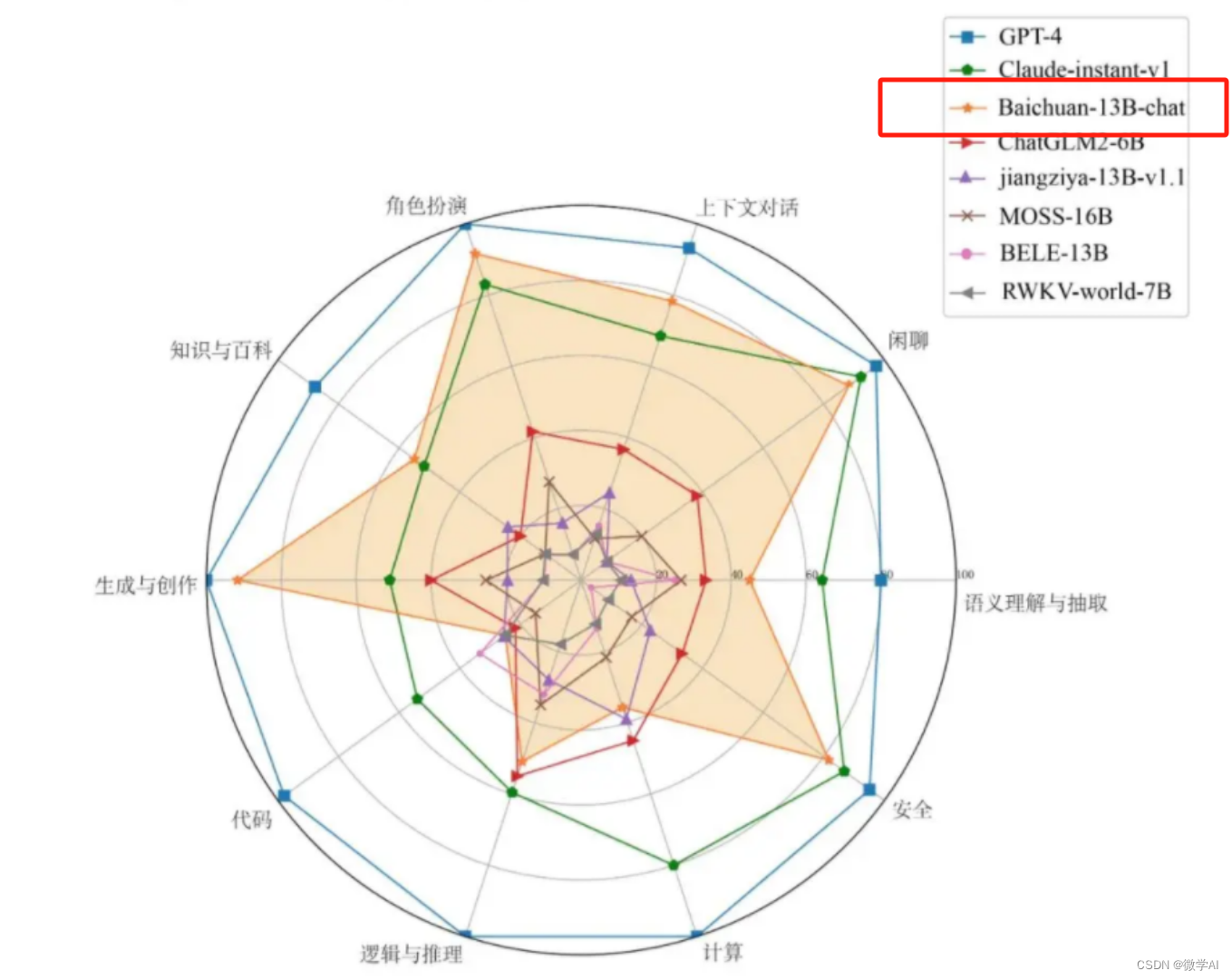
大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法。 Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均…
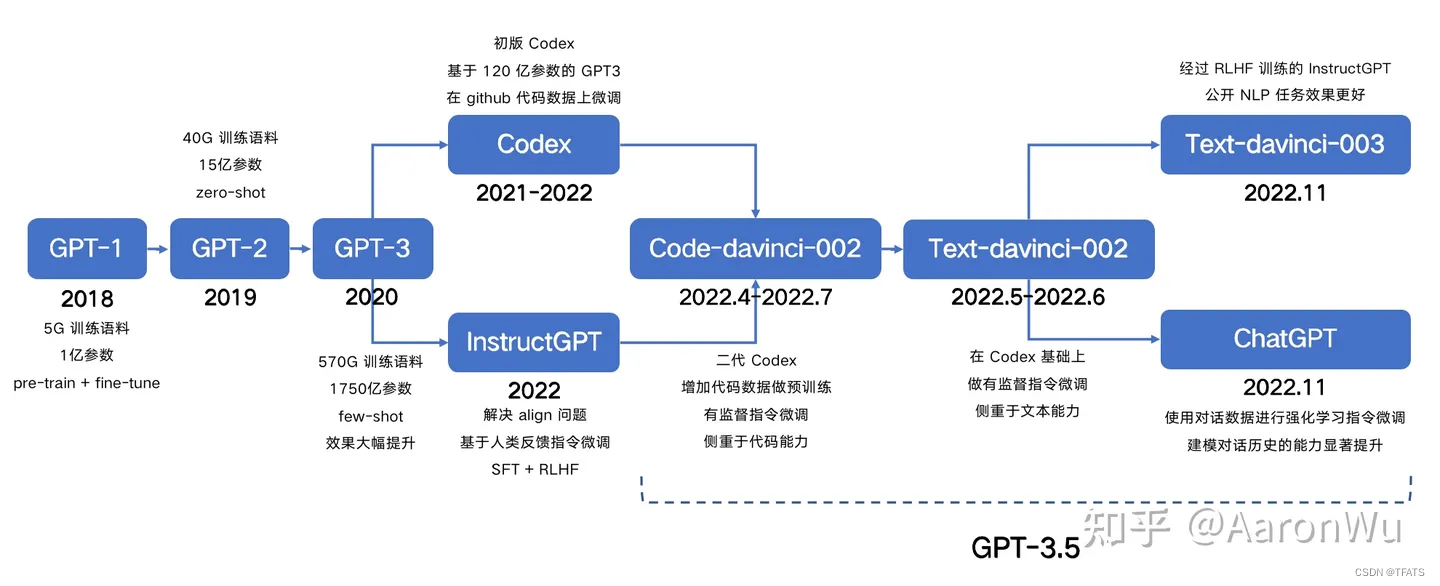
GPT,GPT-2,GPT-3,InstructGPT的进化之路
ChatGPT 火遍圈内外,突然之间,好多人开始想要了解 NLP 这个领域,想知道 ChatGPT 到底是个什么?作为在这个行业奋斗5年的从业者,真的很开心让人们知道有一群人在干着这么样的一件事情。这也是我结合各位大佬的文章&…
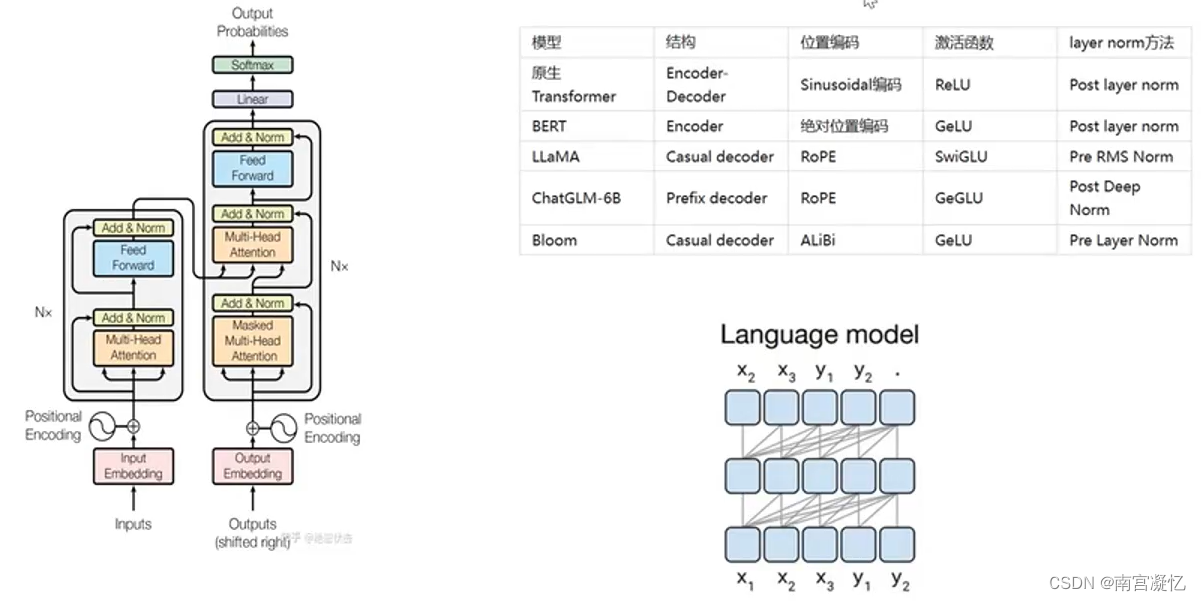
羊驼系列大模型LLaMa、Alpaca、Vicuna
羊驼系列大模型:大模型的安卓系统
GPT系列:类比ios系统,不开源
LLaMa让大模型平民化
LLaMa优势
用到的数据:大部分英语、西班牙语,少中文 模型下载地址
https://huggingface.co/meta-llama Alpaca模型
Alpaca是斯…

【DDPM论文解读】Denoising Diffusion Probabilistic Models
0 摘要
本文使用扩散概率模型合成了高质量的图像结果,扩散概率模型是一类受非平衡热力学启发的潜变量模型。本文最佳结果是通过根据扩散概率模型和朗之万动力学的去噪分数匹配之间的新颖联系设计的加权变分界进行训练来获得的,并且本文的模型自然地承认…
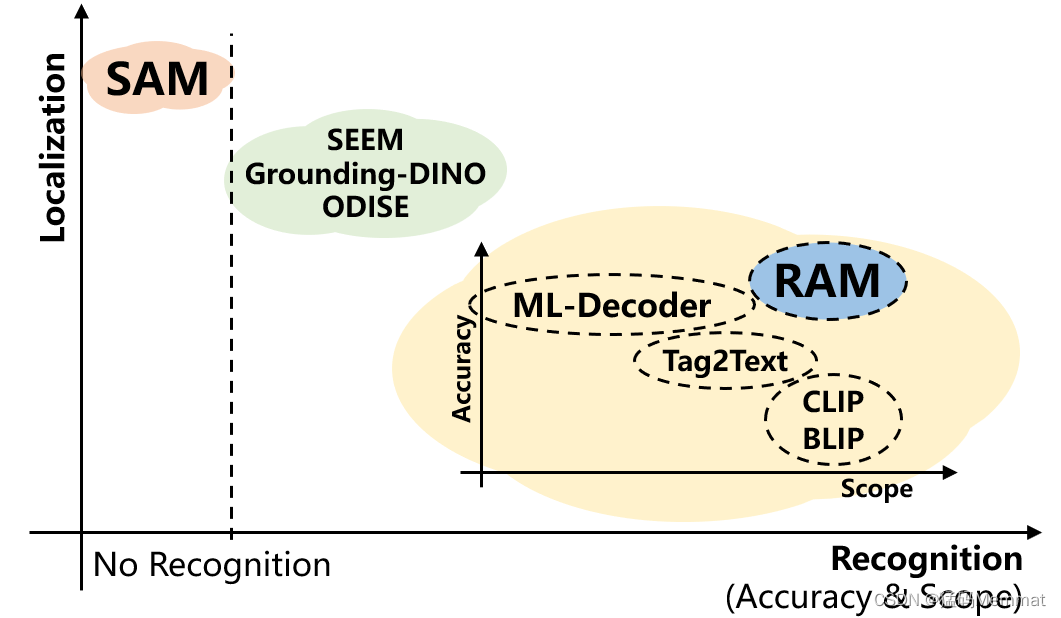
万物识别RAM:图像识别模型,Zero-Shot超越有监督
文章目录 RAM的优势RAM的创新点总结与展望参考文献大语言模型(Large Language Models)已经给自然语言处理(NLP)领域带来了新的革命。在计算机视觉(CV)领域,Facebook近期推出的Segment Anything Model(SAM)工作,在视觉定位(Localization)任务上取得了令人振奋的结果…
获得了谷歌gemini 1.5 pro的内测资格,来一波测评
谷歌目前最强的大模型Gemini 1.5 Pro。最高可以支持百万级别的token。在百万级token上下文的加持下,可以更加轻易地与数十万字的超长文档、拥有数百个文件的数十万行代码库、一部完整的电影等等进行交互。
目前Gemini 1.5 Pro只是内测阶段,我申请了内测…
LLM--打造Private GPT需要知道的一些概念及术语
文章目录 大模型存储格式GGMLGGUF Embedding概念分类 术语LlamaindexLlamaCPPPoetryASGIFastAPIChromaQdrantgradioMRL 大模型存储格式
大模型的存储一个很重要的问题是它的模型文件巨大,而模型的结构、参数等也会影响模型的推理效果和性能,为了让大模型…

BabyAGI(4)-babycoder第一部分,配置项和agent tools函数
babyCoder是一个工作在AI系统的上的工具,它可以根据一些简单的目标写一些短的代码。作为babyagi的一部分,babycoder的目标是为越来越厉害的人工智能agent打下基础,能够生成更大、更复杂的项目。 babycoder主要的目的是为编写代码和修改的代码…
『大模型笔记』大模型微调(Fine-Tuning)还有价值吗?
大模型微调(Fine-Tuning)还有价值吗? 文章目录 一. 大模型微调(Fine-Tuning)还有价值吗?二. 总结三. 参考文献对最近微调幻灭趋势的反应。一. 大模型微调(Fine-Tuning)还有价值吗? 我深入研究后发现,微调技术在众多场景下仍然极具价值。通常认为微调无益的人,往往是那些在…

Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据?
Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据? 文章来自Meta AI,self-Alignment with Instruction Backtranslation[1]:通过指令反向翻译进行自对准。 一种从互联网大量无标签数据中挖掘高质量的指令遵循数据…

文生视频大模型Sora的复现经验
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…
langchin-chatchat部分开发笔记(持续更新)
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。
大模型应用向开发路径及一点个人思考大模型应用开发实用开源项目汇总大模型问答项目…
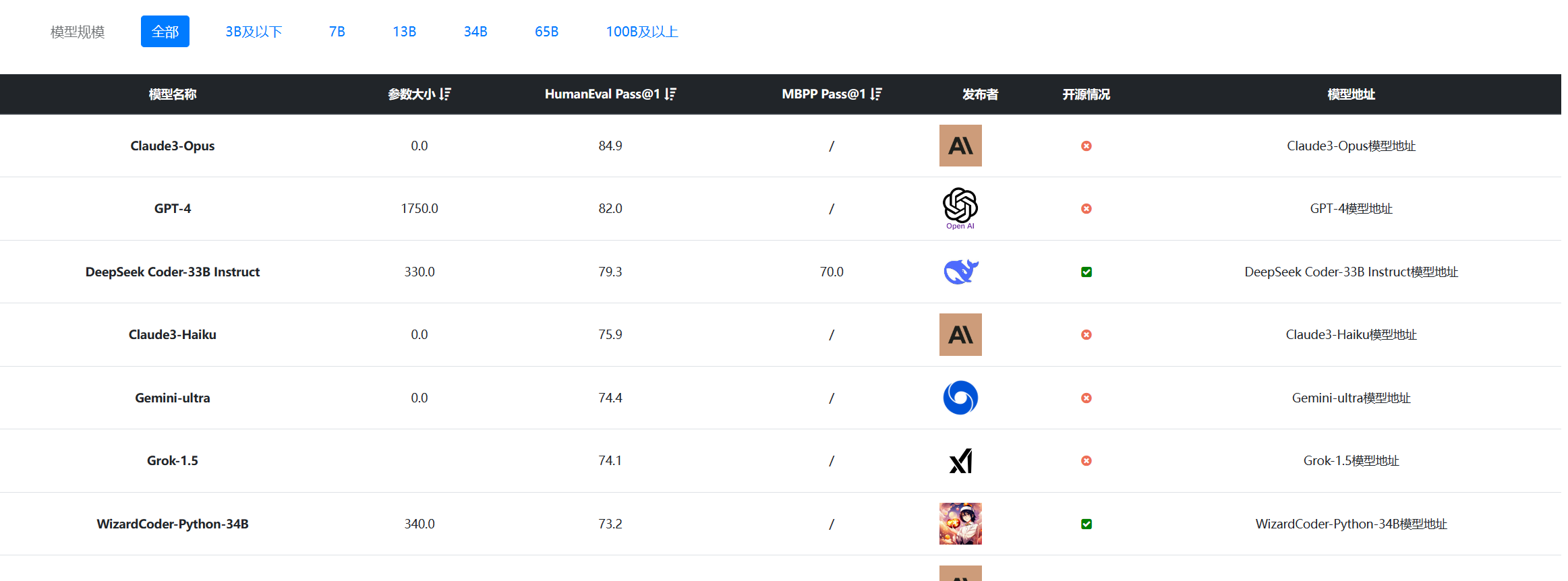
马斯克旗下xAI发布Grok-1.5,相比较开源的Grok-1,各项性能大幅提升,接近GPT-4!
本文原文来自DataLearnerAI官方网站:马斯克旗下xAI发布Grok-1.5,相比较开源的Grok-1,各项性能大幅提升,接近GPT-4! | 数据学习者官方网站(Datalearner)
继Grok-1开源之后,xAI宣布了Grok-1.5的内测消息&…
chatui工具使用记录与比较
概述
cahtui相关工具可谓是层出不穷,方便了我们使用各个大模型。这里我把我知道的整理下列出来,顺便做一比较。
简单比较
openWebUI,star 11.1k,仿chatgpt风格,支持openapi、可以对接Ollama进行对话,功能…
『大模型笔记』吴恩达:AI 智能体工作流引领人工智能新趋势
吴恩达:AI 智能体工作流引领人工智能新趋势 文章目录 一. 概述二. AI 智能体的设计模式2.1. 反思(Reflection)2.2. 使用工具(Tool use)2.3. 规划(Planning)2.4. 多智能体协作(Multi-agent collaboration)三. 最后总结四. 参考文献一. 概述 我期待与大家分享我在 AI 智能体方面…

Talk| 卡耐基梅隆大学博士生徐梦迪:可泛化机器人学习-如何让机器人创造性地使用工具
本期为TechBeat人工智能社区第542期线上Talk! 北京时间11月01日(周三)20:00,卡耐基梅隆大学博士生—徐梦迪的Talk已准时在TechBeat人工智能社区开播! 她与大家分享的主题是: “可泛化机器人学习-如何让机器人创造性地使用工具”,她…